En vísperas del Festival de Primavera, se lanzó el modelo DeepSeek-R1. Con su arquitectura RL pura, ha aprendido de las grandes innovaciones de CoT, y supera a ChatGPT en matemáticas, código y razonamiento lógico.
Además, los pesos de sus modelos de código abierto, los bajos costes de formación y el bajo precio de sus API han hecho de DeepSeek un éxito en Internet, provocando incluso el desplome de las cotizaciones bursátiles de NVIDIA y ASML durante un tiempo.
Al tiempo que se disparaba su popularidad, DeepSeek también lanzó una versión actualizada del gran modelo multimodal Janus (Janus), Janus-Pro, que hereda la arquitectura unificada de la generación anterior de comprensión y generación multimodal, y optimiza la estrategia de entrenamiento, escalando los datos de entrenamiento y el tamaño del modelo, lo que aporta un mayor rendimiento.

Janus-Pro
Janus-Pro es un modelo de lenguaje multimodal unificado (MLLM) que puede procesar simultáneamente tareas de comprensión multimodal y tareas de generación, es decir, puede comprender el contenido de una imagen y también generar texto.
Desacopla los codificadores visuales para la comprensión y generación multimodal (es decir, se utilizan diferentes tokenizadores para la entrada de la comprensión de imágenes y la entrada y salida de la generación de imágenes), y los procesa utilizando un transformador autorregresivo unificado.
Como modelo avanzado de comprensión y generación multimodal, es una versión mejorada del anterior modelo Janus.
En la mitología romana, Jano es un dios guardián de dos caras que simboliza la contradicción y la transición. Tiene dos caras, lo que también sugiere que el modelo Janus puede entender y generar imágenes, lo que resulta muy apropiado. Entonces, ¿qué es exactamente lo que ha actualizado PRO?
Janus, como pequeño modelo de 1.3B, se parece más a una versión preliminar que a una versión oficial. Explora la comprensión y generación multimodal unificada, pero tiene muchos problemas, como efectos de generación de imágenes inestables, grandes desviaciones respecto a las instrucciones del usuario y detalles inadecuados.
La versión Pro optimiza la estrategia de entrenamiento, aumenta el conjunto de datos de entrenamiento y proporciona un modelo más grande (7B) para elegir, al tiempo que proporciona un modelo 1B.
Arquitectura modelo
Jaus-Pro y Janus son idénticos en cuanto a la arquitectura del modelo. (¡Sólo 1,3B! Janus unifica la comprensión y la generación multimodal).
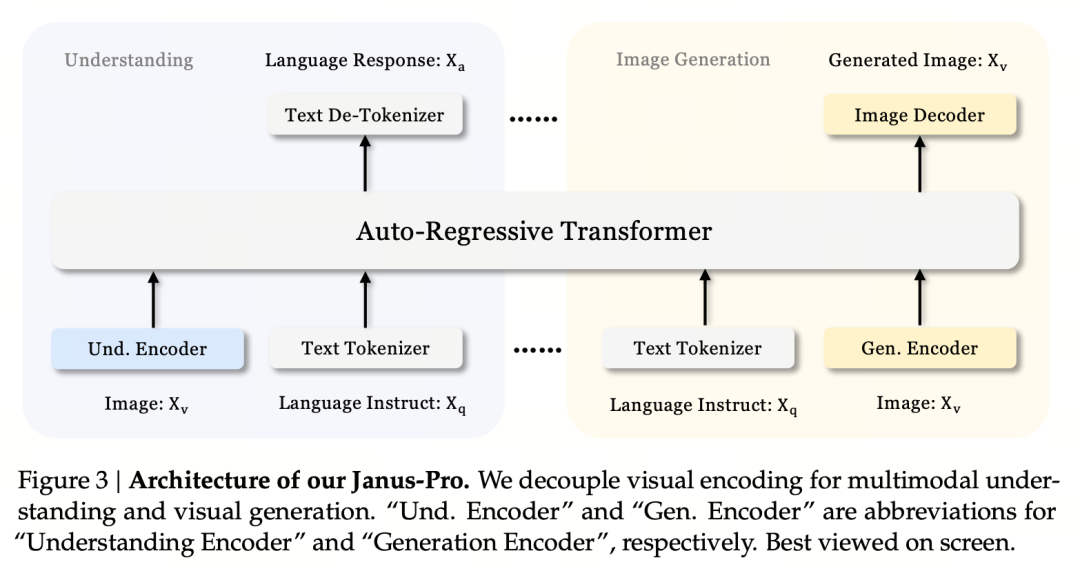
El principio básico del diseño es desacoplar la codificación visual para facilitar la comprensión y la generación multimodales. Janus-Pro codifica la imagen/texto original por separado, extrae características de alta dimensión y las procesa mediante un transformador autorregresivo unificado.
La comprensión de imágenes multimodales utiliza SigLIP para codificar las características de la imagen (codificador azul en la figura anterior), y la tarea de generación utiliza el tokenizador VQ para discretizar la imagen (codificador amarillo en la figura anterior). Por último, todas las secuencias de características se introducen en el LLM para su procesamiento.
Estrategia de formación
En cuanto a la estrategia de entrenamiento, Janus-Pro ha introducido más mejoras. La antigua versión de Janus utilizaba una estrategia de entrenamiento en tres etapas, en la que la Etapa I entrena el adaptador de entrada y el cabezal de generación de imágenes para la comprensión y generación de imágenes, la Etapa II realiza un pre-entrenamiento unificado, y la Etapa III afina el codificador de comprensión sobre esta base. (La estrategia de entrenamiento de Janus se muestra en la siguiente figura).
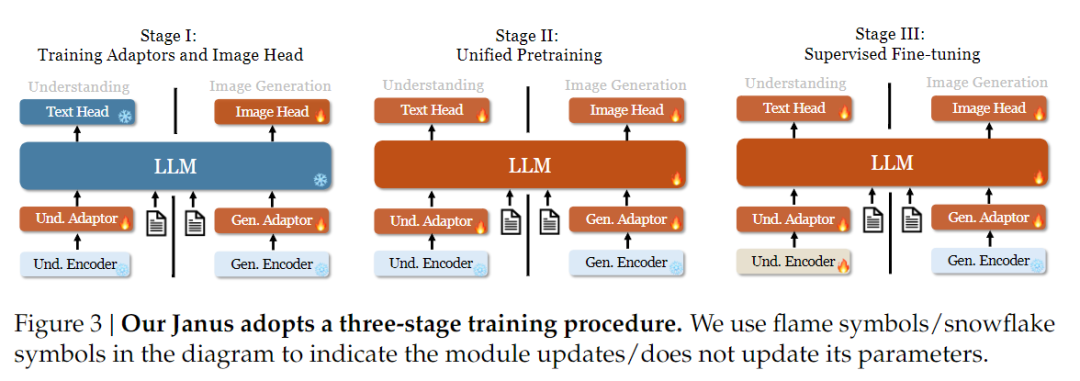
Sin embargo, esta estrategia utiliza el método PixArt para dividir el entrenamiento de generación de texto a imagen en la Etapa II, lo que se traduce en una baja eficiencia computacional.
Para ello, ampliamos el tiempo de entrenamiento de la Etapa I y añadimos el entrenamiento con datos de ImageNet, de modo que el modelo pueda modelar eficazmente las dependencias de los píxeles con parámetros LLM fijos. En la Etapa II, descartamos los datos de ImageNet y utilizamos directamente datos de pares texto-imagen para entrenar, lo que mejora la eficiencia del entrenamiento. Además, ajustamos la proporción de datos en la Etapa III (datos multimodales:sólo texto:gráficos visuales-semánticos de 7:3:10 a 5:1:4), mejorando la comprensión multimodal y manteniendo al mismo tiempo la capacidad de generación visual.
Escalado de datos de entrenamiento
Janus-Pro también escala los datos de entrenamiento de Janus en términos de comprensión multimodal y generación visual.
Comprensión multimodal: Los datos de preentrenamiento de la Etapa II se basan en DeepSeek-VL2 e incluyen unos 90 millones de muestras nuevas, incluidos datos de pies de imágenes (como YFCC) y datos de comprensión de tablas, gráficos y documentos (como Docmatix).
La fase III de ajuste fino supervisado introduce además la comprensión MEME, datos de diálogos chinos, etc., para mejorar el rendimiento del modelo en el procesamiento multitarea y las capacidades de diálogo.
Generación visual: Las versiones anteriores utilizaban datos reales de baja calidad y mucho ruido, lo que afectaba a la estabilidad y la estética de las imágenes generadas por texto.
Janus-Pro introduce unos 72 millones de datos estéticos sintéticos, con lo que la proporción entre datos reales y sintéticos es de 1:1. Los experimentos han demostrado que los datos sintéticos aceleran la convergencia del modelo y mejoran significativamente la estabilidad y la calidad estética de las imágenes generadas.
Escalado de modelos
Janus Pro amplía el tamaño del modelo a 7B, mientras que la versión anterior de Janus utilizaba 1,5B DeepSeek-LLM para verificar la eficacia del desacoplamiento de la codificación visual. Los experimentos muestran que un LLM más grande acelera significativamente la convergencia de la comprensión multimodal y la generación visual, lo que verifica aún más la fuerte escalabilidad del método.

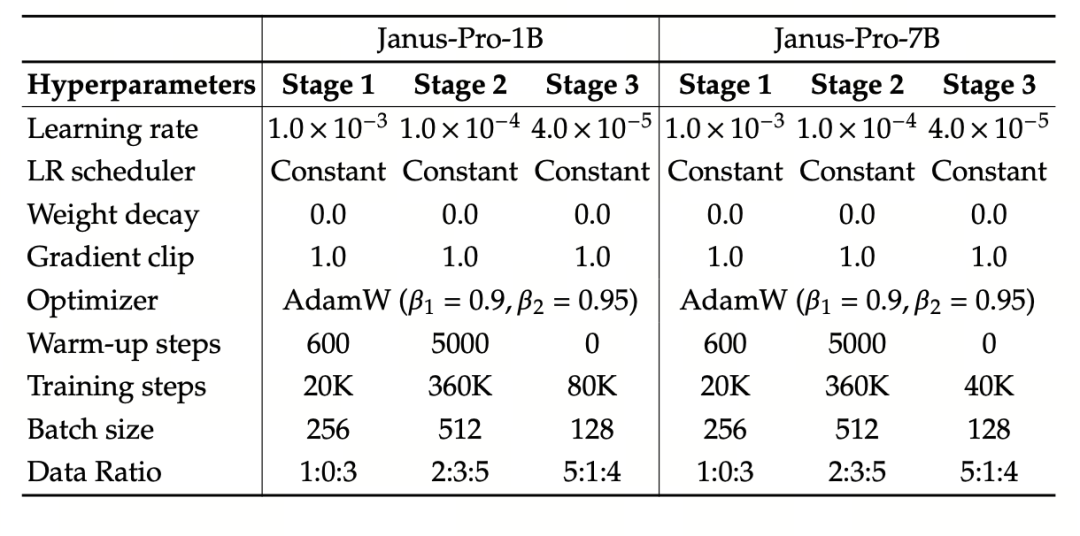
El experimento utiliza DeepSeek-LLM (1,5B y 7B, soportando una secuencia máxima de 4096) como modelo lingüístico básico. Para la tarea de comprensión multimodal, se utiliza SigLIP-Large-Patch16-384 como codificador visual, el tamaño del diccionario del codificador es 16384, el múltiplo de reducción de muestreo de la imagen es 16, y tanto el adaptador de comprensión como el de generación son MLP de dos capas.
El entrenamiento de la fase II utiliza una estrategia de parada temprana de 270K, todas las imágenes se ajustan uniformemente a una resolución de 384×384 y se utiliza el empaquetado de secuencias para mejorar la eficiencia del entrenamiento . Janus-Pro se entrena y evalúa con HAI-LLM. Las versiones 1.5B/7B se entrenaron en 16/32 nodos (8×Nvidia A100 40GB por nodo) durante 9/14 días respectivamente.
Evaluación de modelos
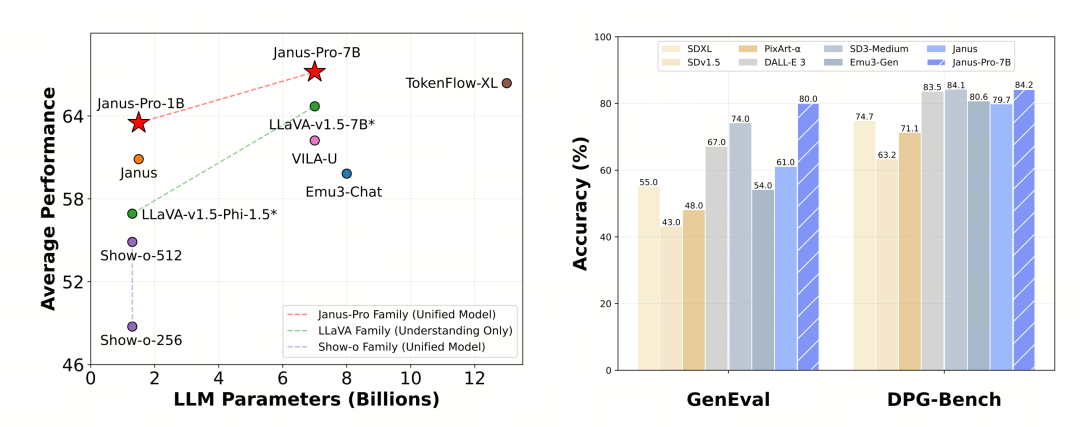
Janus-Pro se evaluó por separado en comprensión y generación multimodal. En general, la comprensión puede ser ligeramente débil, pero se considera excelente entre los modelos de código abierto del mismo tamaño (supongo que está limitada en gran medida por la resolución de entrada fija y las capacidades de OCR).
Janus-Pro-7B obtuvo una puntuación de 79,2 en la prueba comparativa MMBench, que se acerca al nivel de los modelos de código abierto de primer nivel (el mismo tamaño de InternVL2.5 y Qwen2-VL ronda los 82 puntos). No obstante, supone una buena mejora con respecto a la generación anterior de Janus.
En cuanto a la generación de imágenes, la mejora respecto a la generación anterior es aún más significativa, y se considera un nivel excelente entre los modelos de código abierto. La puntuación de Janus-Pro en la prueba de referencia GenEval (0,80) también supera a modelos como DALL-E 3 (0,67) y Stable Diffusion 3 Medium (0,74).