

Vigtige højdepunkter
🔹 Samlet transformer-arkitektur: En enkelt model håndterer både billedforståelse og generation, hvilket eliminerer behovet for separate systemer.
🔹 Skalerbar og open source: Tilgængelig i 1B og 7B parameterversioner (MIT-licens), optimeret til forskellige anvendelser og kommerciel brug.
🔹 Topmoderne ydeevne: Overgår OpenAI's DALL-E 3 og Stable Diffusion i benchmarks som GenEval og DPG-Bench.
🔹 Forenklet udrulning: Strømlinet arkitektur reducerer omkostningerne til træning/instruktion, samtidig med at fleksibiliteten bevares.
Model-links
- Janus-Pro-7B: HuggingFace
- Janus-Pro-1B: HuggingFace
- GitHub: Kode og dokumenter
Hvorfor Janus-Pro skiller sig ud
1. To superkræfter i én model
- Forståelse af tilstand: Anvendelser SigLIP-L ("superbrillerne") til at analysere billeder (op til 384×384) og tekst.
- Generationstilstand: Løftestænger Rektificeret flow + SDXL-VAE (den "magiske pensel") til at skabe billeder i høj kvalitet.
2. Hjernekraft og træning
- Grundlæggende LLM: Bygget på DeepSeeks kraftfulde sprogmodel (1,5B/7B parametre), der udmærker sig ved kontekstuel ræsonnering.
- Uddannelse i pipeline: Forudgående træning på massive datasæt → Overvåget finjustering → EMA-optimering for maksimal ydeevne.
3. Hvorfor transformator-overdiffusion?
- Alsidighed i opgaverne: Prioriterer samlet forståelse + generering, mens diffusionsmodeller udelukkende fokuserer på billedkvalitet.
- Effektivitet: Autoregressiv generering (enkelt trin) vs. diffusionens iterative denoising (f.eks. 20 trin for stabil diffusion).
- Omkostningseffektivitet: Et enkelt Transformer-backbone forenkler træning og implementering.
Benchmark-dominans
📊 Multimodal forståelse
Janus-Pro-7B overgår specialiserede modeller (f.eks. LLaVA) på fire vigtige benchmarks og skalerer jævnt med parameterstørrelsen.
🎨 Tekst-til-billede-generering
- GenEval: Matcher SDXL og DALL-E 3.
- DPG-Bench: 84.2% nøjagtighed (Janus-Pro-7B), hvilket overgår alle konkurrenter.
Test i den virkelige verden
- Hastighed: ~15 sekunder/billede (L4 GPU, 22 GB VRAM).
- Kvalitet: Stærk hurtig overholdelse, selvom mindre detaljer skal finpudses.
- Colab Demo: Prøv Janus-Pro-7B (Pro-niveau påkrævet).
Teknisk opdeling
Arkitektur
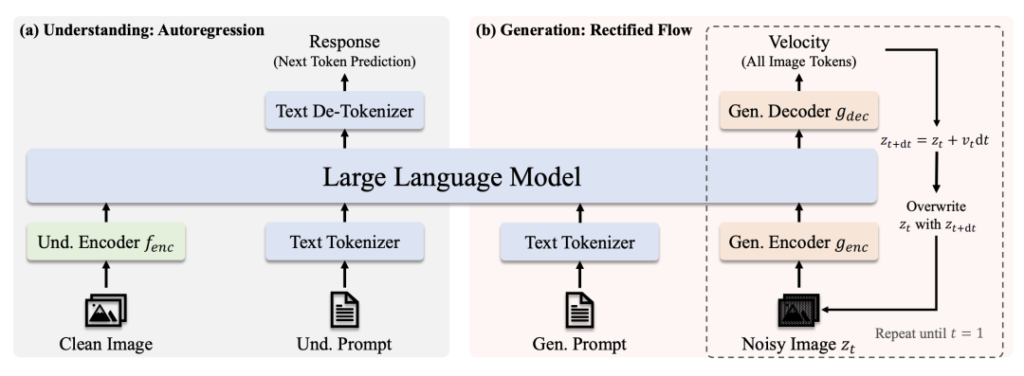
- Forståelse af stien: Rent billede → SigLIP-L-koder → LLM → Tekstsvar.
- Generationsvej: Støjende billede → Rectified Flow-dekoder + LLM → Iterativ denoising.
Vigtige innovationer
- Afkoblet visuel kodning: Separate veje til forståelse/generering forhindrer "rollekonflikt" i synsmoduler.
- Delt transformatorkerne: Muliggør overførsel af viden på tværs af opgaver (f.eks. hjælper indlæring af "katte"-begreber både med genkendelse og tegning).
Fællesskabsbuzz
AK (AI-forsker): "Janus-Pro's enkelhed og fleksibilitet gør den til en førsteklasses kandidat til næste generations multimodale systemer. Ved at afkoble synsbaner og samtidig beholde en samlet Transformer, afbalancerer den specialisering med generalisering - en sjælden bedrift."
Hvorfor MIT-licensen er vigtig
- Frihed: Brug, modificer og distribuer kommercielt med minimale begrænsninger.
- Gennemsigtighed: Fuld adgang til koden fremskynder samfundsdrevne forbedringer.
Sidste udspil
DeepSeeks Janus-Pro er ikke bare endnu en AI-model - det er et paradigmeskift. Ved at forene forståelse og generering under ét tag åbner den døre for smartere kreative værktøjer, realtidsapplikationer og omkostningseffektive implementeringer. Med open source-adgang og MIT-licens kan dette være katalysatoren for den næste bølge af multimodal innovation. 🚀
Til udviklere: Tjek den nye ComfyUI-noder og kom med på eksperimenteringsbølgen!
Dette indlæg er sponsoreret af:



