

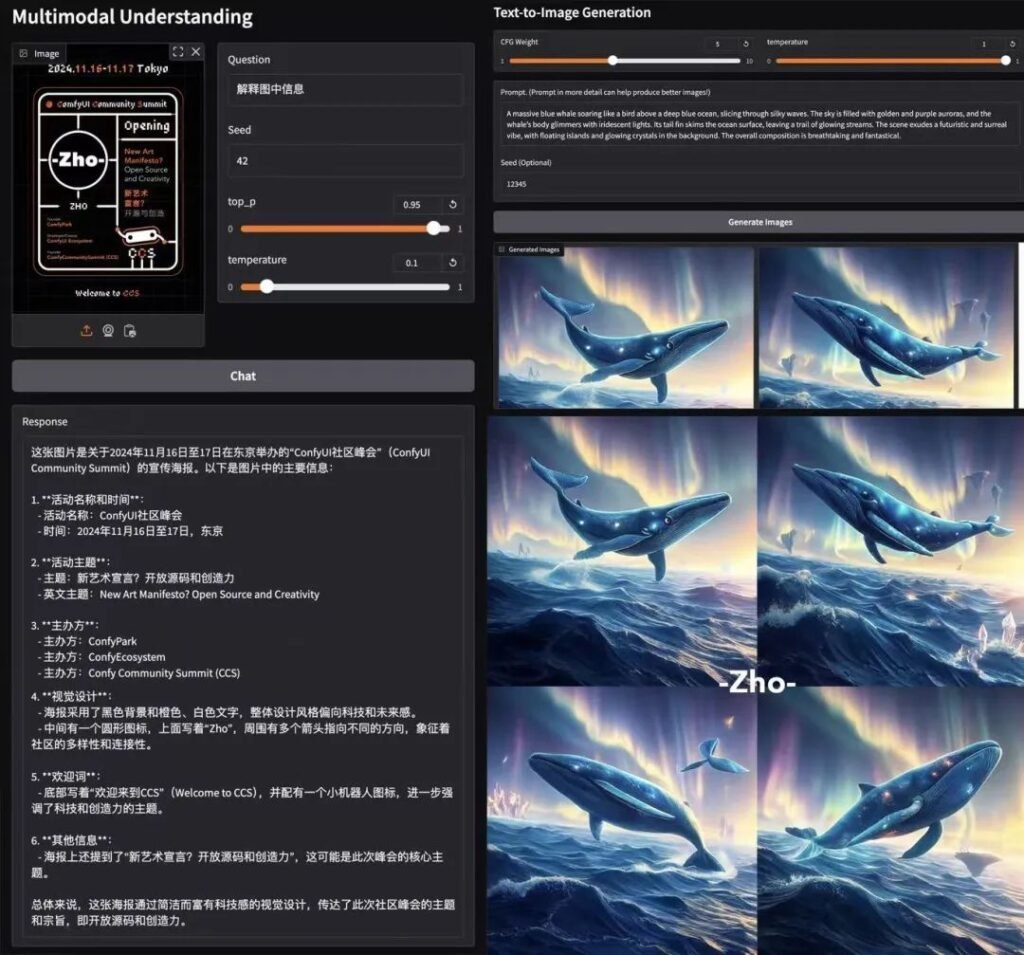
重點介紹
🔹 統一變壓器架構:單一模型同時處理影像理解 和 生成,消除了對獨立系統的需求。
🔹 可擴充與開放原始碼:可用於 1B 和 7B 參數版本 (MIT 授權),針對不同的應用程式和商業用途進行最佳化。
🔹 最先進的效能:在 GenEval 和 DPG-Bench 等基準測試中,表現優於 OpenAI 的 DALL-E 3 和 Stable Diffusion。
🔹 簡化部署:精簡的架構可降低訓練/會議成本,同時保持彈性。
型號連結
為何 Janus-Pro 能脫穎而出
1.一機兩用
- 瞭解模式:用途 SigLIP-L (「超級眼鏡」) 來分析影像 (最大 384×384) 和文字。
- 世代模式:槓桿 整流 + SDXL-VAE (神奇畫筆」)來製作高品質影像。
2.腦力與訓練
- 核心 LLM:建構於 DeepSeek 強大的語言模型 (1.5B/7B 參數),擅長上下文推理。
- 訓練管道:在大量資料集上進行預訓 → 監督微調 → 優化 EMA 以達到最高效能。
3.為何變壓器過度擴散?
- 任務多樣性:以統一理解 + 產生為優先,而擴散模型則純粹著重於影像品質。
- 效率:自回歸生成 (單步) vs. 擴散的反覆去噪 (例如 Stable Diffusion 的 20 步)。
- 成本效益:單一 Transformer 骨幹可簡化訓練與部署。
基準優勢
📊 多模式理解
Janus-Pro-7B 在四個關鍵基準上的表現優於專用模型 (例如 LLaVA),並可隨著參數大小平穩擴充。
文字轉圖像製作
- GenEval:匹配 SDXL 和 DALL-E 3。
- DPG-Bench: 84.2% 精度 (Janus-Pro-7B) ,超越所有競爭對手。
實際測試
- 速度:~15 秒/影像 (L4 GPU、22GB VRAM)。
- 品質:雖然小細節需要改進,但仍非常迅速。
- Colab 演示: 試試 Janus-Pro-7B (需要專業級)。
技術細目
建築
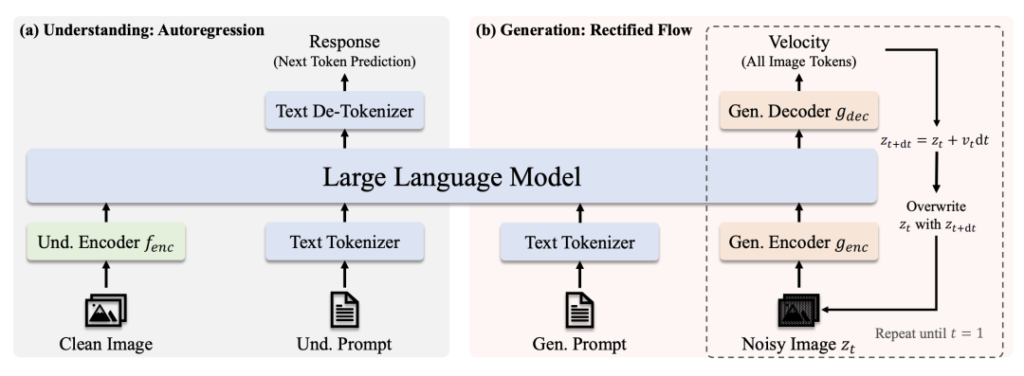
- 瞭解路徑:淨化影像 → SigLIP-L 編碼器 → LLM → 文字回應。
- 世代路徑:雜訊影像 → 整流解碼器 + LLM → 迭代式去噪。
主要創新
- 解耦視覺編碼:獨立的理解/生成途徑可防止視覺模組中的 「角色衝突」。
- 共用變壓器核心:可進行跨任務的知識轉移 (例如,學習「貓」的概念可同時幫助識別和繪圖)。
社區動態
AK (AI 研究員): "Janus-Pro 的簡單性和靈活性使其成為下一代多模式系統的主要候選產品。透過解耦視覺路徑,同時保持統一的 Transformer,它在專門化與通用化之間取得了平衡,這是一項罕見的壯舉"。
MIT 授權為何重要
- 自由:使用、修改和分發的商業限制極少。
- 透明度:完整的程式碼存取可加速社群驅動的改進。
最後看法
DeepSeek 的 Janus-Pro 不只是另一種 AI 模型,而是一種範式轉換。藉由將理解與生成統一在一個屋簷下,它為更智慧的創意工具、即時應用與具成本效益的部署打開了大門。透過開放原始碼存取和 MIT 授權,這可能會成為下一波多模式創新的催化劑。🚀
給開發人員:查看 ComfyUI 節點 並加入實驗浪潮!
本文章由贊助:


