
och AI-eran har i tysthet anlänt.
Förmodligen förväntade sig ingen att detta kinesiska nyår, det hetaste ämnet inte längre skulle vara den traditionella Internet-röda kuvertstriden, som samarbetade med Spring Festival Gala, utan AI-företag.
När vårfestivalen närmade sig slappnade de stora modellföretagen inte alls av utan uppdaterade en våg av modeller och produkter. Det mest omtalade var dock DeepSeek, ett "stort modellföretag" som dök upp förra året.
På kvällen den 20 januari, DjupSEek släppte den officiella versionen av sin resonemangsmodell DeepSeek-R1. Med hjälp av en låg utbildningskostnad utbildade den direkt en prestanda som inte är sämre än OpenAI:s resonemangsmodell o1. Dessutom är den helt gratis och öppen källkod, vilket direkt utlöste en jordbävning i branschen.
Det här är första gången som en inhemsk AI har orsakat uppståndelse i teknikvärlden i stor skala runt om i världen, särskilt i USA. Utvecklare har uttryckt att de överväger att använda DeepSeek för att "bygga om allt". I kölvattnet av denna våg, efter en veckas jäsning, och till och med precis släppt i januari, nådde DeepSeek-mobilappen snabbt toppen av gratisapprankingen på Apple App Store i USA och överträffade inte bara ChatGPT utan också andra populära appar i USA.
DeepSeeks framgångar har till och med direkt påverkat den amerikanska aktiemarknaden. En modell som tränats utan att använda en stor mängd dyra GPU:er har fått människor att ompröva träningsvägen för AI, vilket direkt orsakade den största nedgången på 17% i AI:s första aktie, NVIDIA.
Och det är inte allt.
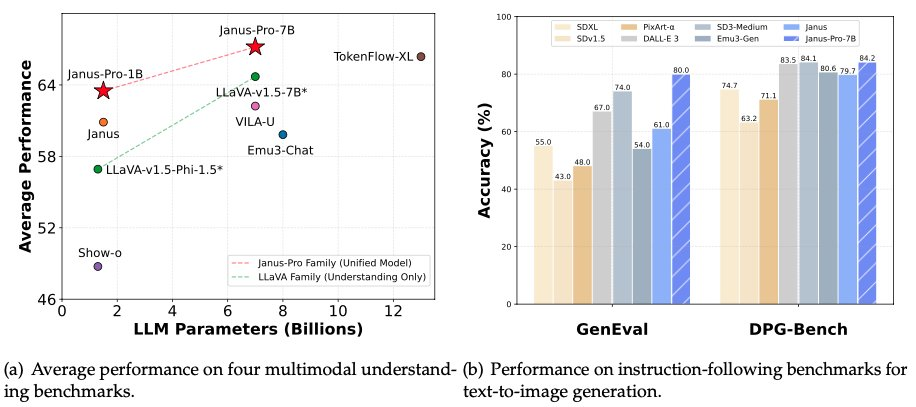
Tidigt på morgonen den 28 januari, kvällen före nyårsafton, öppnade DeepSeek återigen källkod för sin multimodala modell Janus-Pro-7B och meddelade att den hade besegrat DALL-E 3 (från OpenAI) och Stable Diffusion i benchmark-testerna GenEval och DPG-Bench.
Kommer DeepSeek verkligen att svepa över AI-communityn? Från inferensmodeller till multimodala modeller, omstrukturerar DeepSeek allt det första ämnet under ormens år?
Janus Pro, validering av en innovativ multimodal modellarkitektur
DeepSeek släppte totalt två modeller sent på kvällen den här gången: Janus-Pro-7B och Janus-Pro-1B (1,5B parametrar).
Som namnet antyder är modellen i sig en uppgradering från den tidigare Janus-modellen.
DeepSeek släppte Janus-modellen för första gången först i oktober 2024. Som vanligt med DeepSeek har modellen en innovativ arkitektur. I många visionsgenereringsmodeller använder modellen en enhetlig Transformer-arkitektur som samtidigt kan bearbeta uppgifterna text-till-bild och bild-till-text.
DeepSeek föreslår en ny idé, att frikoppla den visuella kodningen av förståelsen (graf-till-text) och genereringsuppgifterna (text-till-graf), vilket förbättrar flexibiliteten i modellutbildningen och effektivt lindrar de konflikter och prestandaflaskhalsar som orsakas av att använda en enda visuell kodning.
Det är därför DeepSeek har döpt modellen till Janus. Janus är den gamla romerska guden för dörrar och avbildas med två ansikten som vetter åt motsatta håll. Enligt DeepSeek har modellen fått namnet Janus eftersom den kan titta på visuella data med olika ögon, koda funktioner separat och sedan använda samma kropp (Transformer) för att bearbeta dessa insignaler.
Denna nya idé har gett goda resultat i Janus-serien av modeller. Teamet säger att Janus-modellen har en stark förmåga att följa kommandon, flerspråkig kapacitet och att modellen är smartare och kan läsa meme-bilder. Den kan också hantera uppgifter som att konvertera latexformler och konvertera grafer till kod.
I modellserien Janus Pro har teamet delvis modifierat modellens träningsprocess, vilket direkt har lett till resultat som slår DALL-E 3 och Stable Diffusion i benchmark-testerna GenEval och DPG-Bench.
Tillsammans med själva modellen har DeepSeek också släppt det nya multimodala AI-ramverket Janus Flow, som syftar till att förena bildförståelse och genereringsuppgifter.
Janus Pro-modellen kan ge stabilare utdata med korta uppmaningar, med bättre visuell kvalitet, rikare detaljer och förmåga att generera enkel text.
Modellen kan generera bilder och beskriva bilder, identifiera landmärken (t.ex. Hangzhous västra sjö), känna igen text i bilder och beskriva kunskap i bilder (t.ex. "Tom och Jerry"-tårtor).
One x.com, Många har redan börjat experimentera med den nya modellen.

Bildigenkänningstestet visas till vänster i figuren ovan, medan bildgenereringstestet visas till höger.

Som synes är Janus Pro också bra på att läsa bilder med hög precision. Den kan känna igen blandad sättning av matematiska uttryck och text. I framtiden kan det vara av större betydelse att använda den med en resonemangsmodell.
Parametrarna i 1B och 7B kan öppna upp för nya applikationsscenarier
I multimodala förståelseuppgifter använder den nya modellen Janus-Pro SigLIP-L som visuell kodare och har stöd för bildinmatningar på 384 x 384 pixlar. I bildgenereringsuppgifter använder Janus-Pro en tokenizer från en specifik källa med en nedsamplingshastighet på 16.
Detta är fortfarande en relativt liten bildstorlek. X Enligt användaranalysen är Janus Pro-modellen mer av en riktad verifiering. Om verifieringen är tillförlitlig kommer en modell som kan sättas i produktion att släppas.
Det är dock värt att notera att den nya modell som Janus lanserade den här gången inte bara är arkitektoniskt innovativ för multimodala modeller, utan också en ny upptäcktsfärd när det gäller antalet parametrar.
Den modell som DeepSeek Janus Pro jämförde den här gången, DALL-E 3, har tidigare meddelat att den hade 12 miljarder parametrar, medan den stora modellen av Janus Pro endast har 7 miljarder parametrar. Med en så kompakt storlek är det redan mycket bra att Janus Pro kan uppnå sådana resultat.
I synnerhet 1B-modellen av Janus Pro använder endast 1,5 miljarder parametrar. Användare har redan lagt till stöd för modellen i transformers.js på det externa nätverket. Detta innebär att modellen nu kan köra 100% i webbläsare på WebGPU!
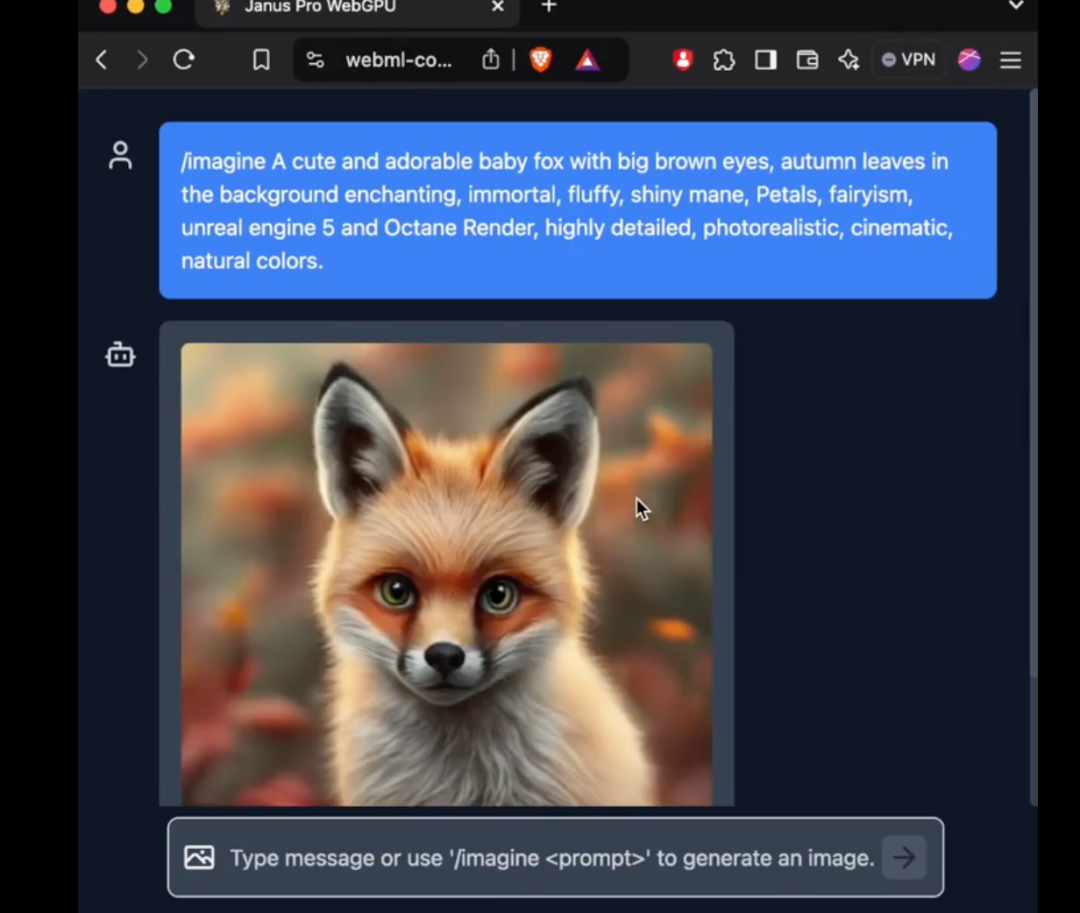
Även om författaren i skrivande stund ännu inte har kunnat använda den nya modellen av Janus Pro på webbversionen, är det faktum att antalet parametrar är tillräckligt litet för att kunna köras direkt på webbsidan fortfarande en fantastisk förbättring.
Detta innebär att kostnaden för bildgenerering/bildförståelse fortsätter att minska. Vi har möjlighet att se användningen av AI på fler ställen där råa bilder och bildförståelse inte kunde användas tidigare, vilket förändrar våra liv.
En viktig hotspot 2024 är hur AI-hårdvara med ökad multimodal förståelse kan ingripa i våra liv. Modeller för multimodal förståelse med allt lägre parametrar, eller modeller som kan förväntas köras på gränsen, kan göra det möjligt för AI-hårdvara att explodera ytterligare.
DeepSeek har rört om i det nya året. Kan allt göras om med kinesisk AI?
AI-världen förändras för varje dag som går.
Runt vårfestivalen förra året var det som rörde upp världen OpenAI: s Sora-modell. Men under årets lopp har kinesiska företag helt kommit ikapp när det gäller videogenerering, vilket gör att lanseringen av Sora i slutet av året verkar lite dyster.
I år har det som rört upp världen varit Kinas DeepSeek.
DeepSeek är inte ett traditionellt teknikföretag, men det har gjort extremt innovativa modeller till en kostnad som är mycket lägre än de stora amerikanska modellföretagens GPU-kort, vilket direkt har chockat de amerikanska motsvarigheterna. Amerikanerna har utropat: "Utbildningen av R1-modellen kostade bara 5,6 miljoner US-dollar, vilket till och med motsvarar lönen för alla chefer i Meta GenAI-teamet. Vad är den här mystiska östliga kraften?"
Ett parodikonto som imiterar DeepSeek-grundaren Liang Wenfeng publicerade en intressant bild direkt på X:

Bilden använde den trendiga meme av den världsberömda turkiska skytten 2024.
I finalen på 10 meter luftpistol i skyttetävlingarna vid OS i Paris tog den 51-årige turkiske skytten Mithat Dikec, som endast bar ett par vanliga närsynta glasögon och ett par sömnöronproppar, lugnt hem silvermedaljen med en hand i fickan. Alla andra närvarande skyttar behövde två professionella linser för fokusering och ljusblockering och ett par bullerdämpande öronproppar för att starta tävlingen.
Sedan DeepSeek "knäckte" OpenAI:s modell för resonemangUnder de senaste veckorna har stora amerikanska teknikföretag utsatts för hård press. Idag svarade Sam Altman äntligen med ett officiellt uttalande.

Kommer 2025 att vara året då kinesisk AI påverkar amerikanska uppfattningar?
DeepSeek har fortfarande en del hemligheter i rockärmen - det här kommer att bli en vårfestival utöver det vanliga.



