DeepSeek 已更新其网站。
除夕凌晨,DeepSeek 突然在 GitHub 上宣布,Janus 项目空间已将 Janus-Pro 模型和技术报告开放源代码。
首先,让我们强调几个要点:
- "(《世界人权宣言》) Janus-Pro 型号 这次发布的是一个多模式模型,它可以 可以同时执行多模态理解和图像生成任务。它共有两个参数版本、 Janus-Pro-1B 和 Janus-Pro-7B.
- Janus-Pro 的核心创新之处在于将以下方面解耦 多模态理解和生成是两项不同的任务。这样,这两项任务就能在同一模型中高效完成.
- Janus-Pro 与 DeepSeek 去年 10 月发布的 Janus 模型架构一致,但当时 Janus 的体量并不大。查尔斯博士是视觉领域的算法专家,他告诉我们,之前的 Janus "一般般","不如 DeepSeek 的语言模型"。

它旨在解决行业难题:在多模态理解和图像生成之间取得平衡
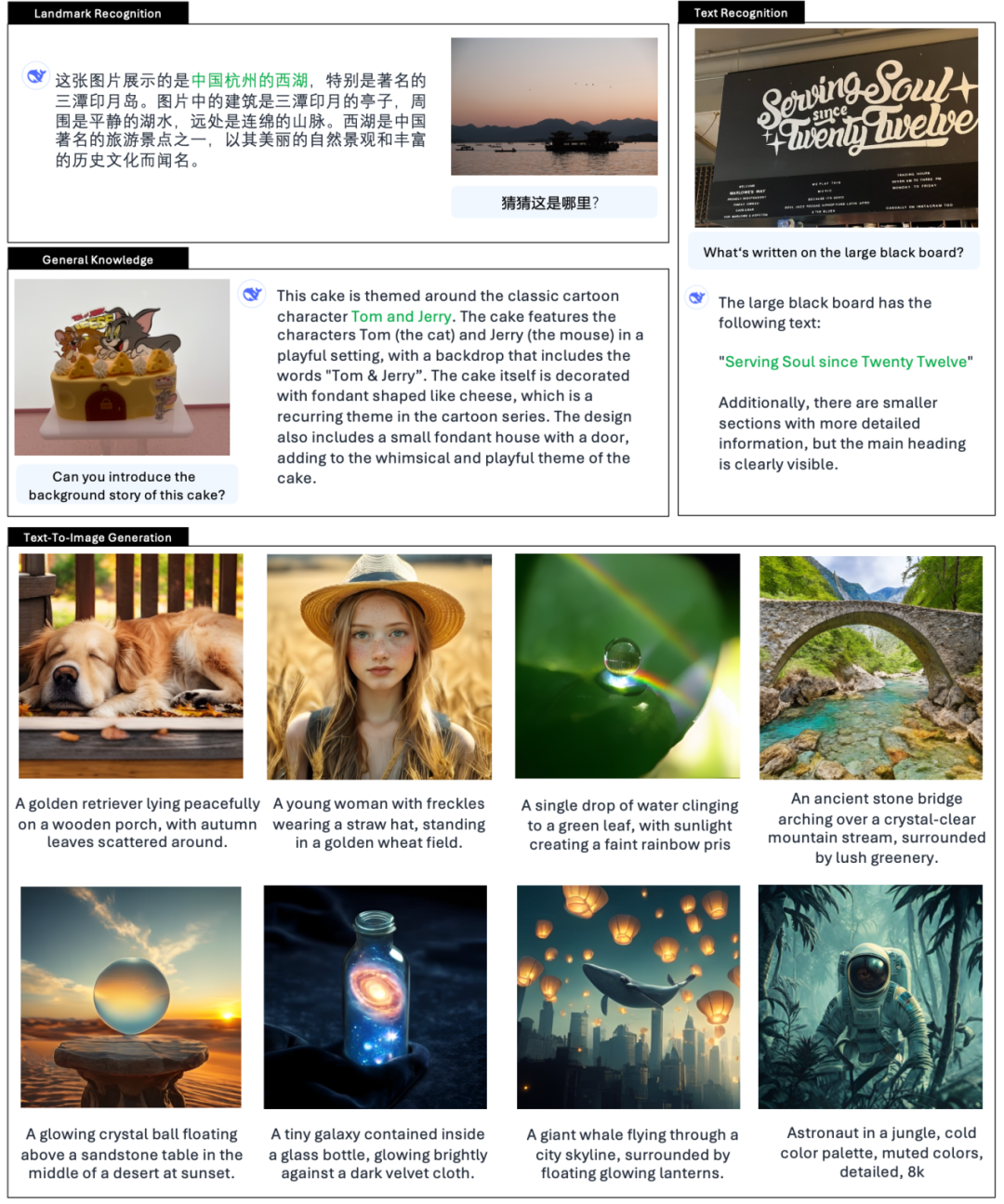
根据 DeepSeek 的官方介绍、 Janus-Pro 不仅能看懂图片、提取和理解图片中的文字,还能同时生成图片。
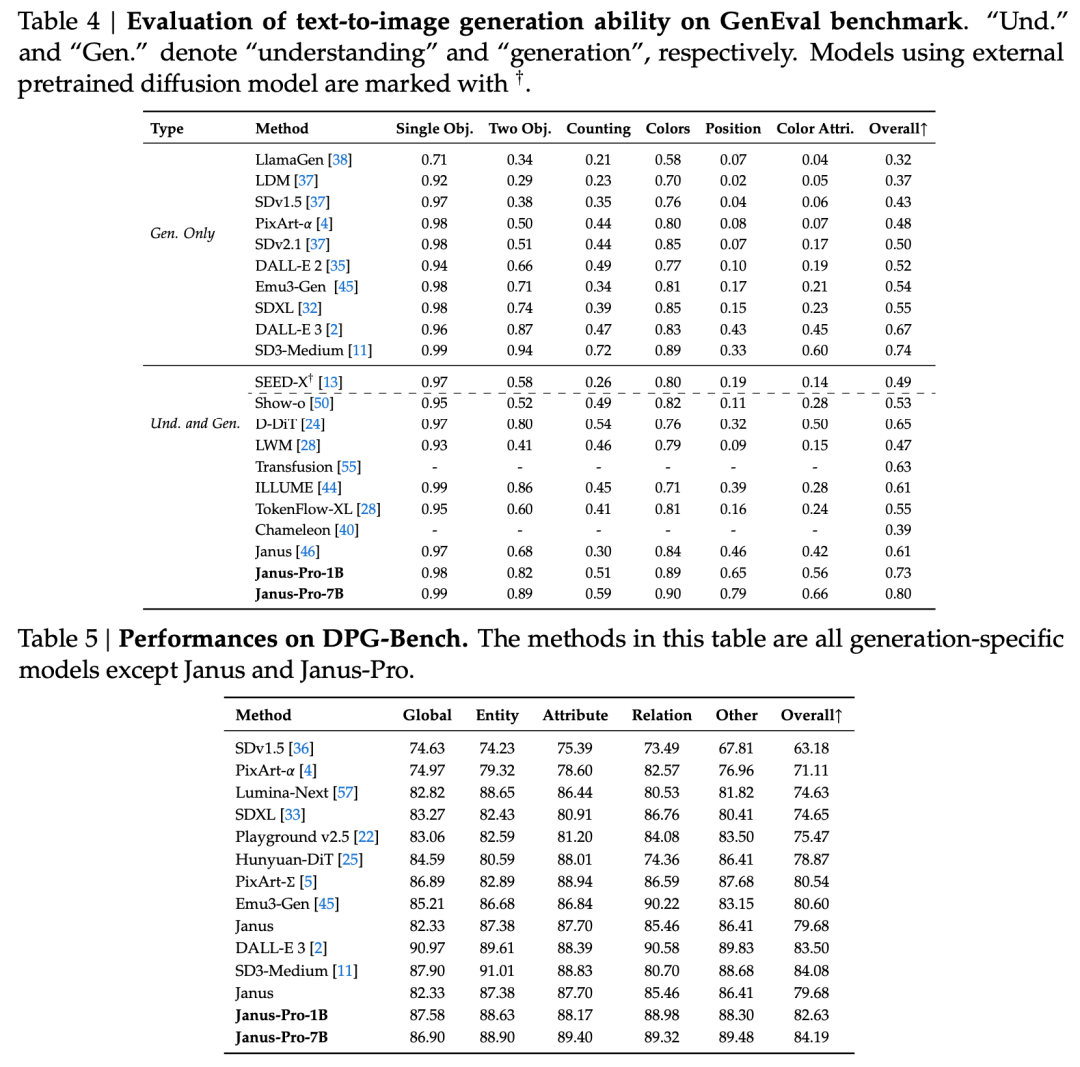
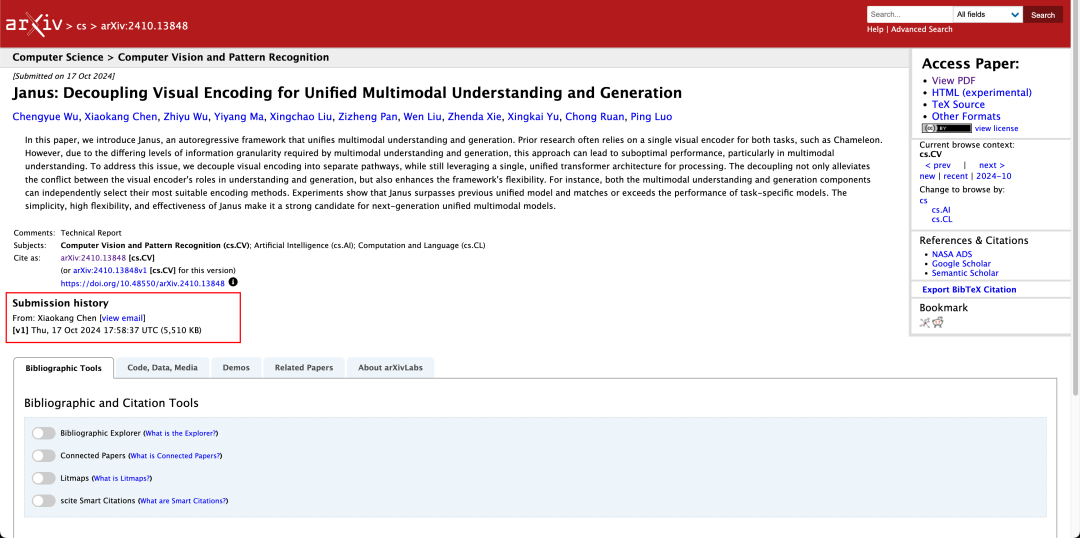
技术报告提到,与其他同类型、同数量级的机型相比,Janus-Pro-7B 在 GenEval 和 DPG-Bench 测试集上的得分如下 超过 SD3-Medium 和 DALL-E 3 等其他型号。
官方还举例说明👇:
X 上也有很多网民在试用新功能。

但偶尔也会发生碰撞。
通过查阅以下技术文件 深度搜索我们发现,Janus Pro 是基于三个月前发布的 Janus 进行的优化。
该系列机型的核心创新点在于 将视觉理解任务与视觉生成任务分离开来,以便平衡这两项任务的效果。
同时进行多模态理解和生成的模型并不少见。本测试集中的 D-DiT 和 TokenFlow-XL 都具备这种能力。
然而,雅努斯的特点是 通过解耦处理,一个可以进行多模态理解和生成的模型可以平衡这两项任务的有效性。
如何平衡这两项任务的有效性是业内的一个难题。 以前的想法是尽可能使用同一个编码器来实现多模态理解和生成。
这种方法的优点是架构简单,没有冗余部署,并与文本模型(也使用相同的方法实现文本生成和文本理解)保持一致。另一个论点是,这种多种能力的融合可以带来一定程度的新兴性。
但事实上,在融合生成和理解之后,这两项任务会发生冲突--图像理解要求模型进行高维抽象,提取图片的核心语义,而这偏重于宏观。而图像生成则侧重于像素级局部细节的表达和生成。
业界通常的做法是优先考虑图像生成能力。这导致多模态模型 可以生成更高质量的图像,但图像理解的结果往往很一般。
Janus 的解耦架构和 Janus-Pro 的优化培训策略
Janus 的解耦架构使模型能够自行平衡理解和生成任务。
根据官方技术报告的结果,无论是多模态理解还是图像生成,Janus-Pro-7B 都在多个测试集上表现出色。

多模态理解 Janus-Pro-7B 在 7 个评估数据集中的 4 个数据集中获得第一名,在其余 3 个数据集中获得第二名,略微落后于排名第一的模型。
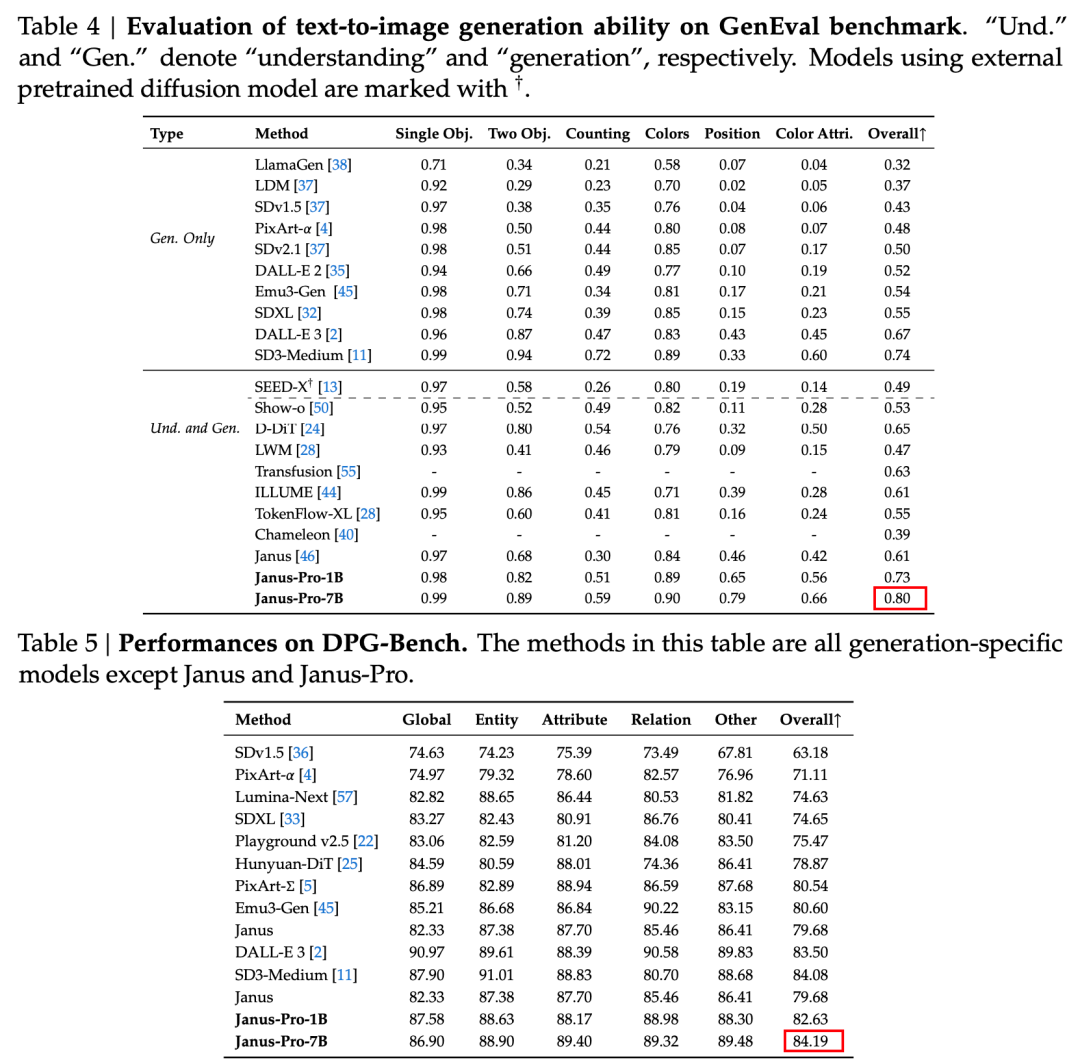
生成图像 Janus-Pro-7B 在 GenEval 和 DPG-Bench 评估数据集上的总分均名列第一。
这种多任务效应主要是由于 Janus 系列使用了两个视觉编码器来完成不同的任务:
- 了解编码器: 用于提取图像中的语义特征,以完成图像理解任务(如图像问答、视觉分类等)。
- 生成式编码器 将图像转换为离散表示(如使用 VQ 编码器),用于文本到图像的生成任务。
有了这种架构、 该模型可以独立优化每个编码器的性能,从而使多模态理解和生成任务各自达到最佳性能。
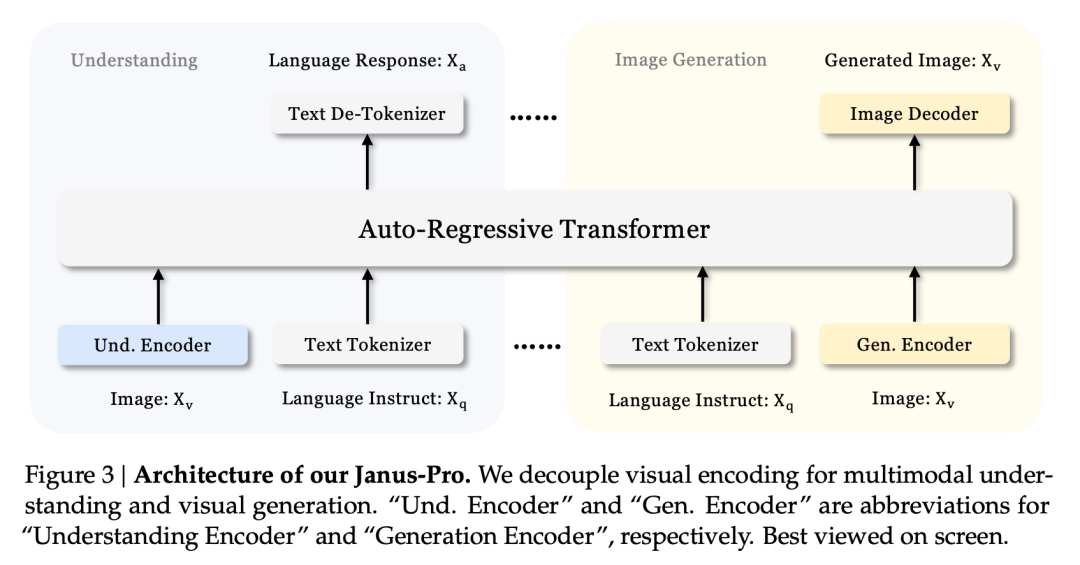
Janus-Pro 和 Janus 都采用了这种解耦架构。那么,Janus-Pro 在过去几个月中经历了哪些迭代?
从评估集的结果可以看出,与之前的 Janus 相比,当前发布的 Janus-Pro-1B 在不同评估集的得分上提高了约 10% 至 20%。与 Janus 相比,Janus-Pro-7B 在扩大参数数量后的改进幅度最大,约为 45%。

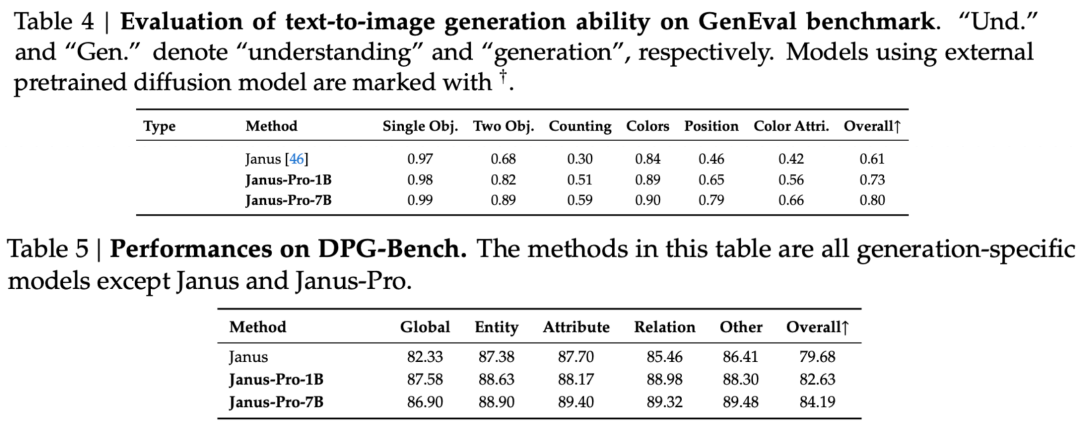
在培训细节方面,技术报告指出,与之前的 Janus 模型相比,当前发布的 Janus-Pro 保留了核心解耦架构设计,并在以下方面进行了迭代 参数大小、训练策略和训练数据。
首先,我们来看看参数.
Janus 的第一个版本只有 1.3B 个参数,而目前发布的专业版包括 1B 和 7B 个参数的模型。
这两种尺寸反映了 Janus 架构的可扩展性。1B 模型是最轻的,外部用户已使用 WebGPU 在浏览器中运行。
还有 的 培训战略。
按照 Janus 的训练阶段划分,Janus Pro 共有三个训练阶段,本文直接将其分为第一阶段、第二阶段和第三阶段。
在保留各阶段基本培训思路和培训目标的基础上,Janus-Pro 对三个阶段的培训时间和培训数据进行了改进。以下是三个阶段的具体改进:
第一阶段--较长的训练时间
与 Janus 相比,Janus-Pro 延长了第一阶段的训练时间,尤其是视觉部分的适配器和图像头的训练。这意味着视觉特征的学习得到了更多的训练时间,希望模型能充分理解图像的细节特征(如像素到语义的映射)。
这种扩展培训有助于确保视觉部分的培训不受其他模块的干扰。
第二阶段 - 删除 ImageNet 数据并添加多模态数据
在第二阶段,Janus 先前参考了 PixArt,并分两部分进行了训练。第一部分使用 ImageNet 数据集进行图像分类任务训练,第二部分使用常规文本到图像数据进行训练。第二阶段大约三分之二的时间用于第一部分的训练。
Janus-Pro 删除了第二阶段的 ImageNet 训练。这种设计允许模型在第二阶段训练中专注于文本到图像数据。根据实验结果,这可以显著提高文本到图像数据的利用率。
除了训练方法设计上的调整,第二阶段使用的训练数据集也不再局限于单一的图像分类任务,而是加入了更多其他类型的多模态数据,如图像描述和对话等,进行联合训练。
第三阶段--优化数据比率
在第三阶段训练中,Janus-Pro 会调整不同类型训练数据的比例。
此前,Janus 在第三阶段使用的训练数据中,多模态理解数据、纯文本数据和文本到图像数据的比例为 7:3:10。Janus-Pro 降低了后两类数据的比例,并将三类数据的比例调整为 5:1:4,即更加注重多模态理解任务。
让我们来看看训练数据。
与 Janus 相比,Janus-Pro 此次大幅增加了高质量的 合成数据。
它扩大了用于多模态理解和图像生成的训练数据的数量和种类。
扩展多模态理解数据:
Janus-Pro 在训练过程中参考了 DeepSeek-VL2 数据集,并增加了约 9000 万个额外数据点,其中不仅包括图像描述数据集,还包括表格、图表和文档等复杂场景数据集。
在监督微调阶段(第三阶段),它将继续添加与 MEME 理解和对话(包括中文对话)经验改进相关的数据集。
扩展视觉生成数据:
原始的真实世界数据质量差、噪声大,导致模型输出不稳定,在文本到图像的任务中生成的图像不够美观。
Janus-Pro 在训练阶段新增了约 7200 万个高审美合成数据,使预训练阶段真实数据与合成数据的比例达到 1:1。
合成数据的提示均来自公共资源。实验表明,加入这些数据后,模型的收敛速度更快,生成的图像在稳定性和视觉美感方面也有明显改善。
效率革命的继续?
总之,DeepSeek 的这一版本为可视化模型带来了效率革命。
与专注于单一功能的视觉模型或偏重于特定任务的多模态模型不同,Janus-Pro 在同一模型中平衡了图像生成和多模态理解两大任务的效果。
此外,尽管参数较小,但它在评估中击败了 OpenAI DALL-E 3 和 SD3-Medium。
延伸到地面,企业只需部署一个模型,就能直接实现图像生成和理解两大功能。再加上只有 7B 的规模,部署的难度和成本都大大降低。
在之前发布的 R1 和 V3 版本的基础上,DeepSeek 又推出了以下新功能,以挑战现有的游戏规则 "紧凑型架构创新、轻量级机型、开源机型和超低培训成本".这就是西方科技巨头甚至华尔街恐慌的原因。
就在刚才,被舆论刷屏了好几天的山姆-奥特曼(Sam Altman)终于正面回应了有关 DeepSeek on X 的信息--在称赞 R1 的同时,他表示 OpenAI 将发布一些公告。