
og AI-æraen er stille og roligt kommet.
Der var nok ingen, der forventede, at det hotteste emne dette kinesiske nytår ikke længere ville være den traditionelle kamp om internettets røde konvolut, der samarbejdede med Spring Festival Gala, men AI-virksomheder.
Da forårsfestivalen nærmede sig, slappede de store modelfirmaer slet ikke af og opdaterede en bølge af modeller og produkter. Den mest omtalte var dog DeepSeek, et "stort modelfirma", der opstod sidste år.
Om aftenen den 20. januar, DybSEek udgav den officielle version af sin ræsonneringsmodel DeepSeek-R1. Ved hjælp af lave træningsomkostninger trænede den direkte en præstation, der ikke er ringere end OpenAI's ræsonneringsmodel o1. Desuden er den helt gratis og open source, hvilket direkte udløste et jordskælv i branchen.
Det er første gang, at en indenlandsk AI har skabt røre i teknologiverdenen i stor skala over hele verden, især i USA. Udviklere har givet udtryk for, at de overvejer at bruge DeepSeek til at "genopbygge alt". I kølvandet på denne bølge nåede DeepSeek-mobilappen efter en uges gæring og endda først udgivet i januar hurtigt toppen af ranglisten over gratis apps i Apple App Store i USA og overgik ikke kun ChatGPT, men også andre populære apps i USA.
DeepSeeks succes har endda direkte påvirket det amerikanske aktiemarked. En model, der er trænet uden brug af en enorm mængde dyre GPU'er, har fået folk til at genoverveje træningsvejen for AI, hvilket direkte har forårsaget det største fald på 17% i AI's første aktie, NVIDIA.
Og det er ikke alt.
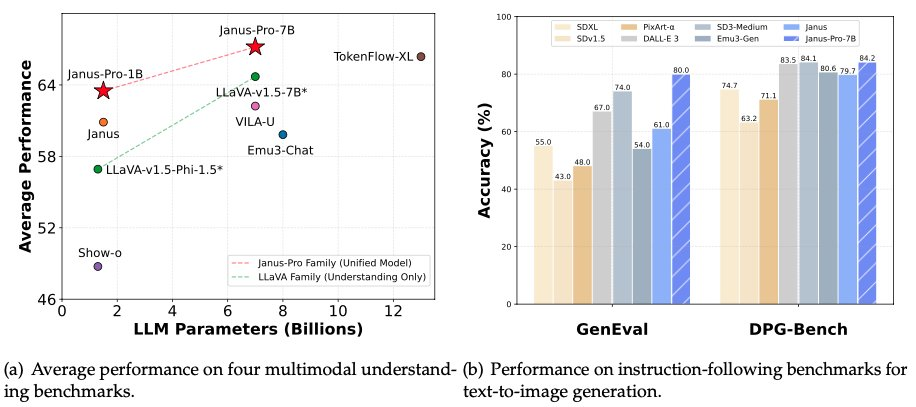
Tidligt om morgenen den 28. januar, aftenen før nytårsaften, åbnede DeepSeek igen kildekoden til sin multimodale model Janus-Pro-7B og meddelte, at den havde besejret DALL-E 3 (fra OpenAI) og Stable Diffusion i benchmark-testene GenEval og DPG-Bench.
Kommer DeepSeek virkelig til at feje AI-samfundet? Fra inferensmodeller til multimodale modeller - er DeepSeek ved at omstrukturere alt det første emne i slangens år?
Janus Provalidering af en innovativ multimodal modelarkitektur
DeepSeek frigav i alt to modeller sent om aftenen denne gang: Janus-Pro-7B og Janus-Pro-1B (1,5B parametre).
Som navnet antyder, er selve modellen en opgradering af den tidligere Janus-model.
DeepSeek udgav først Janus-modellen for første gang i oktober 2024. Som sædvanlig med DeepSeek har modellen en innovativ arkitektur. I mange visionsgenereringsmodeller anvender modellen en samlet Transformer-arkitektur, der samtidig kan behandle opgaverne tekst-til-billede og billede-til-tekst.
DeepSeek foreslår en ny idé, der afkobler den visuelle kodning af forståelses- (graf-til-tekst) og genereringsopgaverne (tekst-til-graf), hvilket forbedrer fleksibiliteten i modeltræningen og effektivt afhjælper de konflikter og flaskehalse i ydeevnen, der forårsages af at bruge en enkelt visuel kodning.
Det er derfor, DeepSeek har givet modellen navnet Janus. Janus er den gamle romerske gud for døre og er afbildet med to ansigter, der vender i hver sin retning. DeepSeek sagde, at modellen hedder Janus, fordi den kan se på visuelle data med forskellige øjne, kode funktioner separat og derefter bruge den samme krop (Transformer) til at behandle disse inputsignaler.
Denne nye idé har givet gode resultater i Janus-serien af modeller. Teamet siger, at Janus-modellen har stærke evner til at følge kommandoer, flersprogede evner, og modellen er smartere og i stand til at læse meme-billeder. Den kan også håndtere opgaver som konvertering af latexformler og konvertering af grafer til kode.
I Janus Pro-serien af modeller har teamet delvist ændret modellens træningsproces, hvilket direkte har givet resultater, der slår DALL-E 3 og Stable Diffusion i GenEval- og DPG-Bench-benchmarktestene.
Sammen med selve modellen har DeepSeek også udgivet den nye multimodale AI-ramme Janus Flow, som har til formål at forene billedforståelses- og genereringsopgaver.
Janus Pro-modellen kan give et mere stabilt output ved hjælp af korte instruktioner, med bedre visuel kvalitet, flere detaljer og mulighed for at generere enkel tekst.
Modellen kan generere billeder og beskrive billeder, identificere seværdigheder (f.eks. Hangzhou's West Lake), genkende tekst i billeder og beskrive viden i billeder (f.eks. "Tom og Jerry"-kager).
One x.com, Mange mennesker er allerede begyndt at eksperimentere med den nye model.

Billedgenkendelsestesten er vist til venstre i figuren ovenfor, mens billedgenereringstesten er vist til højre.

Som man kan se, er Janus Pro også god til at læse billeder med høj præcision. Den kan genkende blandede sætninger af matematiske udtryk og tekst. I fremtiden kan det være af større betydning at bruge den sammen med en ræsonneringsmodel.
Parametrene i 1B og 7B kan åbne op for nye anvendelsesscenarier
I multimodale forståelsesopgaver bruger den nye model Janus-Pro SigLIP-L som visuel koder og understøtter billedinput på 384 x 384 pixels. I billedgenereringsopgaver bruger Janus-Pro en tokenizer fra en specifik kilde med en downsampling-hastighed på 16.
Det er stadig en relativt lille billedstørrelse. X I brugeranalysen er Janus Pro-modellen mere en retningsbestemt verifikation. Hvis verifikationen er pålidelig, vil der blive frigivet en model, der kan sættes i produktion.
Det er dog værd at bemærke, at den nye model, som Janus har lanceret denne gang, ikke kun er arkitektonisk innovativ for multimodale modeller, men også en ny udforskning med hensyn til antallet af parametre.
Den model, som DeepSeek Janus Pro sammenligner med denne gang, DALL-E 3, har tidligere meddelt, at den havde 12 milliarder parametre, mens den store model i Janus Pro kun har 7 milliarder parametre. Med en så kompakt størrelse er det allerede meget godt, at Janus Pro kan opnå sådanne resultater.
Især 1B-modellen af Janus Pro bruger kun 1,5 milliarder parametre. Brugere har allerede tilføjet understøttelse af modellen til transformers.js på det eksterne netværk. Det betyder, at modellen nu kan køre 100% i browsere på WebGPU!
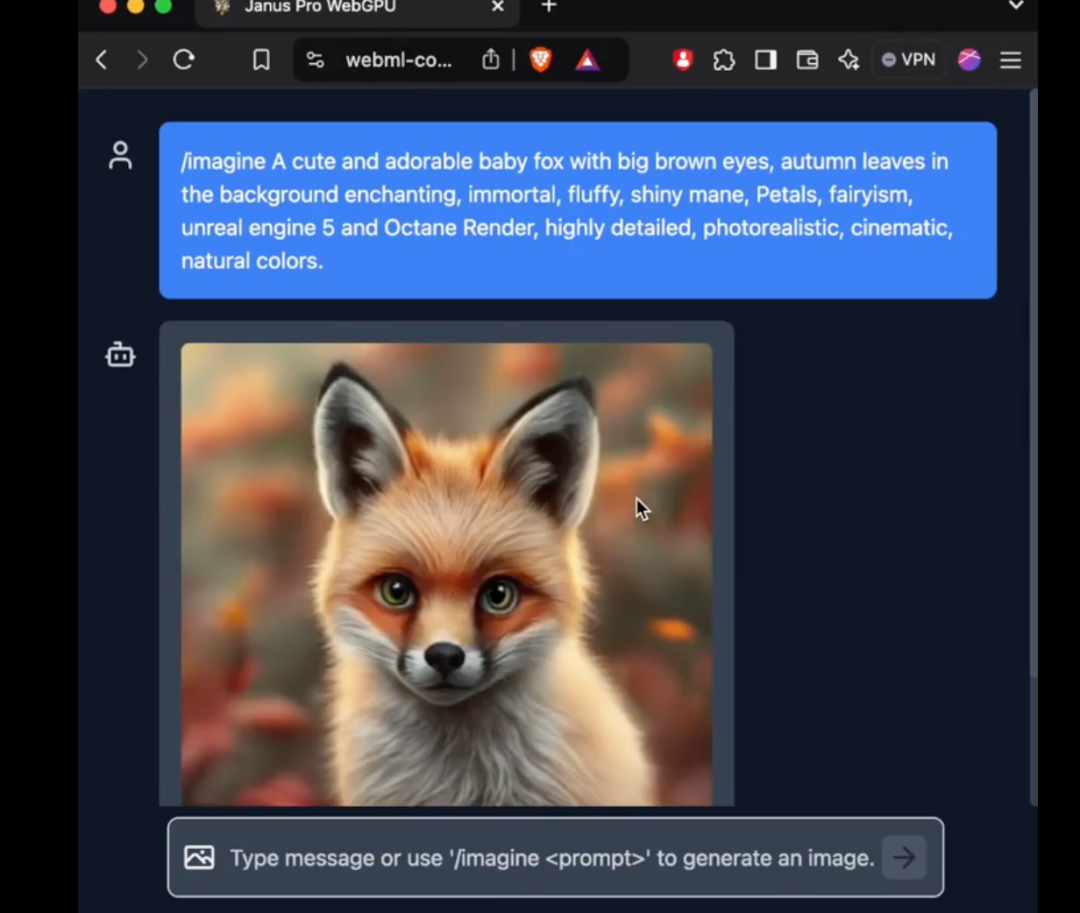
Selvom forfatteren ved redaktionens slutning endnu ikke har været i stand til at bruge den nye model af Janus Pro på webversionen, er det stadig en fantastisk forbedring, at antallet af parametre er lille nok til at køre direkte på websiden.
Det betyder, at omkostningerne til billedgenerering/billedeforståelse fortsætter med at falde. Vi har mulighed for at se brugen af AI flere steder, hvor rå billeder og billedforståelse ikke kunne bruges før, og det vil ændre vores liv.
Et stort hotspot i 2024 ligger i, hvordan AI-hardware med ekstra multimodal forståelse kan gribe ind i vores liv. Multimodale forståelsesmodeller med stadig lavere parametre, eller modeller, der kan forventes at køre på kanten, kan gøre det muligt for AI-hardware at eksplodere yderligere.
DeepSeek har sat gang i det nye år. Kan alting gøres om med kinesisk AI?
AI-verdenen ændrer sig dag for dag.
Omkring forårsfestivalen sidste år var det OpenAI's Sora-model, der fik verden til at røre på sig. Men i løbet af året har kinesiske virksomheder fuldstændig indhentet dem med hensyn til videoproduktion, hvilket får udgivelsen af Sora i slutningen af året til at se lidt dyster ud.
I år er det Kinas DeepSeek, der har fået verden til at røre på sig.
DeepSeek er ikke en traditionel teknologivirksomhed, men den har lavet ekstremt innovative modeller til en pris, der er langt lavere end de store amerikanske modelfirmaers GPU-kort, hvilket direkte har chokeret de amerikanske kolleger. Amerikanerne har udbrudt: "Træningen af R1-modellen kostede kun 5,6 millioner amerikanske dollars, hvilket endda svarer til lønnen for enhver leder i Meta GenAI-teamet. Hvad er denne mystiske østlige kraft?"
En parodikonto, der efterligner DeepSeek-grundlæggeren Liang Wenfeng, lagde et interessant billede op direkte på X:

Billedet brugte det populære meme af den verdensberømte tyrkiske skytte i 2024.
I finalen i 10 meter luftpistol ved skydekonkurrencerne ved OL i Paris tog den 51-årige tyrkiske skytte Mithat Dikec, der kun havde et par almindelige nærsynede briller og et par soveørepropper på, roligt sølvmedaljen med en enkelt hånd i lommen. Alle de andre skytter havde brug for to professionelle linser til fokusering og lysblokering og et par støjreducerende ørepropper for at kunne starte konkurrencen.
Siden DeepSeek "knækkede" OpenAI's ræsonneringsmodelI dag er store amerikanske teknologivirksomheder kommet under voldsomt pres. I dag reagerede Sam Altman endelig med en officiel udtalelse.

Bliver 2025 året, hvor kinesisk AI påvirker amerikanske opfattelser?
DeepSeek har stadig nogle hemmeligheder i ærmet - det bliver en ekstraordinær forårsfestival.


