
dan era AI telah tiba secara diam-diam.
Mungkin tidak ada yang menyangka bahwa pada Tahun Baru Imlek kali ini, topik terpanas bukan lagi pertarungan amplop merah tradisional di Internet, yang bermitra dengan Gala Festival Musim Semi, melainkan perusahaan-perusahaan AI.
Menjelang Festival Musim Semi, perusahaan model besar sama sekali tidak mengendur, memperbarui gelombang model dan produk. Namun demikian, yang paling banyak dibicarakan adalah DeepSeek, "perusahaan model besar" yang muncul tahun lalu.
Pada malam hari tanggal 20 Januari, DeepSeek merilis versi resmi dari model penalarannya DeepSeek-R1. Dengan menggunakan biaya pelatihan yang rendah, model ini secara langsung melatih kinerja yang tidak kalah dengan model penalaran OpenAI o1. Selain itu, ini sepenuhnya gratis dan open source, yang secara langsung memicu gempa industri.
Ini adalah pertama kalinya AI dalam negeri membuat kehebohan di dunia teknologi dalam skala besar di seluruh dunia, terutama di Amerika Serikat. Para pengembang telah menyatakan bahwa mereka sedang mempertimbangkan untuk menggunakan DeepSeek untuk "membangun kembali segalanya." Setelah gelombang ini, setelah seminggu fermentasi, dan bahkan baru saja dirilis pada bulan Januari, aplikasi seluler DeepSeek dengan cepat mencapai puncak peringkat aplikasi gratis di Apple App Store di AS, tidak hanya melampaui ChatGPT, tetapi juga aplikasi populer lainnya di AS.
Keberhasilan DeepSeek bahkan secara langsung memengaruhi pasar saham AS. Model yang dilatih tanpa menggunakan GPU mahal dalam jumlah besar telah membuat orang berpikir ulang tentang jalur pelatihan AI, yang secara langsung menyebabkan penurunan terbesar pada saham pertama AI, NVIDIA.
Dan bukan itu saja.
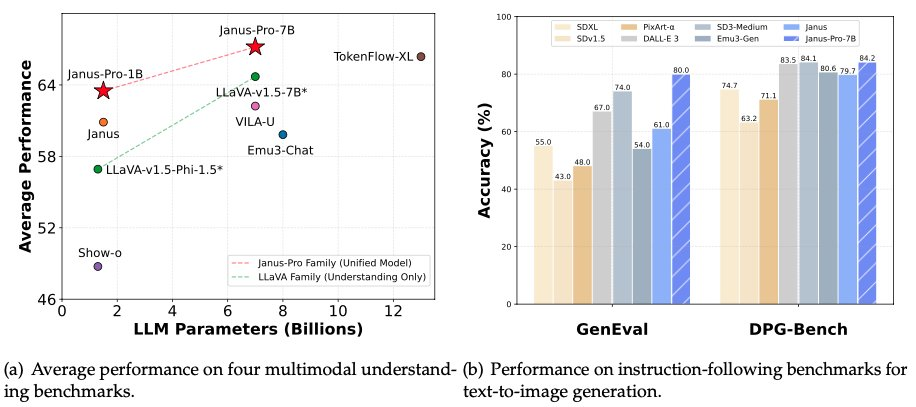
Pada pagi hari tanggal 28 Januari, malam sebelum Malam Tahun Baru, DeepSeek sekali lagi membuka sumber model multimodal Janus-Pro-7B, mengumumkan bahwa model ini telah mengalahkan DALL-E 3 (dari OpenAI) dan Stable Diffusion pada tes benchmark GenEval dan DPG-Bench.
Apakah DeepSeek benar-benar akan menyapu bersih komunitas AI? Dari model inferensi hingga model multimodal, apakah DeepSeek merestrukturisasi segala sesuatu menjadi topik pertama di Tahun Ular?
Janus Provalidasi arsitektur model multimoda yang inovatif
DeepSeek merilis total dua model pada larut malam kali ini: Janus-Pro-7B dan Janus-Pro-1B (parameter 1,5B).
Seperti namanya, model ini merupakan peningkatan dari model Janus sebelumnya.
DeepSeek baru merilis model Janus untuk pertama kalinya pada Oktober 2024. Seperti biasa dengan DeepSeek, model ini mengadopsi arsitektur yang inovatif. Pada banyak model generasi visi, model ini mengadopsi arsitektur Transformer terpadu yang secara bersamaan dapat memproses tugas-tugas teks-ke-gambar dan gambar-ke-teks.
DeepSeek mengusulkan sebuah ide baru, memisahkan pengkodean visual dari pemahaman (grafik-ke-teks) dan tugas-tugas pembuatan (teks-ke-grafik), yang meningkatkan fleksibilitas pelatihan model dan secara efektif mengurangi konflik dan hambatan kinerja yang disebabkan oleh penggunaan pengkodean visual tunggal.
Inilah sebabnya mengapa DeepSeek menamai model ini Janus. Janus adalah dewa pintu Romawi kuno dan digambarkan dengan dua wajah yang menghadap ke arah yang berlawanan. DeepSeek mengatakan bahwa model ini dinamakan Janus karena dapat melihat data visual dengan mata yang berbeda, mengkodekan fitur secara terpisah, dan kemudian menggunakan tubuh yang sama (Transformer) untuk memproses sinyal input ini.
Ide baru ini telah membuahkan hasil yang baik dalam seri model Janus. Tim mengatakan bahwa model Janus memiliki kemampuan mengikuti perintah yang kuat, kemampuan multibahasa, dan model ini lebih cerdas, mampu membaca gambar meme. Model ini juga dapat menangani tugas-tugas seperti mengonversi rumus lateks dan mengonversi grafik ke kode.
Pada seri model Janus Pro, tim telah memodifikasi sebagian proses pelatihan model, yang secara langsung mencapai hasil yang mengalahkan DALL-E 3 dan Stable Diffusion pada uji benchmark GenEval dan DPG-Bench.
Bersamaan dengan model itu sendiri, DeepSeek juga telah merilis kerangka kerja AI multimodal baru Janus Flow, yang bertujuan untuk menyatukan tugas pemahaman dan pembuatan gambar.
Model Janus Pro dapat memberikan output yang lebih stabil dengan menggunakan prompt singkat, dengan kualitas visual yang lebih baik, detail yang lebih kaya, dan kemampuan untuk menghasilkan teks sederhana.
Model ini dapat menghasilkan gambar dan mendeskripsikan gambar, mengidentifikasi objek wisata terkenal (seperti Danau Barat Hangzhou), mengenali teks dalam gambar, dan mendeskripsikan pengetahuan dalam gambar (seperti kue "Tom and Jerry").
One x.com, Banyak orang sudah mulai bereksperimen dengan model baru ini.

Uji pengenalan gambar ditunjukkan di sebelah kiri pada gambar di atas, sedangkan uji pembangkitan gambar ditunjukkan di sebelah kanan.

Seperti yang dapat dilihat, Janus Pro juga melakukan pekerjaan yang baik dalam membaca gambar dengan presisi tinggi. Ini dapat mengenali pengaturan huruf campuran ekspresi matematika dan teks. Di masa mendatang, mungkin akan lebih penting untuk menggunakannya dengan model penalaran.
Parameter 1B dan 7B dapat membuka skenario aplikasi baru
Dalam tugas pemahaman multimodal, model baru Janus-Pro menggunakan SigLIP-L sebagai penyandi visual dan mendukung input gambar 384 x 384 piksel. Dalam tugas pembuatan gambar, Janus-Pro menggunakan tokenizer dari sumber tertentu dengan tingkat downsampling 16.
Ini masih merupakan ukuran gambar yang relatif kecil. X Pada analisis pengguna, model Janus Pro lebih merupakan verifikasi terarah. Jika verifikasi dapat diandalkan, model yang dapat dimasukkan ke dalam produksi akan dirilis.
Namun demikian, perlu dicatat, bahwa model baru yang dirilis oleh Janus kali ini, tidak hanya inovatif secara arsitektural untuk model multimodal, tetapi juga eksplorasi baru dalam hal jumlah parameter.
Model yang dibandingkan oleh DeepSeek Janus Pro kali ini, DALL-E 3, sebelumnya diumumkan memiliki 12 miliar parameter, sedangkan model ukuran besar Janus Pro hanya memiliki 7 miliar parameter. Dengan ukuran yang ringkas, sudah sangat bagus bahwa Janus Pro dapat mencapai hasil seperti itu.
Secara khusus, model 1B Janus Pro hanya menggunakan 1,5 miliar parameter. Pengguna telah menambahkan dukungan untuk model ini ke transformers.js di jaringan eksternal. Ini berarti bahwa model tersebut sekarang dapat menjalankan 100% di browser pada WebGPU!
Meskipun pada saat penulisan artikel ini, penulis belum berhasil menggunakan model baru Janus Pro pada versi web, namun fakta bahwa jumlah parameternya cukup kecil untuk dijalankan secara langsung pada sisi web, masih merupakan suatu peningkatan yang mengagumkan.
Ini berarti bahwa biaya pembuatan gambar/pemahaman gambar terus menurun. Kami memiliki kesempatan untuk melihat penggunaan AI di lebih banyak tempat di mana gambar mentah dan pemahaman gambar tidak dapat digunakan sebelumnya, mengubah hidup kita.
Titik perhatian utama pada tahun 2024 terletak pada bagaimana perangkat keras AI dengan pemahaman multimodal tambahan dapat mengintervensi kehidupan kita. Model pemahaman multimodal dengan parameter yang semakin rendah, atau model yang dapat diharapkan untuk berjalan di tepi, dapat memungkinkan perangkat keras AI untuk semakin meledak.
DeepSeek telah menghebohkan tahun baru. Dapatkah semuanya dilakukan kembali dengan AI Cina?
Dunia AI terus berubah dari hari ke hari.
Sekitar Festival Musim Semi tahun lalu, yang menghebohkan dunia adalah model Sora dari OpenAI. Namun, sepanjang tahun ini, perusahaan-perusahaan Tiongkok telah benar-benar mengejar ketertinggalan dalam hal pembuatan video, sehingga peluncuran Sora di akhir tahun tampak agak suram.
Tahun ini, yang menghebohkan dunia adalah DeepSeek milik Tiongkok.
DeepSeek bukanlah perusahaan teknologi tradisional, tetapi telah membuat model yang sangat inovatif dengan biaya yang jauh lebih rendah daripada kartu GPU dari perusahaan-perusahaan besar Amerika, yang secara langsung mengejutkan rekan-rekannya di Amerika. Orang Amerika telah berseru: "Pelatihan model R1 hanya menghabiskan biaya 5,6 juta dolar AS, yang bahkan setara dengan gaji eksekutif mana pun di tim Meta GenAI. Apakah kekuatan Timur yang misterius ini?"
Sebuah akun parodi yang meniru pendiri DeepSeek, Liang Wenfeng, memposting sebuah gambar yang menarik langsung di X:

Gambar tersebut menggunakan meme yang sedang tren, yaitu penembak Turki yang terkenal di dunia pada tahun 2024.
Pada final pistol udara 10 meter dari cabang olahraga menembak di Olimpiade Paris, penembak Turki berusia 51 tahun, Mithat Dikec, yang hanya mengenakan kacamata rabun biasa dan penyumbat telinga untuk tidur, dengan tenang mengantongi medali perak dengan satu tangan di sakunya. Semua penembak lain yang hadir membutuhkan dua lensa profesional untuk pemfokusan dan pemblokiran cahaya serta sepasang penyumbat telinga peredam bising untuk memulai kompetisi.
Sejak DeepSeek "retak" Model penalaran OpenAIperusahaan teknologi besar di Amerika Serikat berada di bawah tekanan yang kuat. Hari ini, Sam Altman akhirnya menanggapi dengan sebuah pernyataan resmi.

Akankah tahun 2025 menjadi tahun di mana AI Tiongkok memengaruhi persepsi Amerika?
DeepSeek masih menyimpan beberapa rahasia di lengan bajunya - ini ditakdirkan untuk menjadi Festival Musim Semi yang luar biasa.


