춘절 전날, 딥시크-R1 모델이 출시되었습니다. 순수 RL 아키텍처를 채택한 이 제품은 CoT의 위대한 혁신으로부터 배웠으며, 뛰어난 성능을 자랑합니다. ChatGPT 수학, 코드, 논리적 추론에 능숙합니다.
또한 오픈 소스 모델 가중치, 저렴한 교육 비용, 저렴한 API 가격으로 인해 딥시크는 인터넷에서 큰 인기를 얻었으며, 한동안 NVIDIA와 ASML의 주가가 급락하기도 했습니다.
딥시크는 폭발적인 인기와 함께 이전 세대 멀티모달 이해 및 생성의 통합 아키텍처를 계승하고 학습 전략을 최적화하여 학습 데이터와 모델 크기를 확장하고 더 강력한 성능을 제공하는 멀티모달 대형 모델 Janus(야누스)의 업데이트 버전인 Janus-Pro도 출시했습니다.

Janus-Pro
Janus-Pro 은 다중 모드 이해 작업과 생성 작업을 동시에 처리할 수 있는 통합 다중 모드 언어 모델(MLLM)로, 그림의 내용을 이해하면서 텍스트도 생성할 수 있습니다.
멀티모달 이해와 생성을 위해 시각 인코더를 분리하고(즉, 이미지 이해의 입력과 이미지 생성의 입출력에 서로 다른 토큰화기를 사용), 통합 자동 회귀 변환기를 사용하여 처리합니다.
고급 멀티모달 이해 및 생성 모델로서 이전 야누스 모델의 업그레이드 버전입니다.
로마 신화에서 야누스(야누스)는 모순과 변화를 상징하는 두 얼굴을 가진 수호신입니다. 그는 두 얼굴을 가지고 있는데, 이는 야누스 모델이 이미지를 이해하고 생성할 수 있다는 것을 암시하는 것으로 매우 적절합니다. 그렇다면 PRO는 정확히 어떤 점이 업그레이드되었나요?
야누스는 1.3B의 작은 모델로서 정식 버전이라기보다는 프리뷰 버전에 가깝습니다. 통합된 멀티모달 이해 및 생성을 탐구하지만 불안정한 이미지 생성 효과, 사용자 지침과의 큰 편차, 불충분한 세부 사항 등 많은 문제를 안고 있습니다.
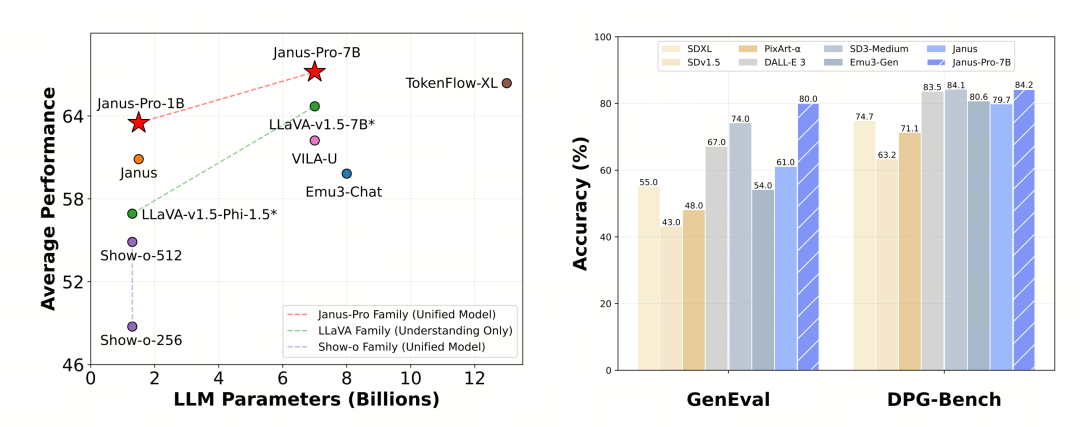
프로 버전은 학습 전략을 최적화하고, 학습 데이터 세트를 늘리며, 1B 모델을 제공하면서 선택할 수 있는 더 큰 모델(7B)을 제공합니다.
모델 아키텍처
Jaus-Pro와 야누스 는 모델 아키텍처 측면에서 동일합니다. (단 13억! 야누스는 멀티모달 이해와 생성을 통합합니다.)
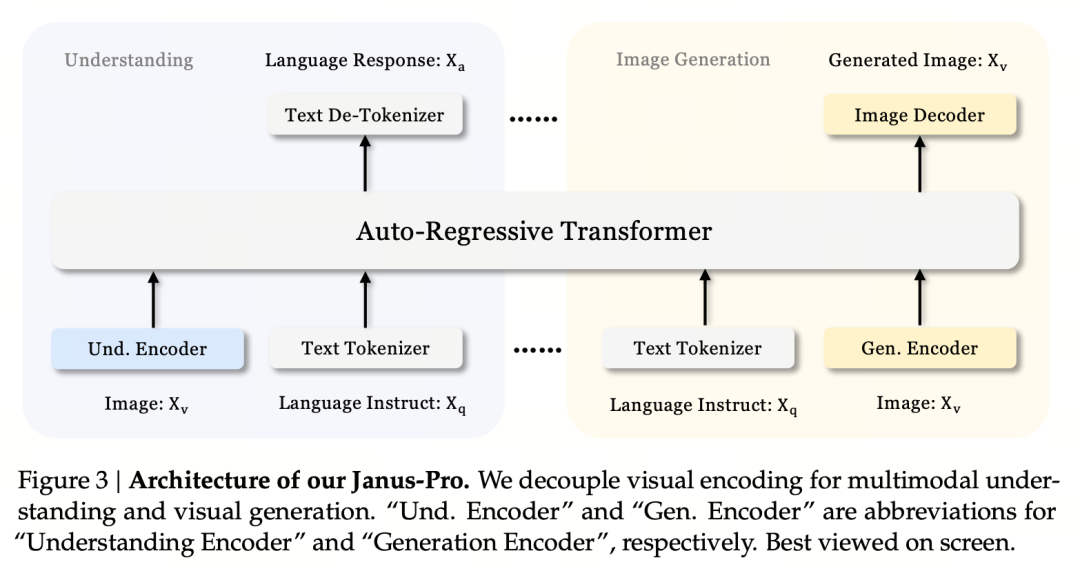
핵심 설계 원칙은 시각적 인코딩을 분리하여 멀티모달 이해와 생성을 지원하는 것입니다. Janus-Pro는 원본 이미지/텍스트 입력을 개별적으로 인코딩하고 고차원 특징을 추출한 후 통합 자동 회귀 트랜스포머를 통해 처리합니다.
멀티모달 이미지 이해는 SigLIP을 사용하여 이미지 특징을 인코딩하고(위 그림의 파란색 인코더), 생성 작업은 VQ 토큰화기를 사용하여 이미지를 이산화합니다(위 그림의 노란색 인코더). 마지막으로 모든 특징 시퀀스는 처리를 위해 LLM에 입력됩니다.
교육 전략
훈련 전략 측면에서 Janus-Pro는 더 많은 개선이 이루어졌습니다. 이전 버전의 야누스는 3단계 훈련 전략을 사용했는데, 1단계에서는 이미지 이해와 이미지 생성을 위해 입력 어댑터와 이미지 생성 헤드를 훈련하고, 2단계에서는 통합 사전 훈련을 수행하며, 3단계에서는 이를 기반으로 이해 인코더를 미세 조정하는 방식이었습니다. (야누스 트레이닝 전략은 아래 그림에 나와 있습니다.)
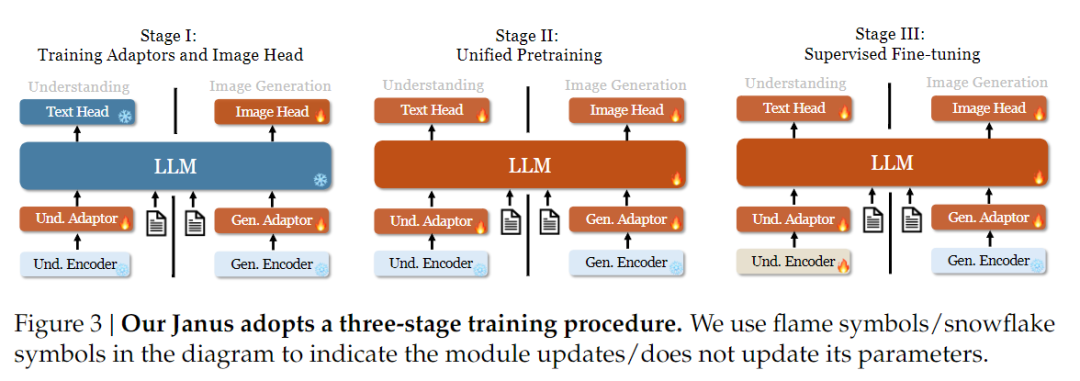
그러나 이 전략은 2단계에서 텍스트-이미지 생성 학습을 분할하는 PixArt 방법을 사용하므로 계산 효율성이 낮습니다.
이를 위해 1단계의 학습 시간을 연장하고 이미지넷 데이터를 사용한 학습을 추가하여 모델이 고정된 LLM 파라미터로 픽셀 종속성을 효과적으로 모델링할 수 있도록 했습니다. 2단계에서는 이미지넷 데이터를 버리고 텍스트-이미지 쌍 데이터를 직접 사용해 훈련함으로써 훈련 효율을 높였습니다. 또한 3단계에서는 데이터 비율을 조정하여(멀티모달:텍스트 전용:시각-시맨틱 그래프 데이터를 7:3:10에서 5:1:4로) 시각 생성 기능을 유지하면서 멀티모달 이해도를 향상시켰습니다.
학습 데이터 확장
Janus-Pro는 또한 야누스의 학습 데이터를 멀티모달 이해 및 시각적 생성 측면에서 확장합니다.
멀티모달 이해: 2단계 사전 학습 데이터는 DeepSeek-VL2를 기반으로 하며 이미지 캡션 데이터(예: YFCC)와 표, 차트 및 문서 이해 데이터(예: Docmatix)를 포함한 약 9천만 개의 새로운 샘플이 포함되어 있습니다.
3단계 감독 미세 조정 단계에서는 MEME 이해, 중국어 대화 데이터 등을 추가로 도입하여 모델의 다중 작업 처리 및 대화 기능 성능을 개선합니다.
시각적 생성: 이전 버전에서는 품질이 낮고 노이즈가 많은 실제 데이터를 사용했기 때문에 텍스트 생성 이미지의 안정성과 미학에 영향을 미쳤습니다.
Janus-Pro는 약 7200만 개의 합성 에스테틱 데이터를 도입하여 실제 데이터와 합성 데이터의 비율을 1:1로 맞췄습니다. 실험 결과 합성 데이터는 모델 융합을 가속화하고 생성된 이미지의 안정성과 심미적 품질을 크게 향상시키는 것으로 나타났습니다.
모델 확장
Janus Pro는 모델 크기를 7B로 확장한 반면, 이전 버전의 야누스는 1.5B DeepSeek-LLM을 사용해 시각 인코딩 디커플링의 효과를 검증했습니다. 실험 결과, LLM이 클수록 멀티모달 이해와 시각 생성의 융합 속도가 크게 빨라져 이 방법의 강력한 확장성을 확인할 수 있었습니다.

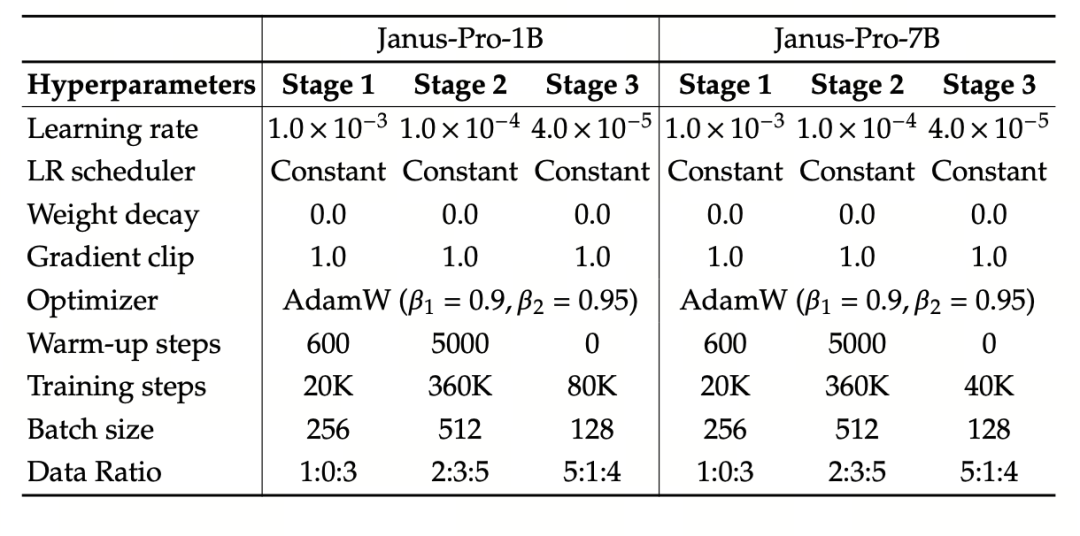
이 실험에서는 기본 언어 모델로 DeepSeek-LLM(1.5B 및 7B, 최대 4096개의 시퀀스를 지원)을 사용합니다. 다중 모드 이해 작업에는 시각 인코더로 SigLIP-Large-Patch16-384를 사용하고, 인코더의 사전 크기는 16384, 이미지 다운샘플링 배수는 16, 이해 및 생성 어댑터는 모두 2계층 MLP를 사용합니다.
2단계 훈련은 270K 조기 정지 전략을 사용하고, 모든 이미지를 384×384 해상도로 균일하게 조정하며, 훈련 효율성을 높이기 위해 시퀀스 패키징을 사용합니다. Janus-Pro는 HAI-LLM을 사용하여 훈련하고 평가합니다. 1.5B/7B 버전은 각각 16/32개 노드(노드당 8×Nvidia A100 40GB)에서 9/14일 동안 훈련되었습니다.
모델 평가
Janus-Pro는 멀티모달 이해와 생성에서 별도로 평가했습니다. 전반적으로 이해도는 다소 떨어지지만 같은 크기의 오픈소스 모델 중에서는 우수한 것으로 평가됩니다(고정된 입력 해상도와 OCR 기능의 한계가 큰 것으로 보입니다).
Janus-Pro-7B는 MMBench 벤치마크 테스트에서 79.2점을 기록하여 1단계 오픈 소스 모델 수준에 근접했습니다(같은 크기의 InternVL2.5 및 Qwen2-VL은 82점 정도입니다). 하지만 이전 세대의 야누스에 비해서는 상당히 개선된 성능입니다.
이미지 생성 측면에서는 이전 세대 대비 개선이 더욱 두드러져 오픈소스 모델 중에서도 우수한 수준으로 평가받고 있습니다. GenEval 벤치마크 테스트에서 Janus-Pro의 점수(0.80)는 DALL-E 3(0.67), Stable Diffusion 3 Medium(0.74) 등의 모델보다 높습니다.