

주요 특징
🔹 통합 트랜스포머 아키텍처: 단일 모델로 두 가지 이미지 이해 모두 처리 그리고 생성하여 별도의 시스템이 필요하지 않습니다.
🔹 확장성 및 오픈 소스: 다음에서 사용 가능 1B 그리고 7B 다양한 애플리케이션과 상업적 사용에 최적화된 매개변수 버전(MIT 라이선스)을 제공합니다.
🔹 최첨단 성능: GenEval 및 DPG-Bench와 같은 벤치마크에서 OpenAI의 DALL-E 3 및 Stable Diffusion보다 성능이 뛰어납니다.
🔹 간소화된 배포: 간소화된 아키텍처로 유연성을 유지하면서 학습/추론 비용을 절감합니다.
모델 링크
Janus-Pro가 돋보이는 이유
1. 하나의 모델에 두 가지 초능력
- 이해 모드: 용도 SigLIP-L ("슈퍼 안경")을 사용하여 이미지(최대 384×384)와 텍스트를 분석할 수 있습니다.
- 생성 모드: 레버리지 정류된 흐름 + SDXL-VAE ("매직 브러시")를 사용하여 고품질 이미지를 만들 수 있습니다.
2. 두뇌 역량 및 교육
- 핵심 LLM: DeepSeek의 강력한 언어 모델(1.5억/7억 개의 매개변수)을 기반으로 구축되어 문맥 추론에 탁월합니다.
- 교육 파이프라인: 대규모 데이터 세트에 대한 사전 학습 → 감독형 미세 조정 → 최고의 성능을 위한 EMA 최적화.
3. 왜 확산보다 트랜스포머를 선택해야 할까요?
- 작업의 다양성: 통합 이해 + 생성을 우선시하는 반면 확산 모델은 순전히 이미지 품질에만 집중합니다.
- 효율성: 자동 회귀 생성(단일 단계) 대 확산의 반복적 노이즈 제거(예: 안정적 확산의 경우 20단계).
- 비용 효율성: 단일 Transformer 백본으로 교육 및 배포가 간소화됩니다.
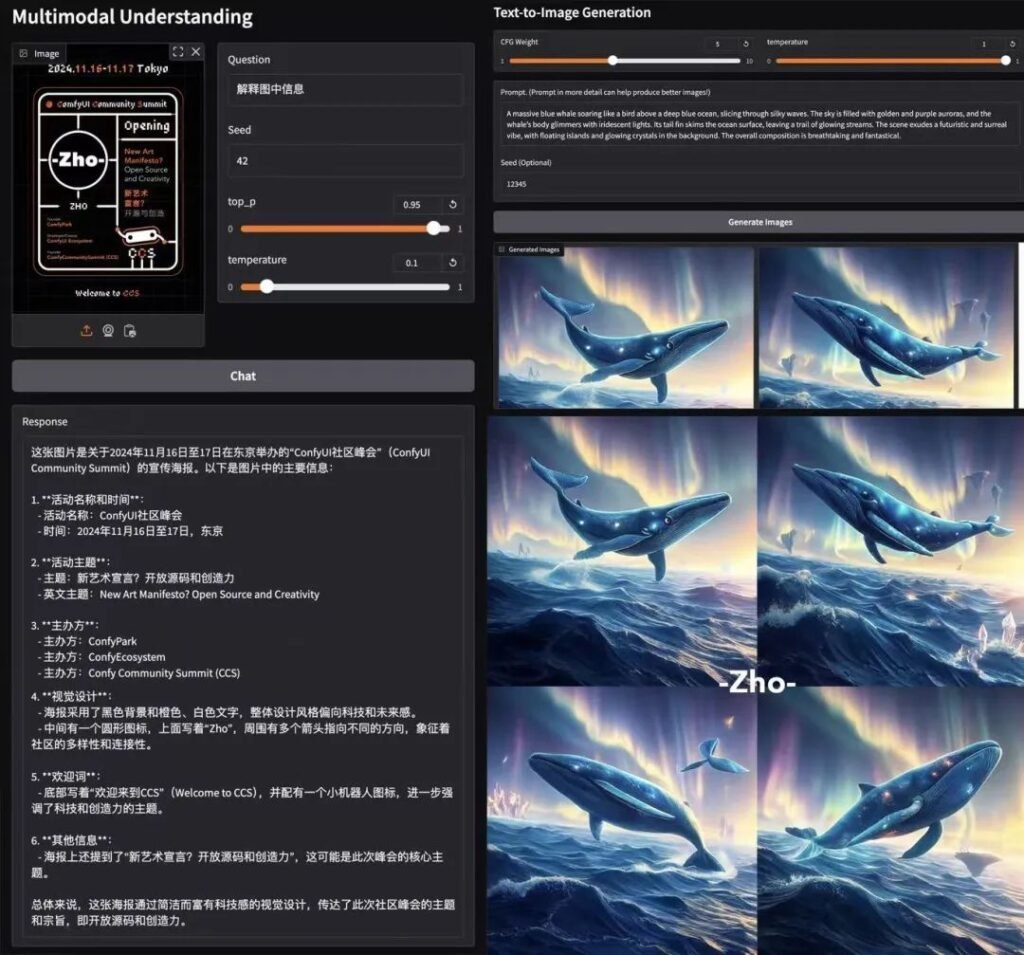
벤치마크 우위
📊 멀티모달 이해
Janus-Pro-7B는 4개의 주요 벤치마크에서 특수 모델(예: LLaVA)보다 성능이 뛰어나며, 매개변수 크기에 따라 원활하게 확장할 수 있습니다.
🎨 텍스트-이미지 생성
- GenEval: SDXL 및 DALL-E 3과 일치합니다.
- DPG-벤치: 84.2% 정확도 (Janus-Pro-7B)로 모든 경쟁사를 능가했습니다.
실제 테스트
- 속도: ~15초/이미지(L4 GPU, 22GB VRAM).
- 품질: 강력하고 신속한 준수, 사소한 세부 사항은 개선이 필요함.
- Colab 데모: Janus-Pro-7B 체험하기 (프로 티어 필요).
기술 분석
아키텍처
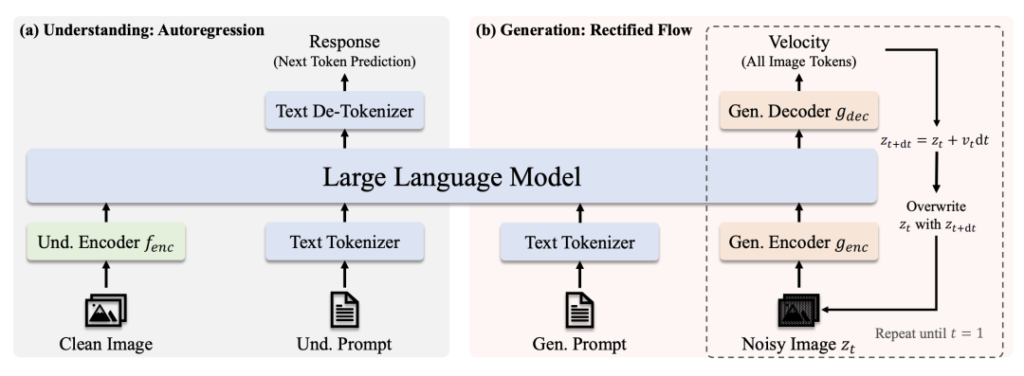
- 경로 이해: 이미지 정리 → SigLIP-L 인코더 → LLM → 텍스트 응답.
- 생성 경로: 노이즈 이미지 → 정류된 흐름 디코더 + LLM → 반복적 노이즈 제거.
주요 혁신
- 디커플링된 비주얼 인코딩: 이해/생성을 위한 별도의 경로를 통해 비전 모듈에서 '역할 충돌'을 방지합니다.
- 공유 트랜스포머 코어: 교차 작업 지식 전달이 가능합니다(예: '고양이' 개념을 학습하면 인식과 그리기 모두에 도움이 됩니다).
커뮤니티 버즈
AK(AI 연구원): "Janus-Pro의 단순성과 유연성은 차세대 멀티모달 시스템을 위한 최고의 후보입니다. 통합된 트랜스포머를 유지하면서 비전 경로를 분리함으로써 전문화와 일반화의 균형을 맞추는 것은 드문 일입니다."
MIT 라이선스가 중요한 이유
- 자유: 최소한의 제한으로 상업적으로 사용, 수정 및 배포할 수 있습니다.
- 투명성: 전체 코드 액세스 권한으로 커뮤니티 주도의 개선이 가속화됩니다.
최종 테이크
딥시크의 Janus-Pro는 단순히 또 하나의 AI 모델이 아니라 패러다임의 전환입니다. 이해와 생성을 한 지붕 아래 통합함으로써 더 스마트한 크리에이티브 도구, 실시간 애플리케이션, 비용 효율적인 배포를 위한 문을 열어줍니다. 오픈 소스 액세스와 MIT 라이선스를 통해 멀티모달 혁신의 다음 물결을 이끄는 촉매제가 될 수 있습니다. 🚀
개발자용: 개발자를 위한 ComfyUI 노드 를 클릭하고 실험의 물결에 동참하세요!
이 게시물은 다음에서 후원합니다:


