On the eve of the Spring Festival, the DeepSeek-R1 model was released. With its pure RL architecture, it has learned from CoT’s great innovations, and outperforms ChatGPT in mathematics, code, and logical reasoning.
In addition, its open-source model weights, low training costs, and cheap API prices have made DeepSeek a hit across the internet, even causing the stock prices of NVIDIA and ASML to plummet for a time.
While exploding in popularity, DeepSeek also released an updated version of the multimodal large model Janus (Janus), Janus-Pro, which inherits the unified architecture of the previous generation of multimodal understanding and generation, and optimizes the training strategy, scaling the training data and model size, bringing stronger performance.

Janus-Pro
Janus-Pro is a unified multimodal language model (MLLM) that can simultaneously process multimodal understanding tasks and generation tasks, i.e., it can understand the content of a picture and also generate text.
It decouples the visual encoders for multimodal understanding and generation (i.e., different tokenizers are used for the input of image understanding and the input and output of image generation), and processes them using a unified autoregressive transformer.
As an advanced multimodal understanding and generation model, it is an upgraded version of the previous Janus model.
In Roman mythology, Janus (Janus) is a two-faced guardian god who symbolizes contradiction and transition. He has two faces, which also suggests that the Janus model can understand and generate images, which is very appropriate. So what exactly has PRO upgraded?
Janus, as a small model of 1.3B, is more like a preview version than an official version. It explores unified multimodal understanding and generation, but has many problems, such as unstable image generation effects, large deviations from user instructions, and inadequate details.
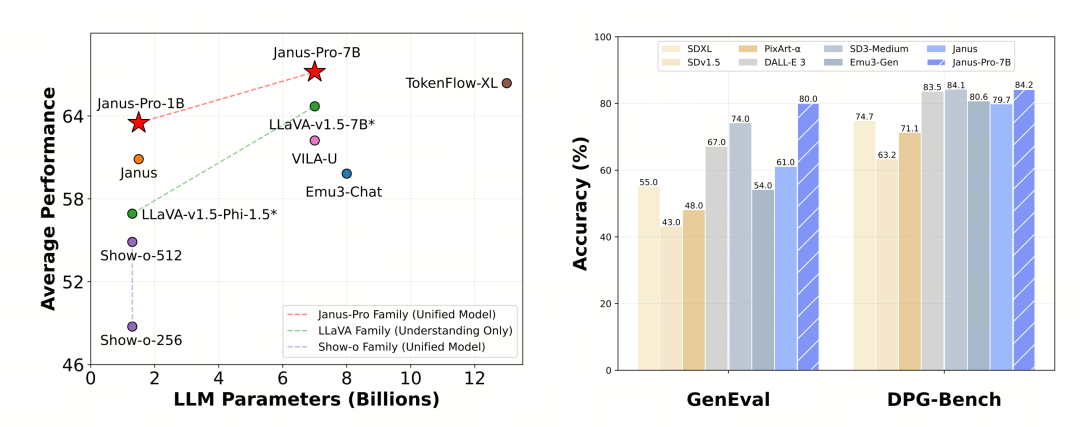
The Pro version optimizes the training strategy, increases the training data set, and provides a larger model (7B) to choose from while providing a 1B model.
Model architecture
Jaus-Pro and Janus are identical in terms of model architecture. (Only 1.3B! Janus unifies multimodal understanding and generation)
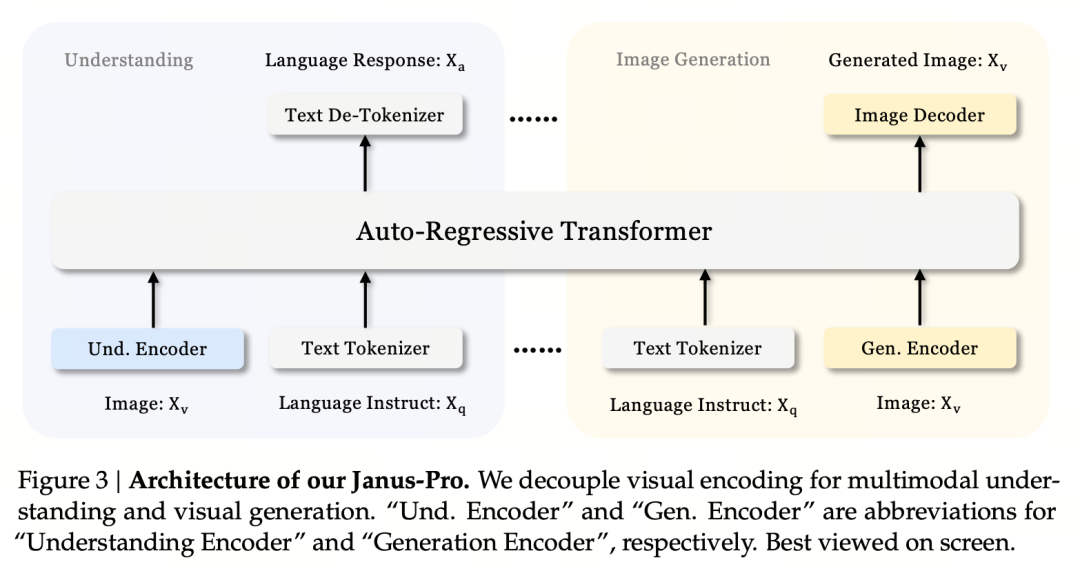
The core design principle is to decouple visual encoding to support multimodal understanding and generation. Janus-Pro encodes the original image/text input separately, extracts high-dimensional features, and processes them through a unified autoregressive Transformer.
Multimodal image understanding uses SigLIP to encode image features (blue encoder in the figure above), and the generation task uses the VQ tokenizer to discretize the image (yellow encoder in the figure above). Finally, all feature sequences are input to the LLM for processing
Training strategy
In terms of training strategy, Janus-Pro has made more improvements. The old version of Janus used a three-stage training strategy, in which Stage I trains the input adapter and image generation head for image understanding and image generation, Stage II performs unified pre-training, and Stage III fine-tunes the understanding encoder on this basis. (The Janus training strategy is shown in the figure below.)
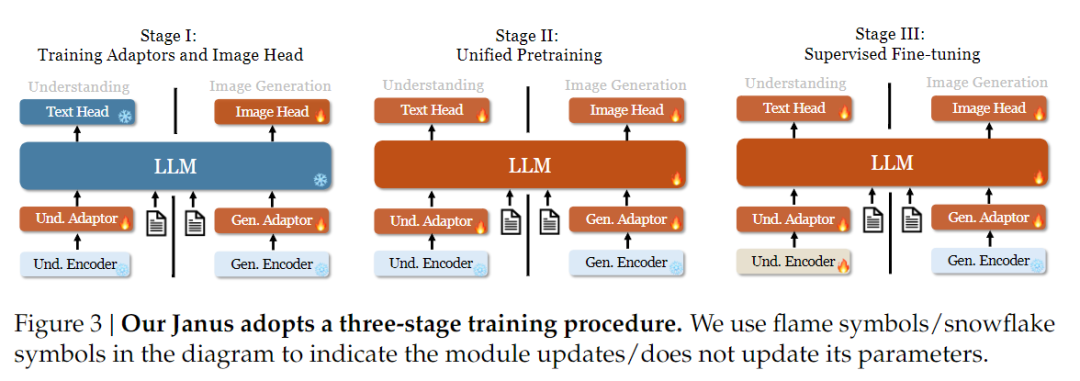
However, this strategy uses the PixArt method to split the training of text-to-image generation in Stage II, which results in low computational efficiency.
To this end, we extended the training time of Stage I and added training with ImageNet data, so that the model can effectively model pixel dependencies with fixed LLM parameters. In Stage II, we discarded ImageNet data and directly used text-image pair data to train, which improves training efficiency. In addition, we adjusted the data ratio in Stage III (multimodal:text-only:visual-semantic graph data from 7:3:10 to 5:1:4), improving multimodal understanding while maintaining visual generation capabilities.
Training data scaling
Janus-Pro also scales the training data of Janus in terms of multimodal understanding and visual generation.
Multimodal understanding: The Stage II pre-training data is based on DeepSeek-VL2 and includes about 90 million new samples, including image caption data (such as YFCC) and table, chart and document understanding data (such as Docmatix).
The Stage III supervised fine-tuning stage further introduces MEME understanding, Chinese dialogue data, etc., to improve the model’s performance in multi-task processing and dialogue capabilities.
Visual generation: Previous versions used real data of low quality and high noise, which affected the stability and aesthetics of the text-generated images.
Janus-Pro introduces about 72 million synthetic aesthetic data, bringing the ratio of real data to synthetic data to 1:1. Experiments have shown that synthetic data accelerates model convergence and significantly improves the stability and aesthetic quality of generated images.
Model scaling
Janus Pro extends the model size to 7B, while the previous version of Janus used 1.5B DeepSeek-LLM to verify the effectiveness of decoupling visual encoding. Experiments show that a larger LLM significantly accelerates the convergence of multimodal understanding and visual generation, further verifying the strong scalability of the method.

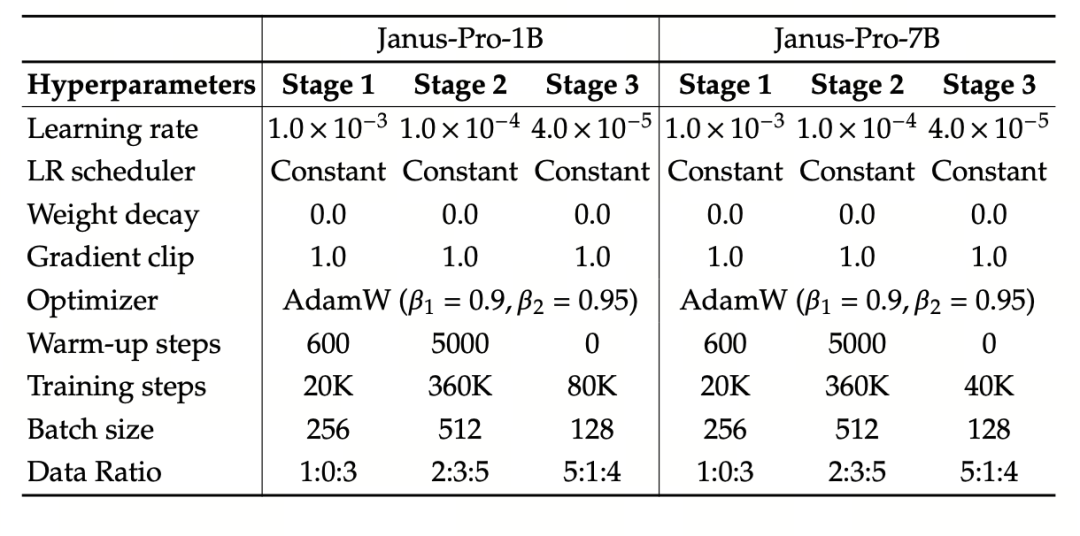
The experiment uses DeepSeek-LLM (1.5B and 7B, supporting a maximum sequence of 4096) as the basic language model. For the multimodal understanding task, SigLIP-Large-Patch16-384 is used as the visual encoder, the dictionary size of the encoder is 16384, the image downsampling multiple is 16, and both the understanding and generation adapters are two-layer MLPs.
Stage II training uses a 270K early stopping strategy, all images are uniformly adjusted to a resolution of 384×384, and sequence packaging is used to improve training efficiency . Janus-Pro is trained and evaluated using HAI-LLM. The 1.5B/7B versions were trained on 16/32 nodes (8×Nvidia A100 40GB per node) for 9/14 days respectively.
Model evaluation
Janus-Pro was evaluated separately in multimodal understanding and generation. Overall, the understanding may be slightly weak, but it is considered excellent among open source models of the same size (guess it is largely limited by the fixed input resolution and OCR capabilities).
Janus-Pro-7B scored 79.2 in the MMBench benchmark test, which is close to the level of first-tier open source models (the same size of InternVL2.5 and Qwen2-VL is around 82 points). However, it is a good improvement over the previous generation of Janus.
In terms of image generation, the improvement over the previous generation is even more significant, and it is considered to be an excellent level among open source models. Janus-Pro’s score in the GenEval benchmark test (0.80) also exceeds models such as DALL-E 3 (0.67) and Stable Diffusion 3 Medium (0.74).