
e l'era dell'intelligenza artificiale è arrivata silenziosamente.
Probabilmente nessuno si aspettava che questo Capodanno cinese, l'argomento più caldo non sarebbe stato più la tradizionale battaglia delle buste rosse di Internet, che ha collaborato con il Gala della Festa di Primavera, ma le aziende di AI.
Con l'avvicinarsi del Festival di Primavera, le principali aziende di modelli non si sono affatto rilassate, aggiornando un'ondata di modelli e prodotti. Tuttavia, la più chiacchierata è stata DeepSeek, una "grande azienda di modelli" emersa lo scorso anno.
La sera del 20 gennaio, ProfondoSeek ha rilasciato la versione ufficiale del suo modello di ragionamento DeepSeek-R1. Utilizzando un basso costo di addestramento, ha direttamente formato una performance che non è inferiore al modello di ragionamento OpenAI o1. Inoltre, è completamente gratuito e open source, il che ha scatenato un terremoto nel settore.
È la prima volta che un'intelligenza artificiale nazionale suscita scalpore nel mondo tecnologico su larga scala, soprattutto negli Stati Uniti. Gli sviluppatori hanno dichiarato che stanno pensando di utilizzare DeepSeek per "ricostruire tutto". Sulla scia di questa ondata, dopo una settimana di fermentazione, e anche appena rilasciata a gennaio, l'applicazione mobile DeepSeek ha rapidamente raggiunto la vetta della classifica delle applicazioni gratuite sull'App Store di Apple negli Stati Uniti, superando non solo ChatGPT, ma anche altre applicazioni popolari negli Stati Uniti.
Il successo di DeepSeek ha persino influenzato direttamente il mercato azionario statunitense. Un modello addestrato senza l'utilizzo di un'enorme quantità di costose GPU ha fatto ripensare il percorso di addestramento dell'IA, causando direttamente il più grande calo di 17% nel primo titolo dell'IA, NVIDIA.
E non è tutto.
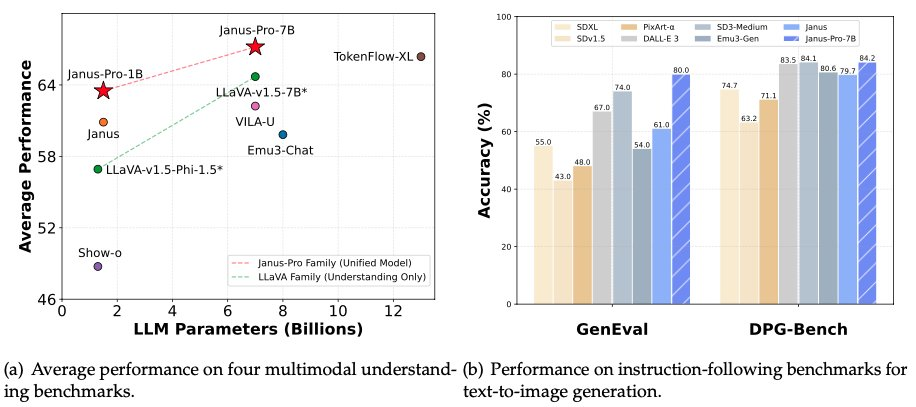
Nella prima mattinata del 28 gennaio, la notte prima di Capodanno, DeepSeek ha nuovamente reso disponibile il suo modello multimodale Janus-Pro-7B, annunciando di aver sconfitto DALL-E 3 (di OpenAI) e Stable Diffusion nei test di benchmark GenEval e DPG-Bench.
DeepSeek sta davvero per travolgere la comunità dell'IA? Dai modelli di inferenza ai modelli multimodali, DeepSeek sta ristrutturando tutto il primo argomento dell'Anno del Serpente?
Janus Pro, la validazione di un'innovativa architettura di modello multimodale
Questa volta DeepSeek ha rilasciato in totale due modelli a notte fonda: Janus-Pro-7B e Janus-Pro-1B (parametri 1,5B).
Come suggerisce il nome, il modello stesso è un aggiornamento del precedente modello Janus.
DeepSeek ha rilasciato il modello Janus per la prima volta solo nell'ottobre 2024. Come di consueto per DeepSeek, il modello adotta un'architettura innovativa. In molti modelli di generazione della visione, il modello adotta un'architettura Transformer unificata che può elaborare simultaneamente i compiti di text-to-image e image-to-text.
DeepSeek propone una nuova idea, disaccoppiando la codifica visiva dei compiti di comprensione (da grafo a testo) e di generazione (da testo a grafico), che migliora la flessibilità dell'addestramento del modello e allevia efficacemente i conflitti e i colli di bottiglia delle prestazioni causati dall'uso di un'unica codifica visiva.
Per questo DeepSeek ha chiamato il modello Giano. Giano è l'antico dio romano delle porte ed è raffigurato con due facce rivolte in direzioni opposte. DeepSeek ha detto che il modello si chiama Giano perché può guardare i dati visivi con occhi diversi, codificare le caratteristiche separatamente e poi usare lo stesso corpo (Transformer) per elaborare questi segnali di input.
Questa nuova idea ha prodotto buoni risultati nella serie di modelli Janus. Il team afferma che il modello Janus ha una forte capacità di seguire i comandi, è multilingue ed è più intelligente, in grado di leggere le immagini dei meme. È anche in grado di gestire compiti come la conversione di formule in lattice e la conversione di grafici in codice.
Nella serie di modelli Janus Pro, il team ha modificato parzialmente il processo di addestramento del modello, ottenendo direttamente risultati che hanno battuto DALL-E 3 e Stable Diffusion nei test di benchmark GenEval e DPG-Bench.
Oltre al modello stesso, DeepSeek ha rilasciato anche il nuovo framework di AI multimodale Janus Flow, che mira a unificare i compiti di comprensione e generazione delle immagini.
Il modello Janus Pro è in grado di fornire un output più stabile utilizzando prompt brevi, con una migliore qualità visiva, dettagli più ricchi e la capacità di generare testo semplice.
Il modello è in grado di generare immagini e descrivere immagini, identificare attrazioni di riferimento (come il Lago Ovest di Hangzhou), riconoscere testi nelle immagini e descrivere conoscenze nelle immagini (come le torte di "Tom e Jerry").
One x.com, Molte persone hanno già iniziato a sperimentare il nuovo modello.

Il test di riconoscimento delle immagini è mostrato a sinistra nella figura precedente, mentre il test di generazione delle immagini è mostrato a destra.

Come si può notare, l'Janus Pro svolge anche un buon lavoro di lettura delle immagini con elevata precisione. È in grado di riconoscere i caratteri misti di espressioni matematiche e testo. In futuro, potrebbe essere più importante utilizzarlo con un modello di ragionamento.
I parametri di 1B e 7B possono aprire nuovi scenari di applicazione
Nei compiti di comprensione multimodale, il nuovo modello Janus-Pro utilizza SigLIP-L come codificatore visivo e supporta immagini di 384 x 384 pixel. Nei compiti di generazione delle immagini, Janus-Pro utilizza un tokenizer da una fonte specifica con una velocità di downsampling di 16.
Si tratta comunque di un'immagine di dimensioni relativamente ridotte. X Per quanto riguarda l'analisi dell'utente, il modello Janus Pro è più che altro una verifica direzionale. Se la verifica è affidabile, verrà rilasciato un modello che potrà essere messo in produzione.
Tuttavia, vale la pena notare che il nuovo modello rilasciato da Janus questa volta non è solo architettonicamente innovativo per i modelli multimodali, ma anche una nuova esplorazione in termini di numero di parametri.
Il modello confrontato da DeepSeek Janus Pro questa volta, DALL-E 3, aveva precedentemente annunciato di avere 12 miliardi di parametri, mentre il modello di grandi dimensioni dell'Janus Pro ne ha solo 7 miliardi. Con dimensioni così compatte, è già molto che l'Janus Pro possa raggiungere tali risultati.
In particolare, il modello 1B di Janus Pro utilizza solo 1,5 miliardi di parametri. Gli utenti hanno già aggiunto il supporto per il modello a transformers.js sulla rete esterna. Ciò significa che il modello può ora eseguire 100% nei browser su WebGPU!
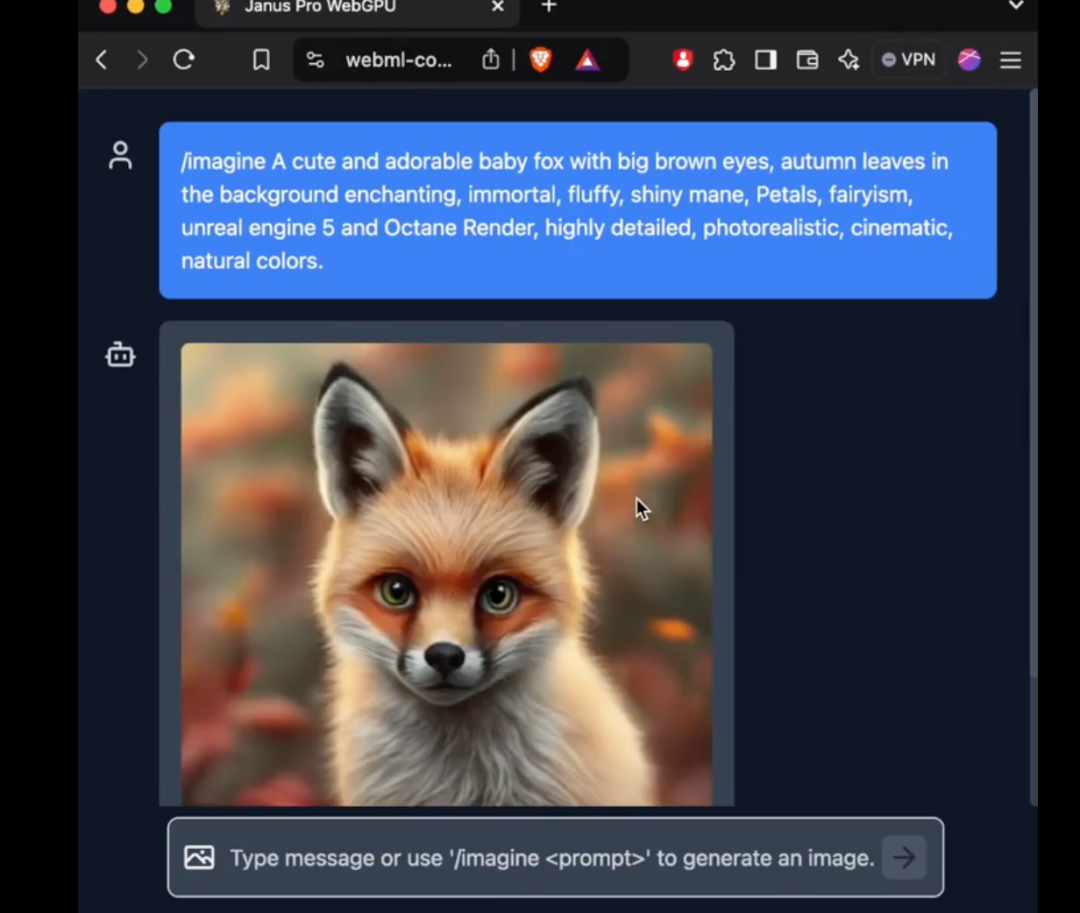
Sebbene al momento della stampa l'autore non sia ancora riuscito a utilizzare con successo il nuovo modello di Janus Pro sulla versione web, il fatto che il numero di parametri sia abbastanza ridotto da poter essere eseguito direttamente sul web è comunque un miglioramento sorprendente.
Ciò significa che il costo della generazione e della comprensione delle immagini continua a diminuire. Abbiamo l'opportunità di vedere l'uso dell'IA in un numero maggiore di luoghi in cui le immagini grezze e la comprensione delle immagini non potevano essere utilizzate prima, cambiando le nostre vite.
Uno dei principali punti di interesse nel 2024 è il modo in cui l'hardware dell'IA con una maggiore comprensione multimodale può intervenire nella nostra vita. I modelli di comprensione multimodale con parametri sempre più bassi, o i modelli che possono essere eseguiti ai margini, possono consentire all'hardware di IA di esplodere ulteriormente.
DeepSeek ha dato una scossa al nuovo anno. Si può rifare tutto con l'intelligenza artificiale cinese?
Il mondo dell'intelligenza artificiale cambia di giorno in giorno.
L'anno scorso, in occasione del Festival di Primavera, il modello Sora di OpenAI ha fatto scalpore in tutto il mondo. Tuttavia, nel corso dell'anno, le aziende cinesi hanno completamente recuperato terreno in termini di generazione di video, facendo sembrare un po' improbabile il rilascio di Sora alla fine dell'anno.
Quest'anno, a far scalpore è stato il DeepSeek cinese.
DeepSeek non è un'azienda tecnologica tradizionale, ma ha realizzato modelli estremamente innovativi a un costo di gran lunga inferiore a quello delle schede GPU delle principali aziende americane, il che ha scioccato direttamente le controparti americane. Gli americani hanno esclamato: "L'addestramento del modello R1 è costato solo 5,6 milioni di dollari, che equivalgono addirittura allo stipendio di qualsiasi dirigente del team Meta GenAI. Cos'è questa misteriosa potenza orientale?".
Un account parodia che imita il fondatore di DeepSeek, Liang Wenfeng, ha postato un'immagine interessante direttamente su X:

L'immagine utilizzava il meme di tendenza del tiratore turco di fama mondiale nel 2024.
Nella finale di pistola ad aria compressa da 10 metri delle Olimpiadi di Parigi, il tiratore turco Mithat Dikec, 51 anni, che indossava solo un paio di occhiali da miope ordinari e un paio di tappi per le orecchie per dormire, ha intascato con calma la medaglia d'argento con una sola mano in tasca. Tutti gli altri tiratori presenti avevano bisogno di due lenti professionali per la messa a fuoco e il blocco della luce e di un paio di tappi per le orecchie a cancellazione del rumore per iniziare la gara.
Da quando DeepSeek ha "craccato" Il modello di ragionamento di OpenAI, le principali aziende tecnologiche statunitensi sono state sottoposte a forti pressioni. Oggi Sam Altman ha finalmente risposto con una dichiarazione ufficiale.

Il 2025 sarà l'anno in cui l'IA cinese avrà un impatto sulle percezioni americane?
DeepSeek ha ancora qualche segreto nella manica: questo è destinato a essere uno straordinario Festival di Primavera.


