
人工智能时代已悄然来临。
大概谁也没想到,这个春节,最热门的话题不再是传统的互联网红包大战、谁与春晚结伴而行,而是人工智能企业。
临近春节,各大模型公司丝毫没有放松,更新了一波模型和产品。不过,最受关注的还是去年崛起的 "大模型公司 "DeepSeek。
1 月 20 日晚 深度S哎呀 发布了其推理模型 DeepSeek-R1 的正式版本。它使用较低的训练成本,直接训练出了不逊于 OpenAI 推理模型 o1 的性能。而且,它完全免费开源,直接引发了一场行业地震。
这是国产人工智能首次在全球尤其是美国的科技界引起大规模轰动。开发者们纷纷表示,正在考虑用DeepSeek来 "重建一切"。在这股浪潮下,经过一周的发酵,甚至刚刚发布一月,DeepSeek手机应用就迅速登上了美国苹果应用商店免费应用排行榜的榜首,不仅超过了ChatGPT,还超过了美国其他热门应用。
DeepSeek 的成功甚至直接影响了美国股市。一个不使用大量昂贵 GPU 训练出来的模型,让人们重新思考人工智能的训练路径,直接导致人工智能第一股英伟达出现 17% 的最大跌幅。
这还不是全部。
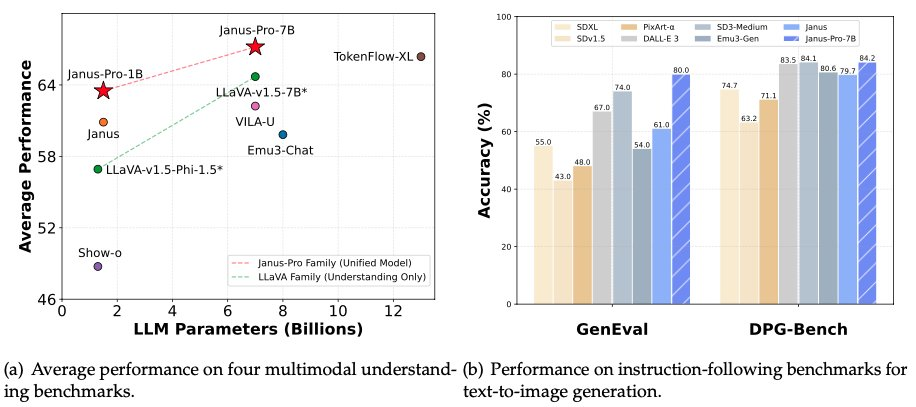
1 月 28 日凌晨,也就是除夕前夜,DeepSeek 再次开源其多模态模型 Janus-Pro-7B,宣布它在 GenEval 和 DPG-Bench 基准测试中击败了 DALL-E 3(来自 OpenAI)和 Stable Diffusion。
DeepSeek 真的会席卷人工智能界吗?从推理模型到多模态模型,DeepSeek 是否会重构蛇年的第一个话题?
Janus Pro验证创新的多模式模型架构
DeepSeek 这次在深夜一共发布了两个模型:Janus-Pro-7B 和 Janus-Pro-1B(1.5B 参数)。
顾名思义,该机型本身就是之前 Janus 机型的升级版。
DeepSeek 在 2024 年 10 月才首次发布 Janus 模型。与 DeepSeek 的一贯做法一样,该模型采用了创新的架构。在许多视觉生成模型中,该模型采用了统一的 Transformer 架构,可以同时处理文本到图像和图像到文本的任务。
DeepSeek 提出了一种新思路,将理解任务(图到文本)和生成任务(文本到图)的视觉编码解耦,提高了模型训练的灵活性,有效缓解了使用单一视觉编码造成的冲突和性能瓶颈。
这就是 DeepSeek 将模型命名为 Janus 的原因。雅努斯是古罗马的门神,其形象是两张面孔朝向相反的方向。DeepSeek 表示,该模型之所以被命名为 "雅努斯",是因为它可以用不同的眼睛观察视觉数据,分别对特征进行编码,然后使用同一个机构(变形器)来处理这些输入信号。
这种新思路在 Janus 系列模型中取得了良好效果。该团队表示,Janus 模型具有很强的命令跟踪能力和多语言能力,而且该模型更加智能,能够读取 meme 图像。它还能处理转换 latex 公式和将图形转换为代码等任务。
在 Janus Pro 系列模型中,团队对模型的训练过程进行了部分修改,直接取得了在 GenEval 和 DPG-Bench 基准测试中击败 DALL-E 3 和 Stable Diffusion 的结果。
除了模型本身,DeepSeek 还发布了新的多模态人工智能框架 Janus Flow,旨在统一图像理解和生成任务。
Janus Pro 型号 可以使用简短的提示提供更稳定的输出,具有更好的视觉质量、更丰富的细节以及生成简单文本的能力。
该模型可以生成图片并描述图片,识别地标景点(如杭州西湖),识别图片中的文字,描述图片中的知识(如 "汤姆和杰瑞 "蛋糕)。
One x.com,许多人已经开始尝试新模式。

上图左侧为图像识别测试,右侧为图像生成测试。

可以看出,Janus Pro 在高精度读取图像方面也表现出色。它可以识别数学表达式和文本的混合排版。未来,将其与推理模型一起使用可能会有更大的意义。
1B 和 7B 的参数可开启新的应用场景
在多模态理解任务中,新型 Janus-Pro 使用 SigLIP-L 作为视觉编码器,支持 384 x 384 像素的图像输入。在图像生成任务中,Janus-Pro 使用来自特定来源的标记化器,降采样率为 16。
这仍然是一个相对较小的图像尺寸。X 从用户分析来看,Janus Pro 模型更像是一个定向验证。如果验证结果可靠,就会推出可以投入生产的模型。
不过,值得注意的是,Janus 此次发布的新模型不仅在多模态模型的架构上有所创新,而且在参数数量上也进行了新的探索。
DeepSeek Janus Pro 这次比较的模型 DALL-E 3 之前宣布有 120 亿个参数,而 Janus Pro 的大尺寸模型只有 70 亿个参数。在如此小巧的体积下,Janus Pro 能取得这样的成绩已经非常不错了。
其中,Janus Pro 的 1B 模型只使用了 15 亿个参数。用户已经在外部网络的 transformers.js 中添加了对该模型的支持。这意味着该模型现在可以在 WebGPU 上的浏览器中运行 100%!
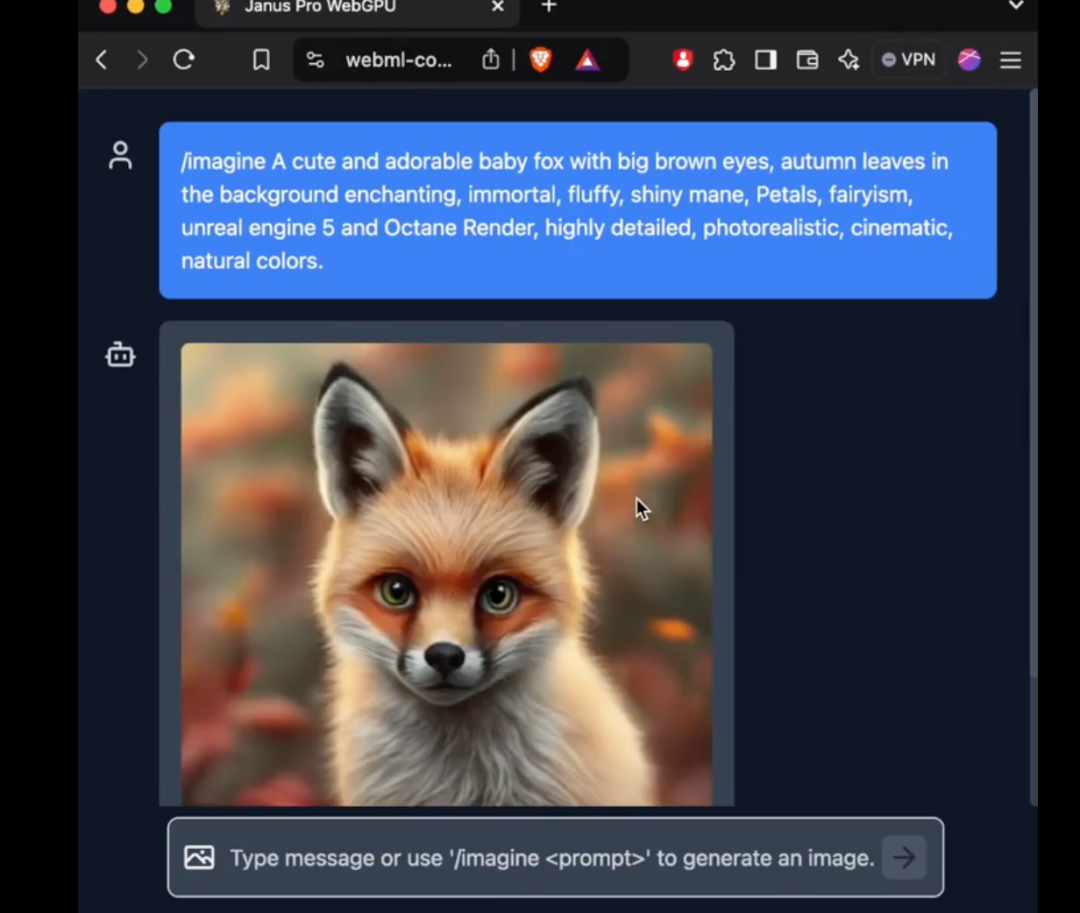
虽然截至发稿时,笔者尚未能在网络版上成功使用 Janus Pro 的新模型,但参数数量少到可以直接在网络侧运行的程度,仍然是一个了不起的进步。
这意味着图像生成/图像理解的成本正在持续下降。我们有机会在更多以前无法使用原始图像和图像理解的地方看到人工智能的应用,从而改变我们的生活。
2024 年的一大热点在于,具有更多模态理解能力的人工智能硬件如何介入我们的生活。参数越来越低的多模态理解模型,或有望在边缘运行的模型,可能会让人工智能硬件进一步爆发。
DeepSeek 搅动了新的一年。中国人工智能能否重塑一切?
人工智能世界日新月异。
去年春节前后,轰动全球的是 OpenAI 的 Sora 模式。然而,在这一年里,中国公司在视频生成方面已经完全赶超,这让 Sora 在年底发布显得有些渺茫。
今年,轰动世界的是中国的 DeepSeek。
DeepSeek 并不是一家传统的科技公司,但它以远低于美国大型模型公司 GPU 卡的成本做出了极具创新性的模型,这直接震惊了美国同行。美国人纷纷感叹:"R1模型的训练只花了560万美元,这甚至相当于Meta GenAI团队中任何一位高管的薪水。这种神秘的东方力量到底是什么?"
一个模仿 DeepSeek 创始人梁文峰的模仿账号直接在 X 上发布了一张有趣的图片:

图片使用了 2024 年世界著名的土耳其射手的流行备忘录。
在巴黎奥运会射击项目的 10 米气手枪决赛中,51 岁的土耳其射击选手米萨特-迪凯克(Mithat Dikec)只戴了一副普通的近视眼镜和一副睡眠耳塞,单手插袋,淡定地将银牌收入囊中。在场的所有其他射击运动员都需要两副用于对焦和遮光的专业镜片和一副降噪耳塞才能开始比赛。
自 DeepSeek "破解 "以来 OpenAI 的推理模型美国各大科技公司都面临着巨大的压力。今天,萨姆-奥特曼(Sam Altman)终于发表正式声明做出了回应。

2025 年,中国的人工智能会影响美国人的认知吗?
DeepSeek 还有一些秘密--这注定是一个不平凡的春节。



