
y la era de la IA ha llegado silenciosamente.
Probablemente nadie esperaba que este Año Nuevo Chino, el tema más candente ya no sería la tradicional batalla del sobre rojo de Internet, que se asoció con la Gala de la Fiesta de la Primavera, sino las empresas de IA.
A medida que se acercaba el Festival de Primavera, las principales empresas de modelos no se relajaron en absoluto, actualizando una oleada de modelos y productos. Sin embargo, de lo que más se habló fue de DeepSeek, una "gran empresa de modelos" surgida el año pasado.
En la tarde del 20 de enero, ProfundoSeek publicó la versión oficial de su modelo de razonamiento DeepSeek-R1. Utilizando un bajo coste de formación, entrenó directamente un rendimiento que no es inferior al modelo de razonamiento de OpenAI o1. Además, es completamente gratuito y de código abierto, lo que provocó directamente un terremoto en la industria.
Es la primera vez que una IA doméstica causa revuelo en el mundo de la tecnología a gran escala en todo el mundo, especialmente en Estados Unidos. Los desarrolladores han expresado que están considerando usar DeepSeek para "reconstruirlo todo". A raíz de esta oleada, tras una semana de fermentación, e incluso recién lanzada en enero, la aplicación móvil DeepSeek alcanzó rápidamente el primer puesto en la clasificación de aplicaciones gratuitas de la App Store de Apple en Estados Unidos, superando no sólo a ChatGPT, sino también a otras aplicaciones populares en ese país.
El éxito de DeepSeek ha afectado incluso directamente al mercado bursátil estadounidense. Un modelo entrenado sin utilizar una enorme cantidad de costosas GPU ha hecho que la gente se replantee el camino de entrenamiento de la IA, provocando directamente la mayor caída de 17% en la primera acción de la IA, NVIDIA.
Y eso no es todo.
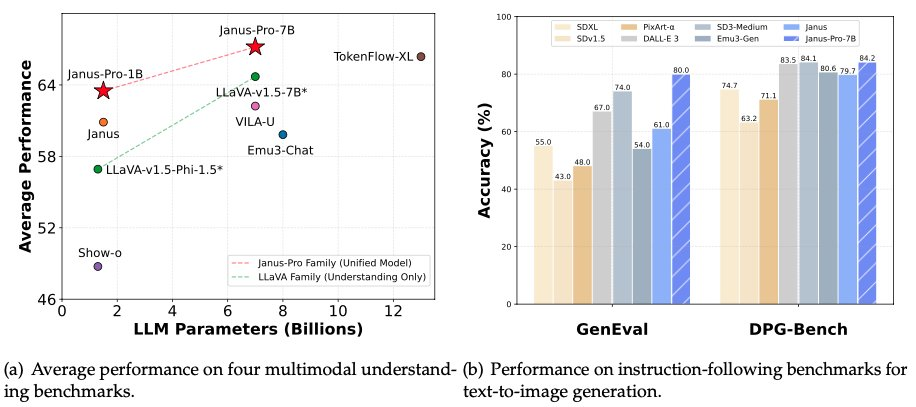
En la madrugada del 28 de enero, la víspera de Nochevieja, DeepSeek volvió a abrir el código de su modelo multimodal Janus-Pro-7B, anunciando que había derrotado a DALL-E 3 (de OpenAI) y a Stable Diffusion en las pruebas de referencia GenEval y DPG-Bench.
¿De verdad va a arrasar DeepSeek en la comunidad de la IA? De los modelos de inferencia a los modelos multimodales, ¿está DeepSeek reestructurando todo el primer tema del Año de la Serpiente?
Janus Prola validación de una arquitectura de modelo multimodal innovadora
DeepSeek publicó esta vez a última hora de la noche un total de dos modelos: Janus-Pro-7B y Janus-Pro-1B (parámetros de 1,5B).
Como su nombre indica, el modelo en sí es una actualización del modelo Janus anterior.
DeepSeek lanzó por primera vez el modelo Janus en octubre de 2024. Como es habitual en DeepSeek, el modelo adopta una arquitectura innovadora. En muchos modelos de generación de visión, el modelo adopta una arquitectura Transformer unificada que puede procesar simultáneamente las tareas de texto a imagen e imagen a texto.
DeepSeek propone una nueva idea, desacoplar la codificación visual de las tareas de comprensión (gráfico a texto) y generación (texto a gráfico), lo que mejora la flexibilidad del entrenamiento del modelo y alivia eficazmente los conflictos y los cuellos de botella de rendimiento causados por el uso de una única codificación visual.
Por eso DeepSeek bautizó el modelo con el nombre de Jano. Jano es el antiguo dios romano de las puertas y se representa con dos caras orientadas en direcciones opuestas. DeepSeek dice que el modelo se llama Janus porque puede mirar datos visuales con ojos diferentes, codificar características por separado y luego utilizar el mismo cuerpo (Transformer) para procesar estas señales de entrada.
Esta nueva idea ha dado buenos resultados en la serie de modelos Janus. El equipo afirma que el modelo Janus tiene una gran capacidad para seguir órdenes, es multilingüe y es más inteligente, capaz de leer imágenes de memes. También puede encargarse de tareas como la conversión de fórmulas de látex y la conversión de gráficos a código.
En la serie de modelos Janus Pro, el equipo ha modificado parcialmente el proceso de entrenamiento del modelo, lo que ha permitido obtener directamente resultados que superan a DALL-E 3 y Stable Diffusion en las pruebas de referencia GenEval y DPG-Bench.
Junto con el propio modelo, DeepSeek también ha lanzado el nuevo marco de IA multimodal Janus Flow, cuyo objetivo es unificar las tareas de comprensión y generación de imágenes.
El modelo Janus Pro puede proporcionar resultados más estables con indicaciones breves, con mejor calidad visual, más riqueza de detalles y capacidad para generar textos sencillos.
El modelo puede generar imágenes y describir fotografías, identificar lugares de interés (como el Lago del Oeste de Hangzhou), reconocer texto en imágenes y describir conocimientos en imágenes (como las tartas de "Tom y Jerry").
One x.com, Muchas personas ya han empezado a experimentar con el nuevo modelo.

La prueba de reconocimiento de imágenes se muestra a la izquierda en la figura anterior, mientras que la prueba de generación de imágenes se muestra a la derecha.

Como puede verse, Janus Pro también realiza un buen trabajo de lectura de imágenes con gran precisión. Puede reconocer tipografías mixtas de expresiones matemáticas y texto. En el futuro, puede ser más importante utilizarlo con un modelo de razonamiento.
Los parámetros de 1B y 7B pueden desbloquear nuevos escenarios de aplicación
En tareas de comprensión multimodal, el nuevo modelo Janus-Pro utiliza SigLIP-L como codificador visual y admite entradas de imagen de 384 x 384 píxeles. En las tareas de generación de imágenes, Janus-Pro utiliza un tokenizador de una fuente específica con una tasa de reducción de muestreo de 16.
Sigue siendo un tamaño de imagen relativamente pequeño. X En el análisis del usuario, el modelo Janus Pro es más bien una verificación direccional. Si la verificación es fiable, se lanzará un modelo que pueda ponerse en producción.
Sin embargo, cabe destacar que el nuevo modelo lanzado por Janus en esta ocasión no sólo es innovador desde el punto de vista arquitectónico para los modelos multimodales, sino que también supone una nueva exploración en cuanto al número de parámetros.
El modelo comparado por DeepSeek Janus Pro en esta ocasión, DALL-E 3, anunció anteriormente que tenía 12.000 millones de parámetros, mientras que el modelo de gran tamaño de Janus Pro sólo tiene 7.000 millones de parámetros. Con un tamaño tan compacto, ya es muy bueno que Janus Pro pueda lograr tales resultados.
En concreto, el modelo 1B de Janus Pro sólo utiliza 1.500 millones de parámetros. Los usuarios ya han añadido soporte para el modelo a transformers.js en la red externa. ¡Esto significa que el modelo ahora puede ejecutar 100% en navegadores en WebGPU!
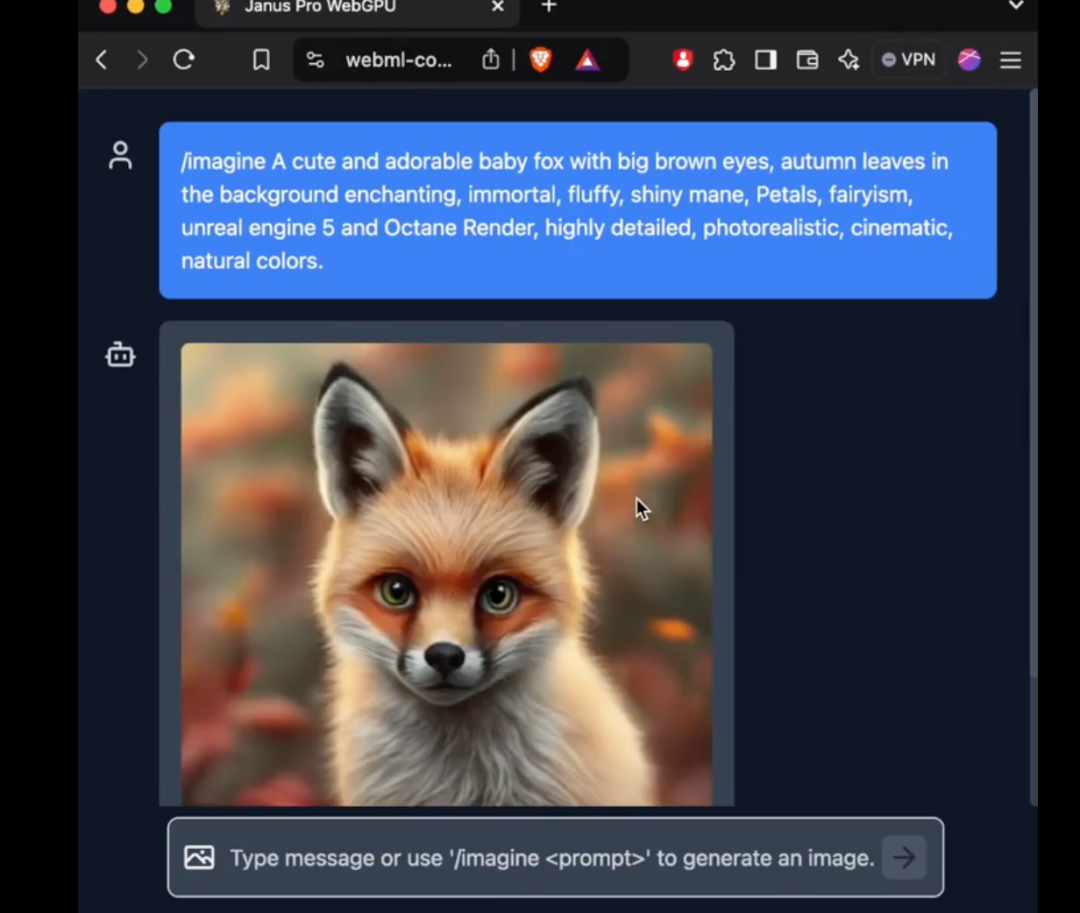
Aunque al cierre de esta edición el autor aún no había podido utilizar con éxito el nuevo modelo de Janus Pro en la versión web, el hecho de que el número de parámetros sea lo suficientemente pequeño como para ejecutarlo directamente en la web sigue siendo una mejora asombrosa.
Esto significa que el coste de la generación y comprensión de imágenes sigue disminuyendo. Tenemos la oportunidad de ver el uso de la IA en más lugares en los que antes no se podían utilizar las imágenes en bruto y la comprensión de imágenes, lo que cambiará nuestras vidas.
Uno de los principales puntos calientes en 2024 es cómo puede intervenir en nuestras vidas el hardware de IA con comprensión multimodal añadida. Los modelos de comprensión multimodal con parámetros cada vez más bajos, o los modelos que se puede esperar que funcionen al límite, pueden permitir que el hardware de IA siga explotando.
DeepSeek ha agitado el nuevo año. Se puede rehacer todo con la IA china?
El mundo de la IA cambia día a día.
En torno al Festival de Primavera del año pasado, lo que conmovió al mundo fue el modelo Sora de OpenAI. Sin embargo, a lo largo del año, las empresas chinas se han puesto completamente al día en lo que a generación de vídeo se refiere, por lo que el lanzamiento de Sora a finales de año se antoja poco prometedor.
Este año, lo que ha conmovido al mundo ha sido el DeepSeek chino.
DeepSeek no es una empresa de tecnología tradicional, pero ha fabricado modelos extremadamente innovadores a un coste muy inferior al de las tarjetas GPU de las grandes empresas de modelos estadounidenses, lo que ha escandalizado directamente a sus homólogos norteamericanos. Los estadounidenses han exclamado: "La formación del modelo R1 sólo costó 5,6 millones de dólares estadounidenses, lo que equivale incluso al salario de cualquier ejecutivo del equipo Meta GenAI. ¿Qué es este misterioso poder oriental?".
Una cuenta parodia que imita al fundador de DeepSeek, Liang Wenfeng, publicó una interesante imagen directamente en X:

La imagen utilizaba el meme trending del mundialmente famoso tirador turco en 2024.
En la final de pistola de aire comprimido de 10 metros de las pruebas de tiro de los Juegos Olímpicos de París, el tirador turco Mithat Dikec, de 51 años, que sólo llevaba unas gafas de miope normales y unos tapones para dormir, se embolsó tranquilamente la medalla de plata con una sola mano en el bolsillo. Todos los demás tiradores presentes necesitaron dos lentes profesionales para enfocar y bloquear la luz y un par de tapones antirruido para los oídos para empezar la competición.
Desde que DeepSeek "crackeó" Modelo de razonamiento de OpenAIEn los últimos años, las principales empresas tecnológicas de EE.UU. se han visto sometidas a una intensa presión. Hoy, Sam Altman ha respondido finalmente con un comunicado oficial.

¿Será 2025 el año en que la IA china afecte a la percepción de los estadounidenses?
DeepSeek aún guarda algunos secretos en la manga: está llamado a ser un extraordinario Festival de Primavera.



