

主要亮点
🔹 统一变压器架构:单一模型同时处理图像理解 和 这样就不需要单独的系统了。
🔹 可扩展和开源:可提供 1B 和 7B 参数版本(MIT 许可),针对各种应用和商业用途进行了优化。
🔹 最先进的性能:在 GenEval 和 DPG-Bench 等基准测试中的表现优于 OpenAI 的 DALL-E 3 和 Stable Diffusion。
🔹 简化部署:精简的架构可降低培训/会议成本,同时保持灵活性。
模型链接
Janus-Pro 脱颖而出的原因
1.一模双超
- 了解模式:用途 SigLIP-L (超级眼镜")来分析图像(最大 384×384)和文本。
- 生成模式:杠杆 整流 + SDXL-VAE (神奇画笔")来创建高质量图像。
2.脑力与训练
- 核心法律硕士:基于 DeepSeek 强大的语言模型(1.5B/7B 参数),擅长上下文推理。
- 培训管道:在海量数据集上进行预训练 → 监督微调 → EMA 优化,以达到最佳性能。
3.为什么变压器过度扩散?
- 任务多样性:优先考虑统一理解和生成,而扩散模型则纯粹关注图像质量。
- 效率:自回归生成(单步)与扩散迭代去噪(如稳定扩散的 20 步)。
- 成本效益:单一的 Transformer 主干网简化了培训和部署。
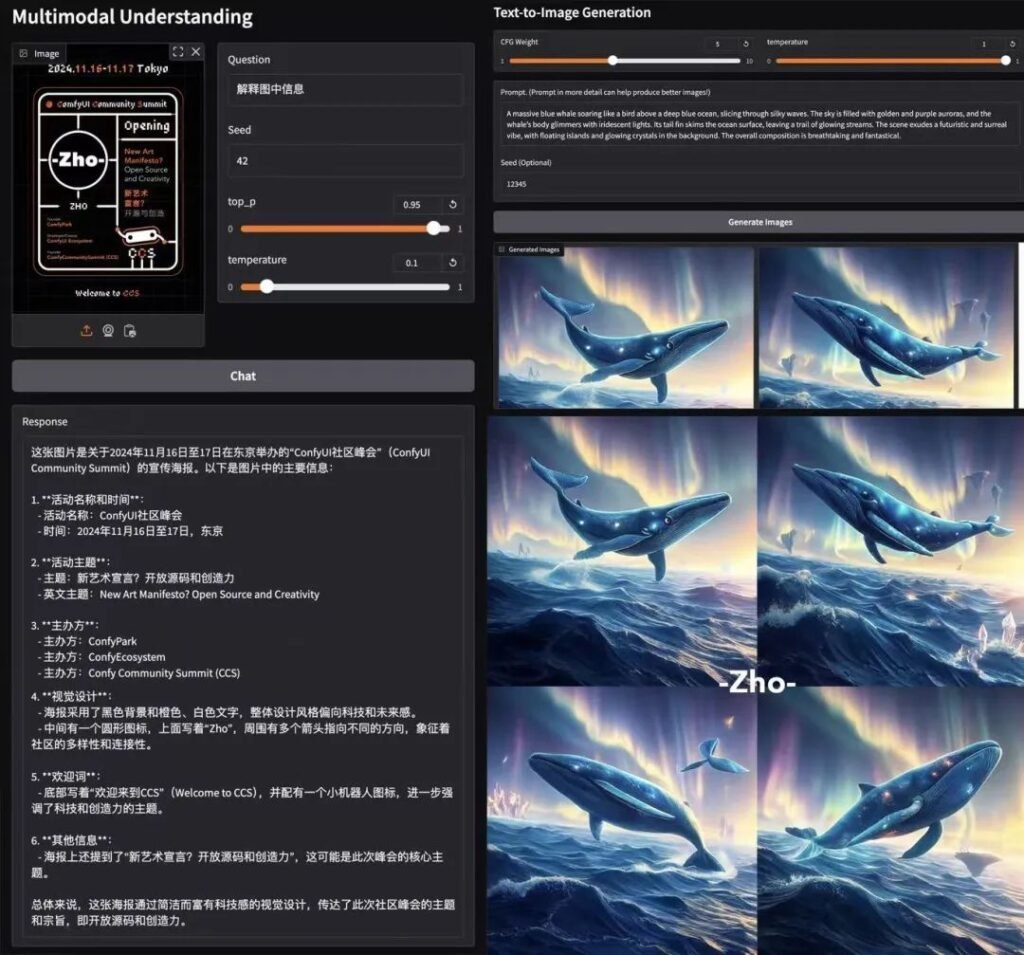
基准优势
📊 多模态理解
在四个关键基准测试中,Janus-Pro-7B 的性能均优于专门模型(如 LLaVA),并随参数大小平滑扩展。
🎨 文本到图像的生成
- GenEval:匹配 SDXL 和 DALL-E 3。
- DPG 工作台: 84.2% 精确度 (Janus-Pro-7B),超越了所有竞争对手。
真实世界测试
- 速度:~15 秒/帧(L4 GPU,22GB VRAM)。
- 质量:及时性强,但小细节需要改进。
- Colab 演示: 试用 Janus-Pro-7B (需要专业级)。
技术细节
建筑学
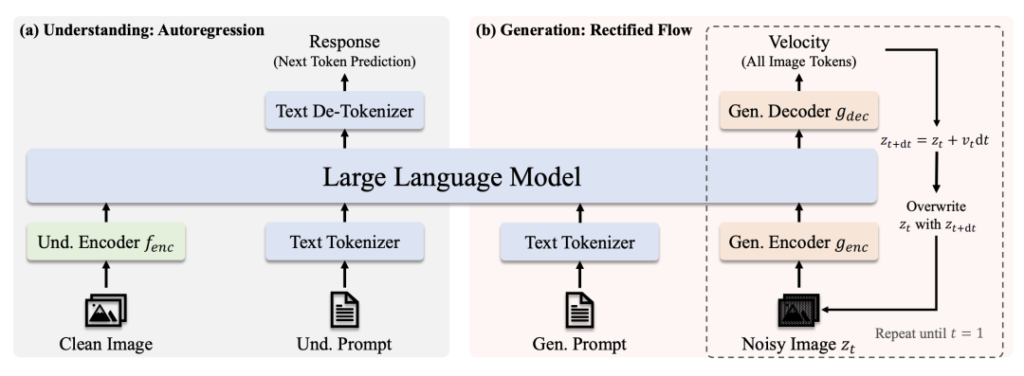
- 了解路径:清洁图像 → SigLIP-L 编码器 → LLM → 文本响应。
- 生成路径:噪声图像 → 整流解码器 + LLM → 迭代去噪。
主要创新
- 解耦视觉编码:在视觉模块中防止 "角色冲突 "的独立理解/生成路径。
- 共用变压器铁芯:实现跨任务知识迁移(例如,学习 "猫 "的概念有助于识别和绘画)。
社区热点
AK(人工智能研究员): "Janus-Pro 的简单性和灵活性使其成为下一代多模态系统的首选。通过解耦视觉通路,同时保持统一的变换器,它在专业化和通用化之间取得了平衡--这是一项罕见的壮举"。
MIT 许可证为何重要
- 自由:使用、修改和商业分发,限制极少。
- 透明度:完全代码访问加快了社区驱动的改进。
最终观点
DeepSeek 的 Janus-Pro 不只是另一种人工智能模型,而是一种模式转变。通过将理解和生成统一在一个平台上,它为更智能的创意工具、实时应用和具有成本效益的部署打开了大门。通过开源访问和 MIT 许可,这将成为下一波多模式创新的催化剂。🚀
对于开发人员:查看 ComfyUI 节点 并加入实验浪潮!
本职位由赞助商赞助:



