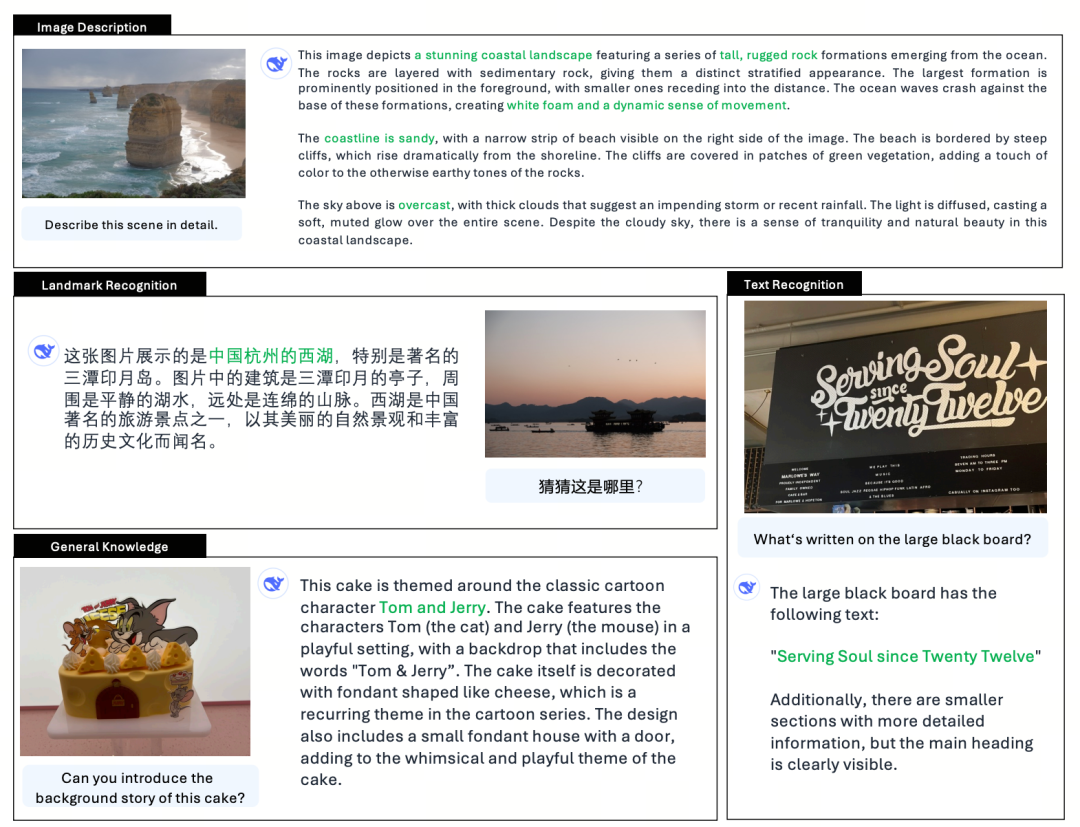
Inför vårfestivalen släpptes modellen DeepSeek-R1. Med sin rena RL-arkitektur har den lärt sig av CoT:s stora innovationer och överträffar ChattGPT i matematik, kod och logiska resonemang.
Dessutom har DeepSeeks modellvikter med öppen källkod, låga utbildningskostnader och billiga API-priser gjort DeepSeek till en succé på internet, vilket till och med fick aktiekurserna för NVIDIA och ASML att sjunka under en tid.
Medan DeepSeek exploderade i popularitet släppte DeepSeek också en uppdaterad version av den multimodala stora modellen Janus (Janus), Janus-Pro, som ärver den enhetliga arkitekturen från den tidigare generationen av multimodal förståelse och generation, och optimerar träningsstrategin, skalar träningsdata och modellstorlek, vilket ger starkare prestanda.

Janus-Pro
Janus-Pro är en enhetlig multimodal språkmodell (MLLM) som samtidigt kan bearbeta multimodala förståelseuppgifter och genereringsuppgifter, dvs. den kan förstå innehållet i en bild och även generera text.
Den frikopplar de visuella kodarna för multimodal förståelse och generering (dvs. olika tokenizers används för inmatningen av bildförståelse och inmatningen och utmatningen av bildgenerering) och bearbetar dem med hjälp av en enhetlig autoregressiv transformator.
Som en avancerad multimodal förståelse- och genereringsmodell är den en uppgraderad version av den tidigare Janus-modellen.
I den romerska mytologin är Janus (Janus) en tvåansiktad skyddsgud som symboliserar motsägelse och övergång. Han har två ansikten, vilket också tyder på att Janus-modellen kan förstå och generera bilder, vilket är mycket lämpligt. Så vad exakt har PRO uppgraderat?
Janus, som en liten modell på 1,3B, är mer som en förhandsversion än en officiell version. Den utforskar enhetlig multimodal förståelse och generering, men har många problem, till exempel instabila bildgenereringseffekter, stora avvikelser från användarinstruktioner och otillräckliga detaljer.
Pro-versionen optimerar träningsstrategin, ökar mängden träningsdata och ger en större modell (7B) att välja mellan samtidigt som den ger en 1B-modell.
Modellarkitektur
Jaus-Pro och Janus är identiska när det gäller modellarkitektur. (Endast 1,3B! Janus förenar multimodal förståelse och generering)
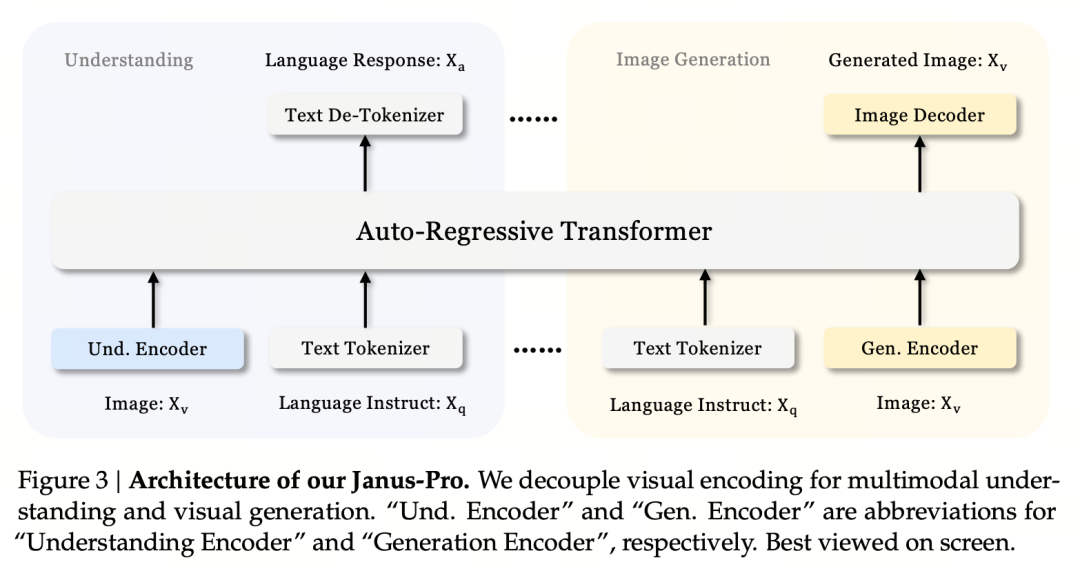
Den grundläggande designprincipen är att frikoppla visuell kodning för att stödja multimodal förståelse och generering. Janus-Pro kodar originalbilden/textinmatningen separat, extraherar högdimensionella funktioner och bearbetar dem genom en enhetlig autoregressiv transformator.
Multimodal bildförståelse använder SigLIP för att koda bildfunktioner (blå kodare i figuren ovan), och genereringsuppgiften använder VQ-tokenizer för att diskretisera bilden (gul kodare i figuren ovan). Slutligen matas alla funktionssekvenser in till LLM för bearbetning
Strategi för utbildning
När det gäller träningsstrategi har Janus-Pro gjort fler förbättringar. I den gamla versionen av Janus användes en träningsstrategi i tre steg, där steg I tränar inmatningsadaptern och bildgenereringshuvudet för bildförståelse och bildgenerering, steg II utför enhetlig förträning och steg III finjusterar förståelsekodaren på grundval av detta. (Janus träningsstrategi visas i figuren nedan).
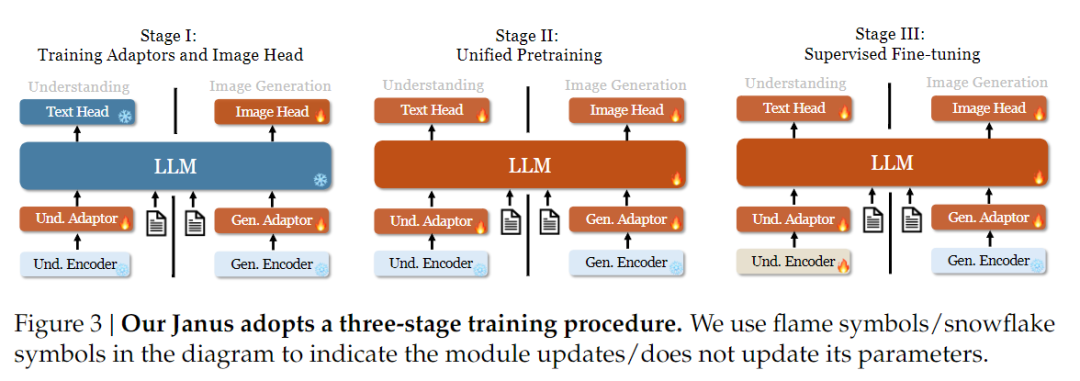
I den här strategin används dock PixArt-metoden för att dela upp träningen av text-till-bild-generering i steg II, vilket resulterar i låg beräkningseffektivitet.
För detta ändamål förlängde vi träningstiden i steg I och lade till träning med ImageNet-data, så att modellen effektivt kan modellera pixelberoenden med fasta LLM-parametrar. I steg II tog vi bort ImageNet-data och använde direkt text-bildpardata för att träna, vilket förbättrar träningseffektiviteten. Dessutom justerade vi dataförhållandet i steg III (multimodal: endast text: visuell-semantisk grafdata från 7:3:10 till 5:1:4), vilket förbättrade multimodal förståelse samtidigt som vi behöll visuell genereringsförmåga.
Skalning av träningsdata
Janus-Pro skalar också upp Janus träningsdata när det gäller multimodal förståelse och visuell generering.
Multimodal förståelse: Förträningsdata för steg II baseras på DeepSeek-VL2 och innehåller cirka 90 miljoner nya prover, inklusive bildtextdata (t.ex. YFCC) och data för tabell-, diagram- och dokumentförståelse (t.ex. Docmatix).
I den övervakade finjusteringsfasen i steg III införs ytterligare MEME-förståelse, kinesiska dialogdata etc. för att förbättra modellens prestanda när det gäller bearbetning av flera uppgifter och dialogfunktioner.
Visuell generering: I tidigare versioner användes verkliga data med låg kvalitet och högt brus, vilket påverkade stabiliteten och estetiken hos de textgenererade bilderna.
Janus-Pro introducerar cirka 72 miljoner syntetiska estetiska data, vilket innebär att förhållandet mellan verkliga data och syntetiska data är 1:1. Experiment har visat att syntetiska data påskyndar modellkonvergensen och avsevärt förbättrar stabiliteten och den estetiska kvaliteten hos de genererade bilderna.
Skalning av modell
Janus Pro utökar modellstorleken till 7B, medan den tidigare versionen av Janus använde 1,5B DeepSeek-LLM för att verifiera effektiviteten i att frikoppla visuell kodning. Experiment visar att en större LLM avsevärt påskyndar konvergensen av multimodal förståelse och visuell generering, vilket ytterligare verifierar metodens starka skalbarhet.

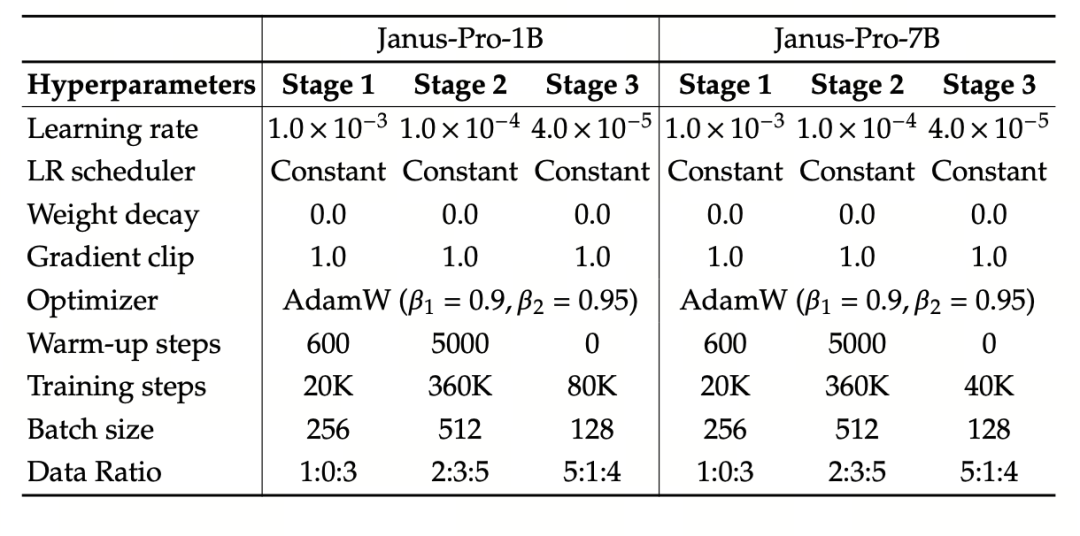
I experimentet används DeepSeek-LLM (1,5B och 7B, med stöd för en maximal sekvens på 4096) som grundläggande språkmodell. För den multimodala förståelseuppgiften används SigLIP-Large-Patch16-384 som visuell kodare, kodarens ordboksstorlek är 16384, bildnedsamplingsmultipeln är 16 och både förståelse- och genereringsadaptrarna är MLP:er i två lager.
Steg II-utbildning använder en 270K tidig stoppstrategi, alla bilder justeras enhetligt till en upplösning på 384 × 384 och sekvensförpackning används för att förbättra utbildningseffektiviteten. Janus-Pro tränas och utvärderas med hjälp av HAI-LLM. Versionerna 1.5B/7B tränades på 16/32 noder (8×Nvidia A100 40GB per nod) under 9/14 dagar.
Utvärdering av modell
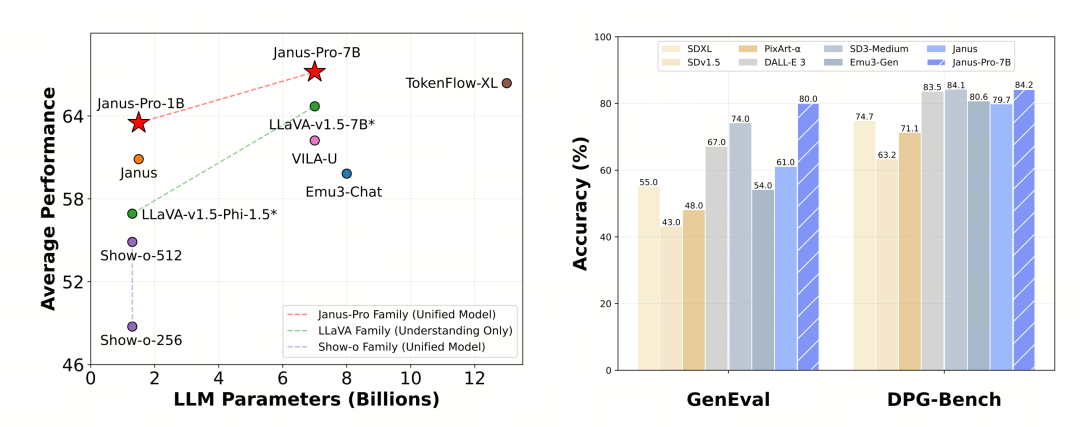
Janus-Pro utvärderades separat för multimodal förståelse och generering. Sammantaget kan förståelsen vara något svag, men den anses vara utmärkt bland modeller med öppen källkod av samma storlek (antar att den till stor del begränsas av den fasta inmatningsupplösningen och OCR-funktionerna).
Janus-Pro-7B fick 79,2 poäng i MMBench benchmark-test, vilket är nära nivån för förstklassiga modeller med öppen källkod (samma storlek på InternVL2.5 och Qwen2-VL är cirka 82 poäng). Det är dock en bra förbättring jämfört med den tidigare generationen av Janus.
När det gäller bildgenerering är förbättringen jämfört med föregående generation ännu mer betydande, och det anses vara en utmärkt nivå bland modeller med öppen källkod. Janus-Pro:s resultat i benchmark-testet GenEval (0,80) överträffar också modeller som DALL-E 3 (0,67) och Stable Diffusion 3 Medium (0,74).