W przeddzień Festiwalu Wiosny został wydany model DeepSeek-R1. Dzięki czystej architekturze RL czerpie on wiedzę z wielkich innowacji CoT i osiąga lepsze wyniki niż inne modele. ChatGPT w matematyce, kodowaniu i logicznym rozumowaniu.
Ponadto, jego wagi modeli open-source, niskie koszty szkolenia i niskie ceny API sprawiły, że DeepSeek stał się hitem w Internecie, powodując nawet gwałtowny spadek cen akcji NVIDIA i ASML.
Podczas gdy popularność DeepSeek eksplodowała, DeepSeek wydał również zaktualizowaną wersję multimodalnego dużego modelu Janus (Janus), Janus-Pro, który dziedziczy ujednoliconą architekturę poprzedniej generacji multimodalnego rozumienia i generowania oraz optymalizuje strategię szkolenia, skalując dane szkoleniowe i rozmiar modelu, zapewniając większą wydajność.

Janus-Pro
Janus-Pro to zunifikowany multimodalny model językowy (MLLM), który może jednocześnie przetwarzać multimodalne zadania rozumienia i generowania, tj. może rozumieć treść obrazu, a także generować tekst.
Oddziela kodery wizualne do multimodalnego rozumienia i generowania (tj. różne tokenizery są używane dla danych wejściowych rozumienia obrazu oraz danych wejściowych i wyjściowych generowania obrazu) i przetwarza je za pomocą ujednoliconej transformaty autoregresyjnej.
Jako zaawansowany multimodalny model rozumienia i generowania, jest on ulepszoną wersją poprzedniego modelu Janus.
W mitologii rzymskiej Janus (Janus) jest dwulicowym bogiem-opiekunem, który symbolizuje sprzeczność i przemianę. Ma dwie twarze, co sugeruje również, że model Janus może rozumieć i generować obrazy, co jest bardzo odpowiednie. Co dokładnie zaktualizował PRO?
Janus, jako mały model 1.3B, jest bardziej wersją poglądową niż oficjalną. Bada zunifikowane multimodalne rozumienie i generowanie, ale ma wiele problemów, takich jak niestabilne efekty generowania obrazu, duże odchylenia od instrukcji użytkownika i niewystarczające szczegóły.
Wersja Pro optymalizuje strategię treningową, zwiększa zestaw danych treningowych i zapewnia większy model (7B) do wyboru, zapewniając jednocześnie model 1B.
Architektura modelu
Jaus-Pro i Janus są identyczne pod względem architektury modelu. (Tylko 1.3B! Janus ujednolica multimodalne rozumienie i generowanie)
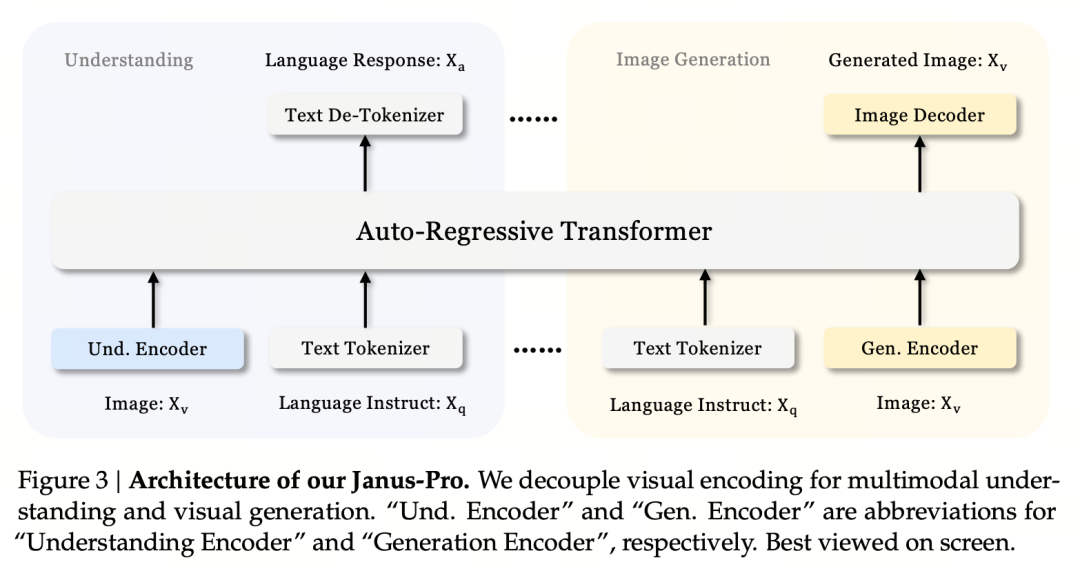
Podstawową zasadą projektową jest oddzielenie kodowania wizualnego w celu wsparcia multimodalnego rozumienia i generowania. Janus-Pro koduje oryginalny obraz/tekst oddzielnie, wyodrębnia wielowymiarowe cechy i przetwarza je za pomocą ujednoliconej transformaty autoregresyjnej.
Multimodalne rozumienie obrazu wykorzystuje SigLIP do kodowania cech obrazu (niebieski koder na powyższym rysunku), a zadanie generowania wykorzystuje tokenizator VQ do dyskretyzacji obrazu (żółty koder na powyższym rysunku). Na koniec wszystkie sekwencje cech są wprowadzane do LLM w celu przetworzenia
Strategia szkoleniowa
Jeśli chodzi o strategię szkolenia, Janus-Pro wprowadził więcej ulepszeń. Stara wersja Janusa wykorzystywała trzystopniową strategię treningową, w której etap I trenuje adapter wejściowy i głowicę generującą obraz w celu zrozumienia obrazu i generowania obrazu, etap II wykonuje ujednolicone szkolenie wstępne, a etap III dostraja koder zrozumienia na tej podstawie. (Strategia treningowa Janus została przedstawiona na poniższym rysunku).
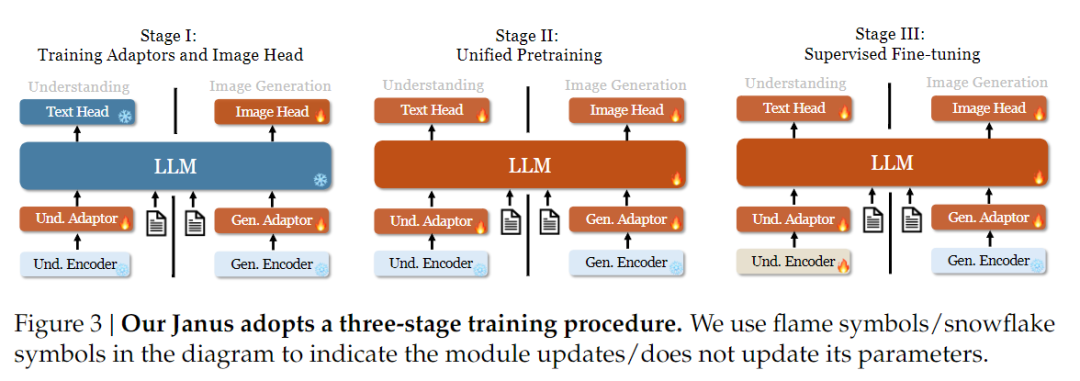
Strategia ta wykorzystuje jednak metodę PixArt do podzielenia treningu generowania tekstu na obraz w etapie II, co skutkuje niską wydajnością obliczeniową.
W tym celu wydłużyliśmy czas szkolenia w etapie I i dodaliśmy szkolenie z danymi ImageNet, aby model mógł skutecznie modelować zależności pikseli przy stałych parametrach LLM. W etapie II odrzuciliśmy dane ImageNet i bezpośrednio wykorzystaliśmy dane pary tekst-obraz do szkolenia, co poprawia wydajność szkolenia. Ponadto dostosowaliśmy stosunek danych w etapie III (multimodalne:tylko tekstowe:wizualno-semantyczne dane wykresu z 7:3:10 do 5:1:4), poprawiając multimodalne zrozumienie przy jednoczesnym zachowaniu możliwości generowania wizualnego.
Skalowanie danych treningowych
Janus-Pro skaluje również dane treningowe Janus pod względem multimodalnego rozumienia i generowania wizualnego.
Rozumienie multimodalne: Dane przedtreningowe Etapu II są oparte na DeepSeek-VL2 i obejmują około 90 milionów nowych próbek, w tym dane podpisów obrazów (takie jak YFCC) oraz dane tabel, wykresów i rozumienia dokumentów (takie jak Docmatix).
Etap III nadzorowanego dostrajania dodatkowo wprowadza zrozumienie MEME, chińskie dane dialogowe itp. w celu poprawy wydajności modelu w zakresie przetwarzania wielozadaniowego i możliwości dialogowych.
Generowanie wizualne: Poprzednie wersje wykorzystywały rzeczywiste dane o niskiej jakości i wysokim poziomie szumów, co wpływało na stabilność i estetykę generowanych obrazów tekstowych.
Janus-Pro wprowadza około 72 milionów syntetycznych danych estetycznych, zwiększając stosunek danych rzeczywistych do danych syntetycznych do 1:1. Eksperymenty wykazały, że dane syntetyczne przyspieszają zbieżność modelu i znacznie poprawiają stabilność i jakość estetyczną generowanych obrazów.
Skalowanie modelu
Janus Pro rozszerza rozmiar modelu do 7B, podczas gdy poprzednia wersja Janusa wykorzystywała 1,5B DeepSeek-LLM, aby zweryfikować skuteczność oddzielania kodowania wizualnego. Eksperymenty pokazują, że większy LLM znacznie przyspiesza zbieżność multimodalnego rozumienia i generowania wizualnego, co dodatkowo weryfikuje silną skalowalność metody.

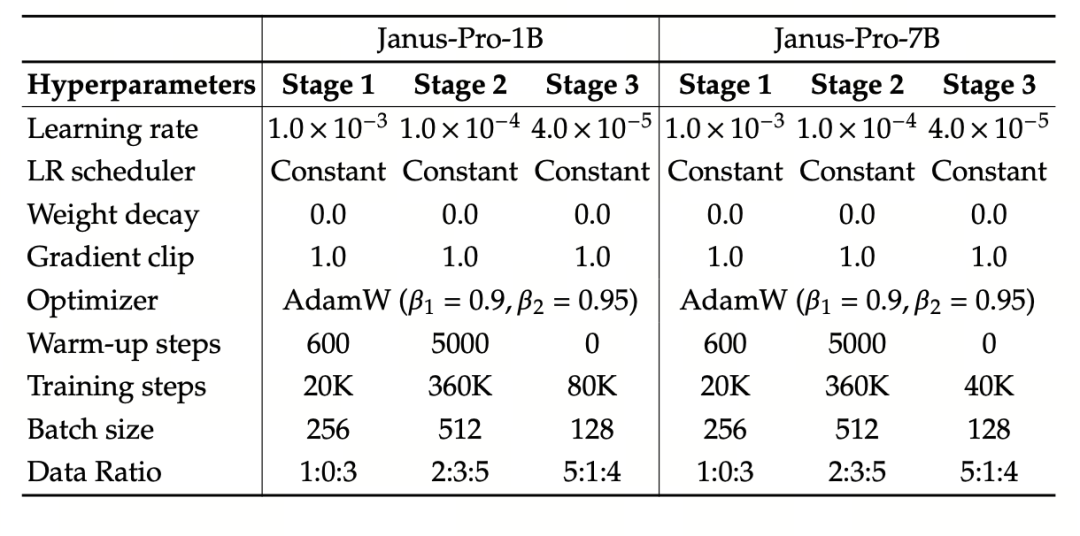
Eksperyment wykorzystuje DeepSeek-LLM (1.5B i 7B, obsługujący maksymalną sekwencję 4096) jako podstawowy model języka. W przypadku zadania rozumienia multimodalnego, SigLIP-Large-Patch16-384 jest używany jako koder wizualny, rozmiar słownika kodera wynosi 16384, wielokrotność próbkowania w dół obrazu wynosi 16, a zarówno adaptery rozumienia, jak i generowania są dwuwarstwowymi MLP.
Etap II uczenia wykorzystuje strategię wczesnego zatrzymania 270K, wszystkie obrazy są jednolicie dostosowane do rozdzielczości 384×384, a sekwencja jest wykorzystywana do poprawy wydajności uczenia. Janus-Pro jest trenowany i oceniany przy użyciu HAI-LLM. Wersje 1.5B/7B były trenowane na 16/32 węzłach (8×Nvidia A100 40GB na węzeł) przez odpowiednio 9/14 dni.
Ocena modelu
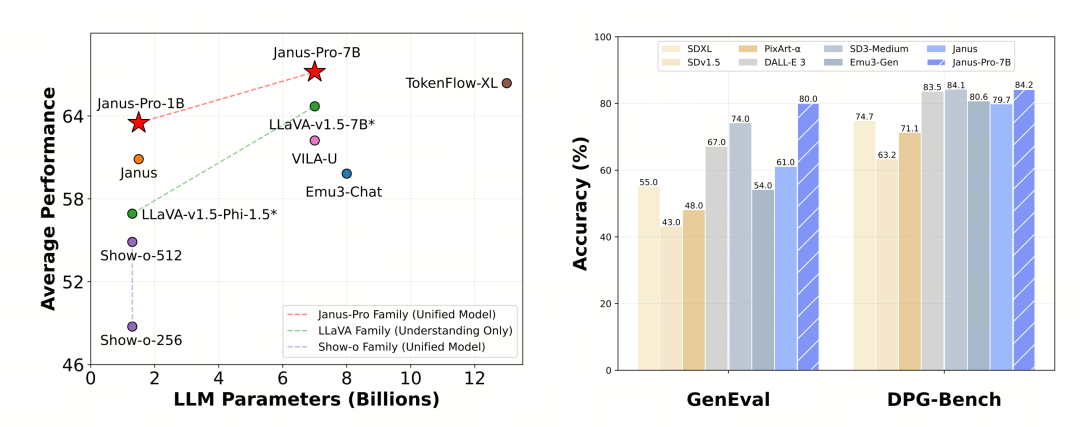
Janus-Pro został oceniony osobno pod kątem multimodalnego rozumienia i generowania. Ogólnie rzecz biorąc, rozumienie może być nieco słabe, ale jest uważane za doskonałe wśród modeli open source o tym samym rozmiarze (należy przypuszczać, że jest ono w dużej mierze ograniczone przez stałą rozdzielczość wejściową i możliwości OCR).
Janus-Pro-7B uzyskał wynik 79,2 pkt. w teście MMBench, który jest zbliżony do poziomu pierwszorzędnych modeli open source (ten sam rozmiar InternVL2.5 i Qwen2-VL to około 82 pkt.). Jest to jednak spora poprawa względem poprzedniej generacji Janusa.
Jeśli chodzi o generowanie obrazu, poprawa w stosunku do poprzedniej generacji jest jeszcze bardziej znacząca i jest uważana za doskonały poziom wśród modeli open source. Wynik Janus-Pro w teście porównawczym GenEval (0,80) również przewyższa modele takie jak DALL-E 3 (0,67) i Stable Diffusion 3 Medium (0,74).