

Key Highlights
🔹 Unified Transformer Architecture: A single model handles both image understanding and generation, eliminating the need for separate systems.
🔹 Scalable & Open-Source: Available in 1B and 7B parameter versions (MIT-licensed), optimized for diverse applications and commercial use.
🔹 State-of-the-Art Performance: Outperforms OpenAI’s DALL-E 3 and Stable Diffusion in benchmarks like GenEval and DPG-Bench.
🔹 Simplified Deployment: Streamlined architecture reduces training/inference costs while maintaining flexibility.
Model Links
- Janus-Pro-7B: HuggingFace
- Janus-Pro-1B: HuggingFace
- GitHub: Code & Docs
Why Janus-Pro Stands Out
1. Dual Superpowers in One Model
- Understanding Mode: Uses SigLIP-L (the “super glasses”) to analyze images (up to 384×384) and text.
- Generation Mode: Leverages Rectified Flow + SDXL-VAE (the “magic brush”) to create high-quality images.
2. Brainpower & Training
- Core LLM: Built on DeepSeek’s powerful language model (1.5B/7B parameters), excelling at contextual reasoning.
- Training Pipeline: Pre-training on massive datasets → Supervised fine-tuning → EMA optimization for peak performance.
3. Why Transformer Over Diffusion?
- Task Versatility: Prioritizes unified understanding + generation, while diffusion models focus purely on image quality.
- Efficiency: Autoregressive generation (single-step) vs. diffusion’s iterative denoising (e.g., 20 steps for Stable Diffusion).
- Cost-Effectiveness: A single Transformer backbone simplifies training and deployment.
Benchmark Dominance
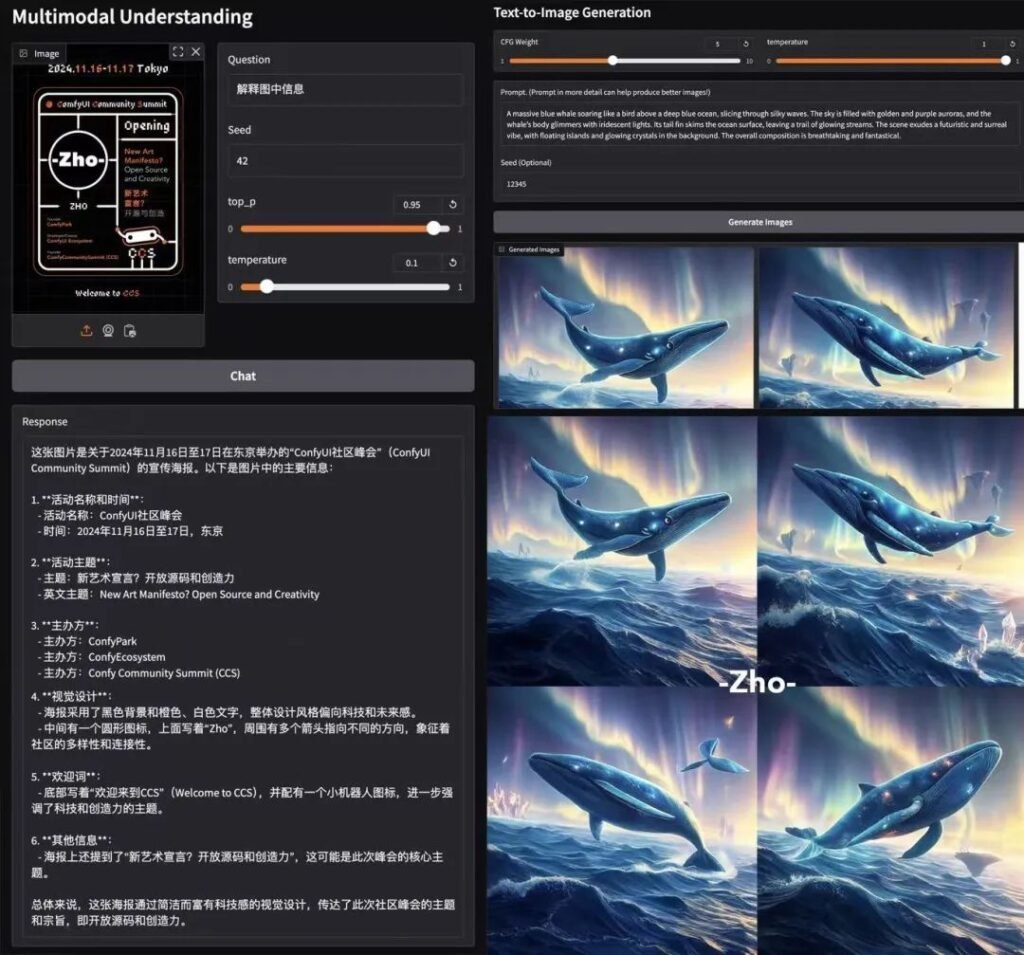
📊 Multimodal Understanding
Janus-Pro-7B outperforms specialized models (e.g., LLaVA) on four key benchmarks, scaling smoothly with parameter size.
🎨 Text-to-Image Generation
- GenEval: Matches SDXL and DALL-E 3.
- DPG-Bench: 84.2% accuracy (Janus-Pro-7B), surpassing all competitors.
Real-World Testing
- Speed: ~15 seconds/image (L4 GPU, 22GB VRAM).
- Quality: Strong prompt adherence, though minor details need refinement.
- Colab Demo: Try Janus-Pro-7B (Pro tier required).
Technical Breakdown
Architecture
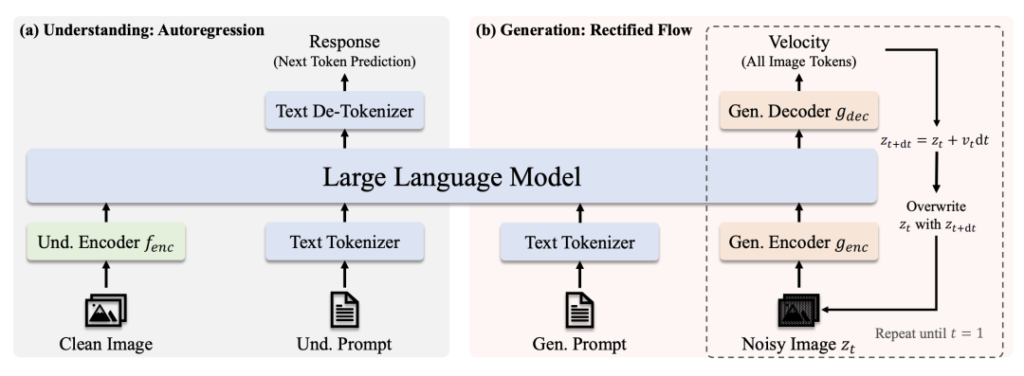
- Understanding Path: Clean image → SigLIP-L encoder → LLM → Text response.
- Generation Path: Noisy image → Rectified Flow decoder + LLM → Iterative denoising.
Key Innovations
- Decoupled Visual Encoding: Separate pathways for understanding/generation prevent “role conflict” in vision modules.
- Shared Transformer Core: Enables cross-task knowledge transfer (e.g., learning “cat” concepts aids both recognition and drawing).
Community Buzz
AK (AI Researcher): “Janus-Pro’s simplicity and flexibility make it a prime candidate for next-gen multimodal systems. By decoupling vision pathways while keeping a unified Transformer, it balances specialization with generalization—a rare feat.”
Why MIT License Matters
- Freedom: Use, modify, and distribute commercially with minimal restrictions.
- Transparency: Full code access accelerates community-driven improvements.
Final Take
DeepSeek’s Janus-Pro isn’t just another AI model—it’s a paradigm shift. By unifying understanding and generation under one roof, it opens doors for smarter creative tools, real-time applications, and cost-efficient deployments. With open-source access and MIT licensing, this could be the catalyst for the next wave of multimodal innovation. 🚀
For devs: Check out the ComfyUI nodes and join the experimentation wave!
this post is sponsored by:


