

Основные моменты
🔹 Унифицированная архитектура трансформатора: Одна модель обрабатывает оба изображения и генерации, что устраняет необходимость в отдельных системах.
🔹 Масштабируемость и открытый исходный код: Доступно в 1B и 7B версии параметров (с лицензией MIT), оптимизированные для различных приложений и коммерческого использования.
🔹 Современное исполнение: Превосходит OpenAI's DALL-E 3 и Stable Diffusion в таких бенчмарках, как GenEval и DPG-Bench.
🔹 Упрощенное развертывание: Оптимизированная архитектура снижает затраты на обучение/интерпретацию при сохранении гибкости.
Ссылки на модели
- Janus-Pro-7B: HuggingFace
- Janus-Pro-1B: HuggingFace
- GitHub: Код и документы
Почему Janus-Pro выделяется
1. Двойные сверхспособности в одной модели
- Понимание режима: Использует SigLIP-L ("Супер-очки") для анализа изображений (до 384×384) и текста.
- Режим генерации: Рычаги Ректифицированный поток + SDXL-VAE ("Волшебная кисть") для создания высококачественных изображений.
2. Сила мозга и обучение
- Основной курс LLM: Построена на мощной языковой модели DeepSeek (1,5B/7B параметров), которая отлично справляется с контекстуальными рассуждениями.
- Учебный трубопровод: Предварительное обучение на огромных массивах данных → Тонкая настройка под наблюдением → Оптимизация EMA для достижения максимальной производительности.
3. Почему трансформатор перегружен?
- Универсальность задач: Приоритет отдается единому пониманию + генерации, в то время как диффузионные модели сосредоточены исключительно на качестве изображения.
- Эффективность: Авторегрессионная генерация (одношаговая) и итерационное обесцвечивание с помощью диффузии (например, 20 шагов для стабильной диффузии).
- Экономическая эффективность: Единая магистраль Transformer упрощает обучение и развертывание.
Доминирование бенчмарка
📊 Мультимодальное понимание
Janus-Pro-7B превосходит специализированные модели (например, LLaVA) на четырех ключевых бенчмарках, плавно масштабируясь с размером параметров.
🎨 Генерация текста в изображение
- GenEval: Совпадает с SDXL и DALL-E 3.
- DPG-Bench: 84.2% точность (Janus-Pro-7B), опередив всех конкурентов.
Испытания в реальных условиях
- Скорость: ~15 секунд на изображение (L4 GPU, 22 ГБ VRAM).
- Качество: Четкое соблюдение сроков, хотя мелкие детали требуют доработки.
- Colab Demo: Попробуйте Janus-Pro-7B (Требуется уровень Pro).
Техническая разбивка
Архитектура
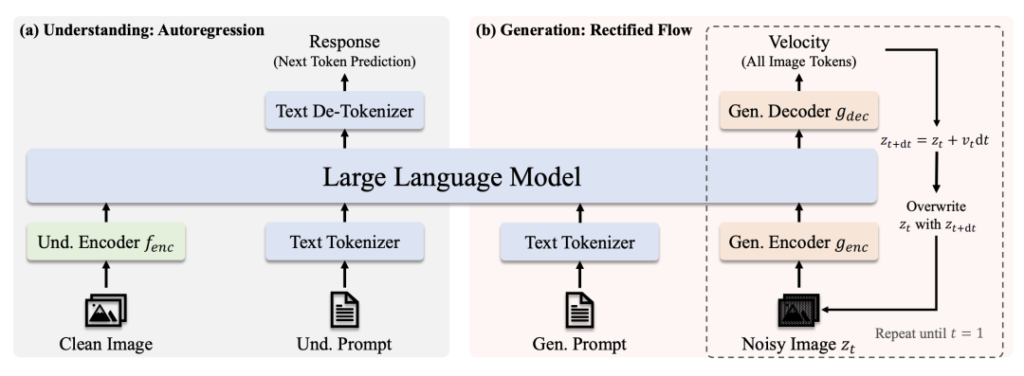
- Понимание пути: Чистое изображение → Кодировщик SigLIP-L → LLM → Текстовый ответ.
- Путь поколения: Зашумленное изображение → Декодер выпрямленного потока + LLM → Итеративное обесцвечивание.
Ключевые инновации
- Отделенное визуальное кодирование: Отдельные пути для понимания/генерации предотвращают "ролевой конфликт" в модулях видения.
- Общий сердечник трансформатора: Обеспечивает передачу знаний между задачами (например, изучение понятия "кошка" помогает как в распознавании, так и в рисовании).
Общественный резонанс
АК (исследователь искусственного интеллекта): "Простота и гибкость Janus-Pro делают его главным кандидатом для мультимодальных систем нового поколения. Разделяя зрительные пути и сохраняя единый трансформер, он балансирует между специализацией и обобщением, что является редким достижением".
Почему лицензия MIT имеет значение
- Свобода: Используйте, изменяйте и распространяйте в коммерческих целях с минимальными ограничениями.
- Прозрачность: Полный доступ к коду ускоряет совершенствование по инициативе сообщества.
Финальный дубль
Janus-Pro от DeepSeek - это не просто еще одна модель ИИ, это смена парадигмы. Объединяя понимание и генерацию под одной крышей, она открывает двери для более умных творческих инструментов, приложений в реальном времени и экономически эффективных развертываний. С открытым исходным кодом и лицензированием MIT это может стать катализатором следующей волны мультимодальных инноваций. 🚀
Для разработчиков: Проверьте Узлы ComfyUI и присоединяйтесь к волне экспериментов!
спонсором этого поста является:




