

Najważniejsze informacje
🔹 Zunifikowana architektura transformatora: Pojedynczy model obsługuje zarówno rozumienie obrazu oraz eliminując potrzebę stosowania oddzielnych systemów.
🔹 Skalowalność i otwarte oprogramowanie: Dostępne w 1B oraz 7B wersje parametrów (na licencji MIT), zoptymalizowane pod kątem różnych zastosowań i użytku komercyjnego.
🔹 Najnowocześniejsza wydajność: Przewyższa DALL-E 3 OpenAI i Stable Diffusion w testach porównawczych, takich jak GenEval i DPG-Bench.
🔹 Uproszczone wdrażanie: Usprawniona architektura zmniejsza koszty szkoleń/inferencji przy jednoczesnym zachowaniu elastyczności.
Linki do modeli
- Janus-Pro-7B: HuggingFace
- Janus-Pro-1B: HuggingFace
- GitHub: Kod i dokumenty
Dlaczego Janus-Pro się wyróżnia
1. Podwójne supermoce w jednym modelu
- Tryb zrozumienia: Zastosowania SigLIP-L ("super okulary") do analizy obrazów (do 384×384) i tekstu.
- Tryb generowania: Dźwignie Przepływ rektyfikowany + SDXL-VAE ("magiczny pędzel") do tworzenia wysokiej jakości obrazów.
2. Siła mózgu i trening
- Core LLM: Zbudowany na potężnym modelu językowym DeepSeek (1,5B/7B parametrów), wyróżniającym się rozumowaniem kontekstowym.
- Training Pipeline: Wstępne szkolenie na ogromnych zbiorach danych → Nadzorowane dostrajanie → Optymalizacja EMA dla maksymalnej wydajności.
3. Dlaczego nadmierna dyfuzja w transformatorze?
- Wszechstronność zadań: Priorytetem jest ujednolicone zrozumienie + generowanie, podczas gdy modele dyfuzyjne koncentrują się wyłącznie na jakości obrazu.
- Wydajność: Generowanie autoregresyjne (jednoetapowe) vs. iteracyjne odszumianie dyfuzyjne (np. 20 kroków dla stabilnej dyfuzji).
- Efektywność kosztowa: Pojedyncza sieć szkieletowa Transformer upraszcza szkolenie i wdrażanie.
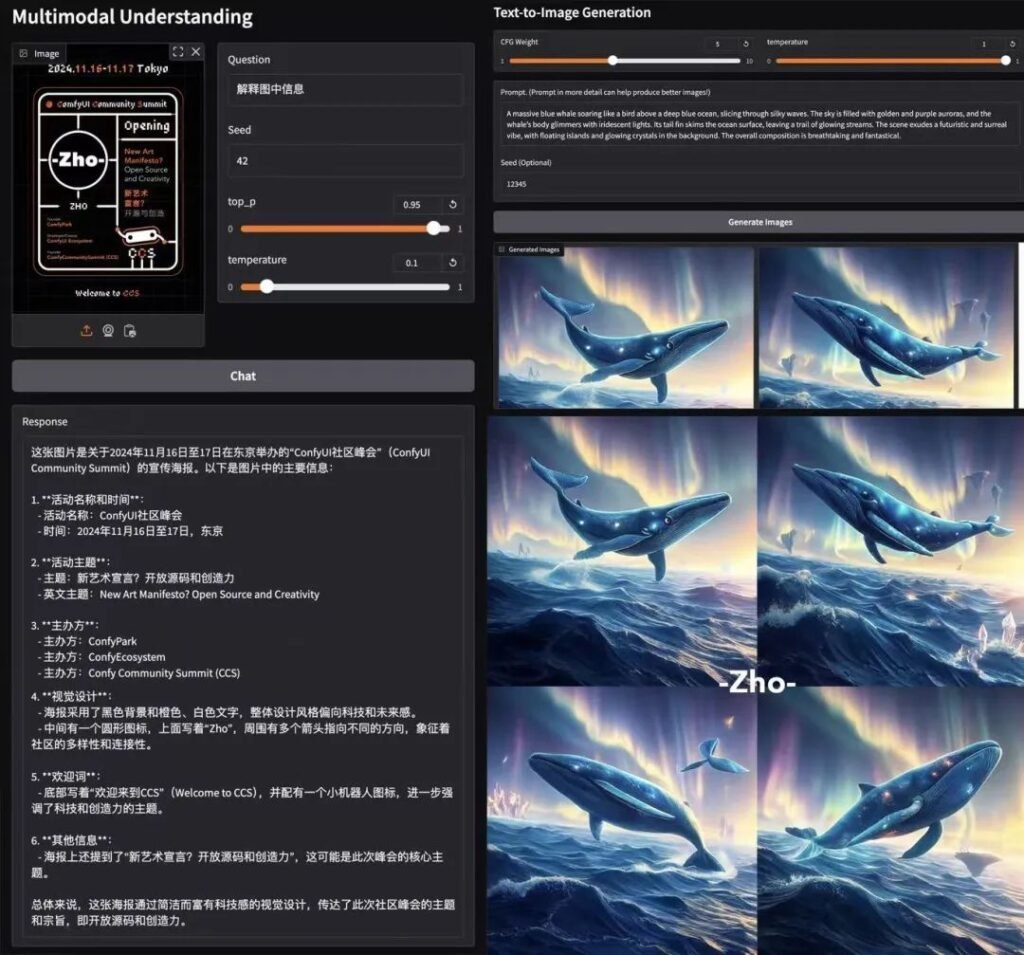
Dominacja benchmarku
Zrozumienie multimodalne
Janus-Pro-7B przewyższa wyspecjalizowane modele (np. LLaVA) w czterech kluczowych testach porównawczych, skalując się płynnie wraz z rozmiarem parametru.
🎨 Generowanie tekstu na obraz
- GenEval: Pasuje do SDXL i DALL-E 3.
- DPG-Bench: 84.2% dokładność (Janus-Pro-7B), przewyższając wszystkich konkurentów.
Testy w świecie rzeczywistym
- Prędkość: ~15 sekund/obraz (GPU L4, 22 GB VRAM).
- Jakość: Mocne przestrzeganie terminów, choć drobne szczegóły wymagają dopracowania.
- Colab Demo: Wypróbuj Janus-Pro-7B (Wymagany poziom Pro).
Podział techniczny
Architektura
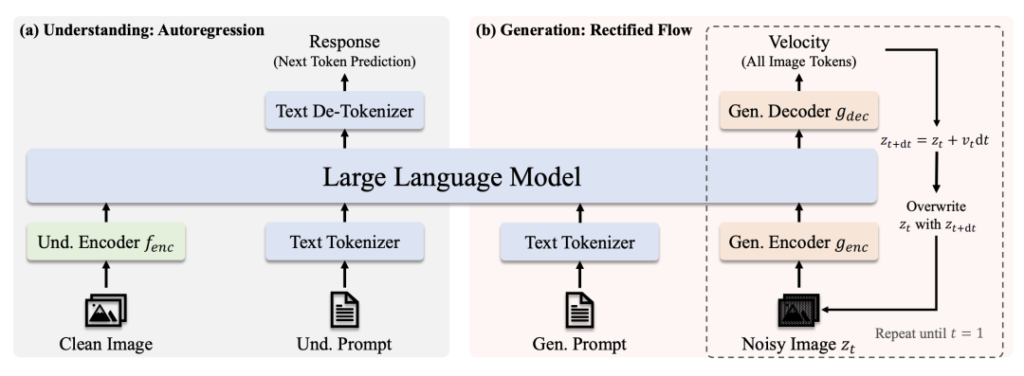
- Zrozumienie ścieżki: Czysty obraz → Koder SigLIP-L → LLM → Odpowiedź tekstowa.
- Ścieżka generacji: zaszumiony obraz → dekoder Rectified Flow + LLM → iteracyjne odszumianie.
Kluczowe innowacje
- Rozdzielone kodowanie wizualne: Oddzielne ścieżki rozumienia/generowania zapobiegają "konfliktowi ról" w modułach wizyjnych.
- Współdzielony rdzeń transformatora: Umożliwia transfer wiedzy między zadaniami (np. nauka koncepcji "kota" pomaga zarówno w rozpoznawaniu, jak i rysowaniu).
Community Buzz
AK (AI Researcher): "Prostota i elastyczność Janus-Pro sprawiają, że jest on głównym kandydatem do systemów multimodalnych nowej generacji. Dzięki oddzieleniu ścieżek widzenia przy jednoczesnym zachowaniu ujednoliconego transformatora, równoważy specjalizację z uogólnieniem - co jest rzadkim osiągnięciem".
Dlaczego licencja MIT ma znaczenie
- Wolność: Używaj, modyfikuj i rozpowszechniaj komercyjnie z minimalnymi ograniczeniami.
- Przejrzystość: Pełny dostęp do kodu przyspiesza wprowadzanie ulepszeń przez społeczność.
Ostateczne ujęcie
DeepSeek Janus-Pro to nie tylko kolejny model sztucznej inteligencji - to zmiana paradygmatu. Łącząc rozumienie i generowanie pod jednym dachem, otwiera drzwi dla inteligentniejszych narzędzi kreatywnych, aplikacji działających w czasie rzeczywistym i opłacalnych wdrożeń. Dzięki otwartemu dostępowi do kodu źródłowego i licencji MIT może to być katalizator kolejnej fali multimodalnych innowacji. 🚀
Dla deweloperów: Sprawdź Węzły ComfyUI i dołącz do fali eksperymentów!
ten post jest sponsorowany przez:



