

Viktiga höjdpunkter
🔹 Enhetlig transformatorarkitektur: En enda modell hanterar både bildförståelse och generation, vilket eliminerar behovet av separata system.
🔹 Skalbar och öppen källkod: Tillgänglig i 1B och 7B parameterversioner (MIT-licensierade), optimerade för olika applikationer och kommersiell användning.
🔹 Toppmodern prestanda: överträffar OpenAI:s DALL-E 3 och Stable Diffusion i benchmarks som GenEval och DPG-Bench.
🔹 Förenklad driftsättning: Strömlinjeformad arkitektur minskar kostnaderna för utbildning/inferens samtidigt som flexibiliteten bibehålls.
Länkar till modeller
- Janus-Pro-7B: Kramande ansikte
- Janus-Pro-1B: Kramande ansikte
- GitHub: Kod och dokument
Varför Janus-Pro sticker ut
1. Dubbla superkrafter i en modell
- Förståelse av läget: Användningar SigLIP-L ("superglasögonen") för att analysera bilder (upp till 384×384) och text.
- Generationsläge: Hävstångseffekt Rektifierat flöde + SDXL-VAE (den "magiska penseln") för att skapa högkvalitativa bilder.
2. Hjärnkraft & träning
- Grundläggande LLM: Bygger på DeepSeeks kraftfulla språkmodell (1,5 miljarder/7 miljarder parametrar), som är utmärkt för kontextuella resonemang.
- Utbildning Pipeline: Förträning på massiva datamängder → Övervakad finjustering → EMA-optimering för bästa prestanda.
3. Varför transformator i stället för diffusion?
- Mångsidighet i arbetsuppgifterna: Prioriterar enhetlig förståelse + generering, medan diffusionsmodeller enbart fokuserar på bildkvalitet.
- Effektivitet: Autoregressiv generering (ett steg) jämfört med diffusionens iterativa denoising (t.ex. 20 steg för Stable Diffusion).
- Kostnadseffektivitet: Ett enda Transformer-backbone förenklar utbildning och driftsättning.
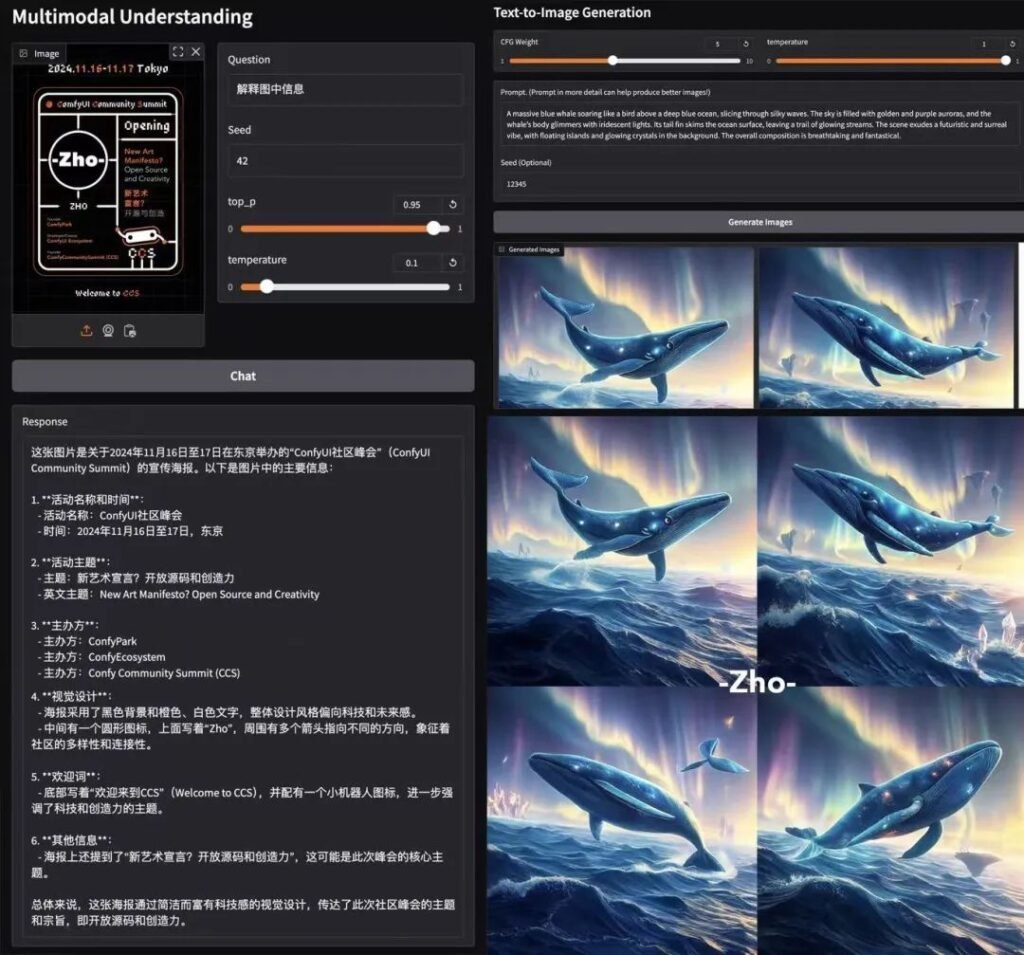
Benchmark-dominans
📊 Multimodal förståelse
Janus-Pro-7B överträffar specialiserade modeller (t.ex. LLaVA) på fyra viktiga riktmärken och skalar jämnt med parameterstorleken.
🎨 Generering av text-till-bild
- GenEval: Motsvarar SDXL och DALL-E 3.
- DPG-bänk: 84,2% noggrannhet (Janus-Pro-7B), vilket överträffar alla konkurrenter.
Testning i den verkliga världen
- Hastighet: ~15 sekunder/bild (L4 GPU, 22 GB VRAM).
- Kvalitet: Mycket snabb efterlevnad, men mindre detaljer behöver finjusteras.
- Colab Demo: Försök Janus-Pro-7B (Pro-nivå krävs).
Teknisk uppdelning
Arkitektur
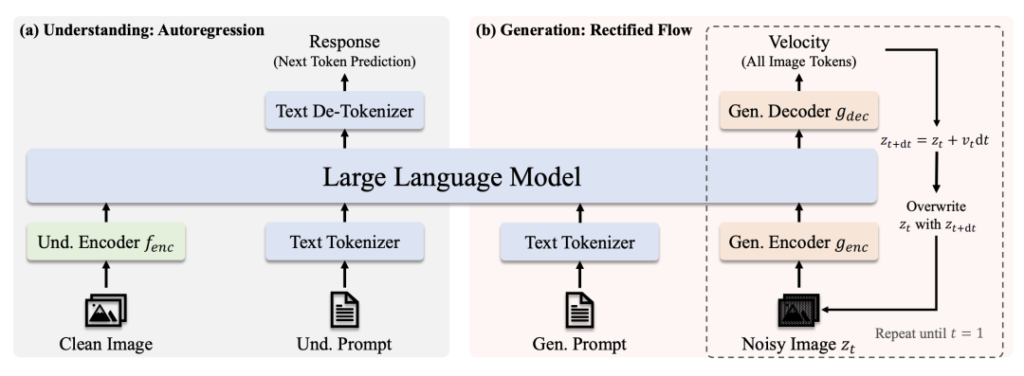
- Förståelse för Path: Ren bild → SigLIP-L-kodare → LLM → Textsvar.
- Generationsväg: Brusig bild → Rektifierad flödesavkodare + LLM → Iterativ denoising.
Viktiga innovationer
- Frikopplad visuell kodning: Separata vägar för förståelse/generering förhindrar "rollkonflikt" i visionsmoduler.
- Delad transformatorkärna: Möjliggör kunskapsöverföring mellan olika uppgifter (t.ex. att lära sig "katt"-begrepp underlättar både igenkänning och ritning).
Samhällsinformation
AK (AI-forskare): "Janus-Pro:s enkelhet och flexibilitet gör den till en utmärkt kandidat för nästa generations multimodala system. Genom att frikoppla synbanorna och samtidigt behålla en enhetlig transformator balanserar den specialisering med generalisering - en sällsynt bedrift."
Varför MIT-licensen är viktig
- Frihet: Använd, modifiera och distribuera kommersiellt med minimala begränsningar.
- Öppenhet: Full kodåtkomst påskyndar förbättringar som drivs av samhället.
Sista ordet
DeepSeeks Janus-Pro är inte bara ytterligare en AI-modell - det är ett paradigmskifte. Genom att förena förståelse och generering under ett tak öppnar den dörrar för smartare kreativa verktyg, realtidsapplikationer och kostnadseffektiva implementeringar. Med tillgång till öppen källkod och MIT-licensering kan detta vara katalysatorn för nästa våg av multimodal innovation. 🚀
För utvecklare: Ta en titt på ComfyUI noder och häng med på experimentvågen!
detta inlägg är sponsrat av:




