DeepSeek ha aggiornato il suo sito web.
Nelle prime ore della notte di Capodanno, DeepSeek ha improvvisamente annunciato su GitHub che lo spazio del progetto Janus aveva aperto la fonte del modello Janus-Pro e del rapporto tecnico.
Innanzitutto, sottolineiamo alcuni punti chiave:
- Il Modello Janus-Pro Questa volta è stato rilasciato un modello multimodale che è in grado di eseguire simultaneamente compiti di comprensione multimodale e di generazione di immagini. Ha un totale di due versioni di parametri, Janus-Pro-1B e Janus-Pro-7B.
- L'innovazione principale dell'Janus-Pro è quella di disaccoppiare comprensione e generazione multimodale, due compiti diversi. Ciò consente di completare in modo efficiente questi due compiti nello stesso modello..
- Janus-Pro è coerente con l'architettura del modello Janus rilasciato da DeepSeek lo scorso ottobre, ma all'epoca Janus non aveva un volume elevato. Il dottor Charles, esperto di algoritmi nel campo della visione, ci ha detto che il precedente Janus era "medio" e "non buono come il modello linguistico di DeepSeek".

L'obiettivo è quello di risolvere il difficile problema del settore: bilanciare la comprensione multimodale e la generazione di immagini.
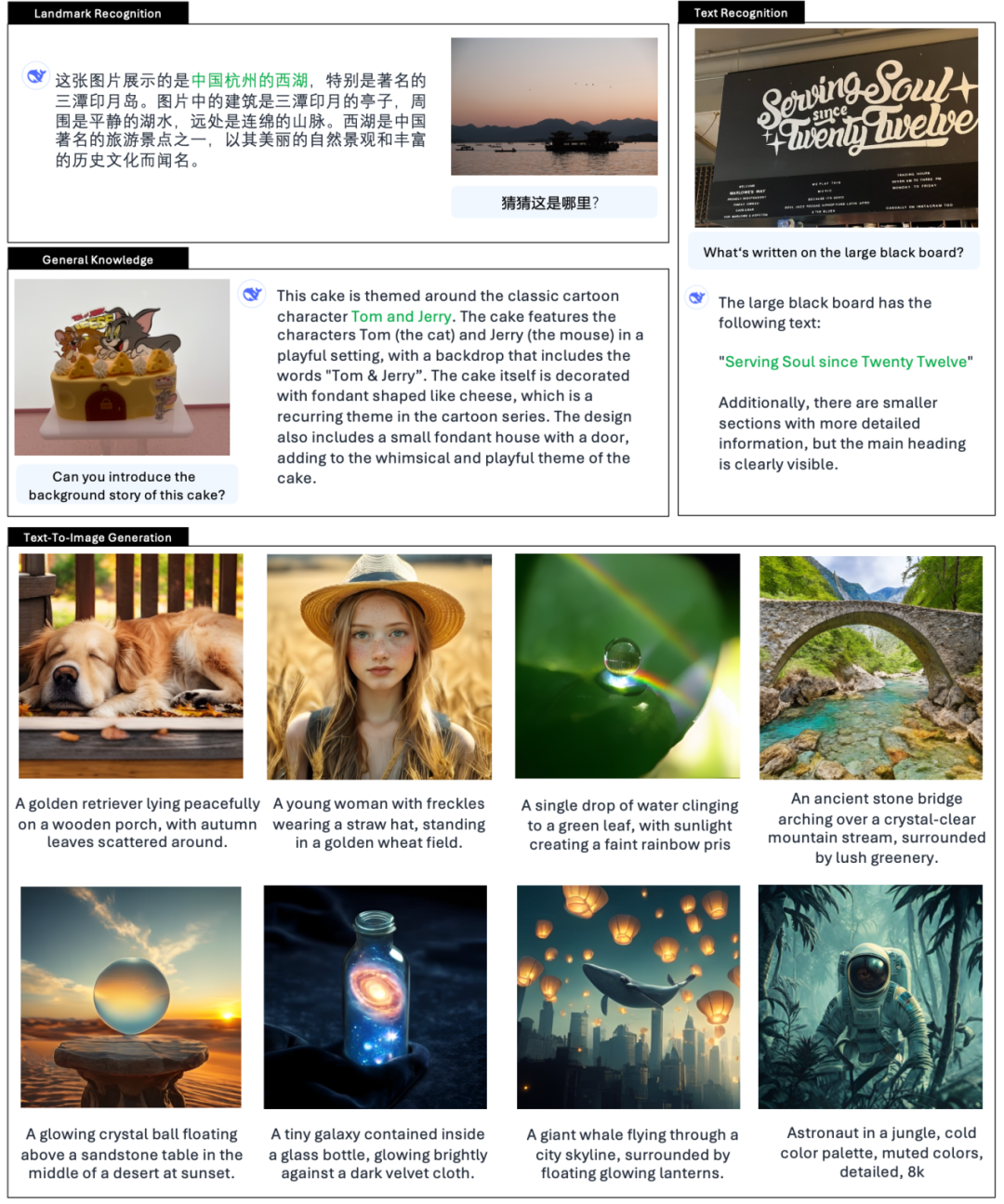
Secondo l'introduzione ufficiale di DeepSeek, Janus-Pro non solo può capire le immagini, estrarre e comprendere il testo nelle immagini, ma anche generare immagini allo stesso tempo.
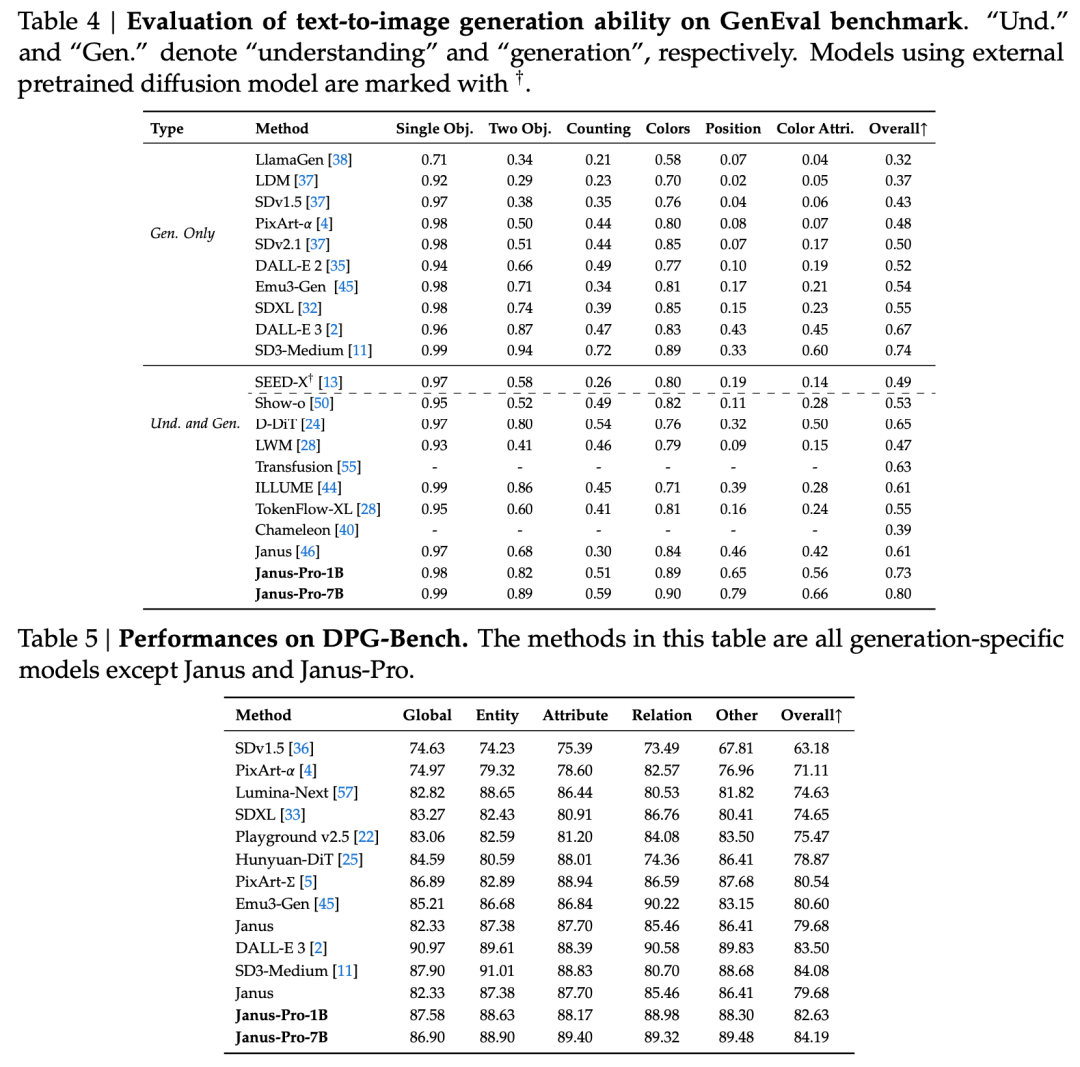
La relazione tecnica indica che, rispetto ad altri modelli dello stesso tipo e ordine di grandezza, i punteggi dell'Janus-Pro-7B sui set di test GenEval e DPG-Bench superano quelle di altri modelli come SD3-Medium e DALL-E 3.
Il funzionario fornisce anche degli esempi 👇:
Anche molti netizen su X stanno provando le nuove funzioni.

Ma si verificano anche incidenti occasionali.
Consultando i documenti tecnici su DeepSeekAbbiamo scoperto che Janus Pro è un'ottimizzazione basata su Janus, rilasciata tre mesi fa.
L'innovazione principale di questa serie di modelli consiste nel disaccoppiare i compiti di comprensione visiva da quelli di generazione visiva, in modo da bilanciare gli effetti dei due compiti.
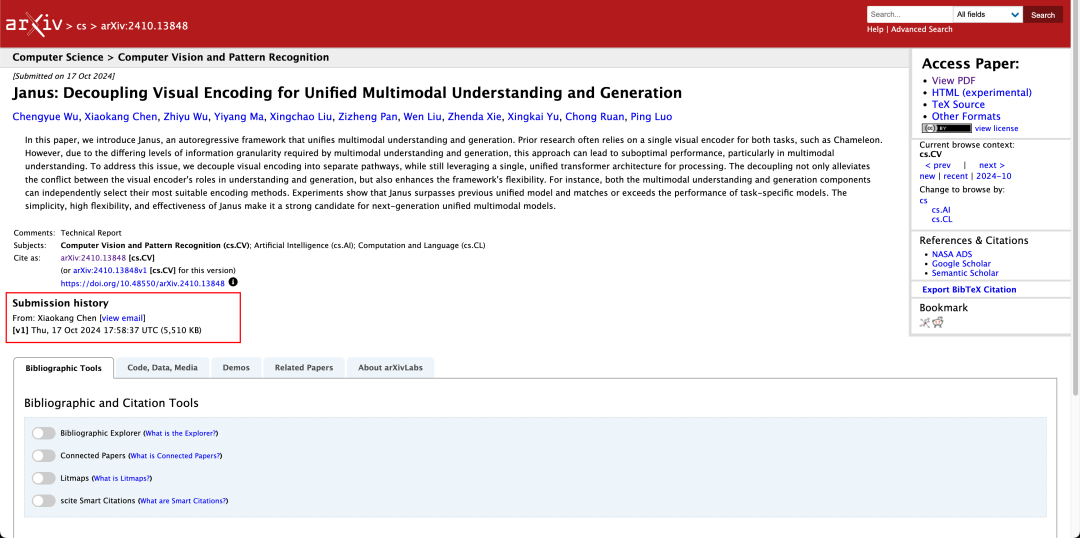
Non è raro che un modello sia in grado di eseguire contemporaneamente la comprensione e la generazione multimodale. D-DiT e TokenFlow-XL in questo set di test hanno entrambi questa capacità.
Tuttavia, ciò che caratterizza Giano è che disaccoppiando l'elaborazione, un modello in grado di eseguire la comprensione e la generazione multimodale bilancia l'efficacia dei due compiti.
Bilanciare l'efficacia dei due compiti è un problema difficile nel settore. In precedenza si pensava di utilizzare lo stesso codificatore per implementare il più possibile la comprensione e la generazione multimodale.
I vantaggi di questo approccio sono un'architettura semplice, l'assenza di implementazioni ridondanti e l'allineamento con i modelli testuali (che utilizzano gli stessi metodi per la generazione e la comprensione del testo). Un'altra argomentazione è che questa fusione di più abilità può portare a un certo grado di emergenzialità.
Tuttavia, in realtà, dopo aver fuso generazione e comprensione, i due compiti sono in conflitto: la comprensione delle immagini richiede che il modello astragga in alte dimensioni ed estragga la semantica centrale dell'immagine, che è orientata verso il macroscopico. La generazione di immagini, invece, si concentra sull'espressione e la generazione di dettagli locali a livello di pixel.
La prassi abituale del settore è quella di dare priorità alle capacità di generazione delle immagini. Ciò si traduce in modelli multimodali che possono generare immagini di qualità superiore, ma i risultati della comprensione delle immagini sono spesso mediocri.
L'architettura disaccoppiata di Janus e la strategia di formazione ottimizzata di Janus-Pro
L'architettura disaccoppiata di Janus permette al modello di bilanciare i compiti di comprensione e generazione in modo autonomo.
Secondo i risultati del rapporto tecnico ufficiale, sia che si tratti di comprensione multimodale o di generazione di immagini, l'Janus-Pro-7B si comporta bene su più set di test.

Per una comprensione multimodale, Janus-Pro-7B ha ottenuto il primo posto in quattro dei sette set di dati di valutazione e il secondo posto nei restanti tre, leggermente dietro al modello più classificato.
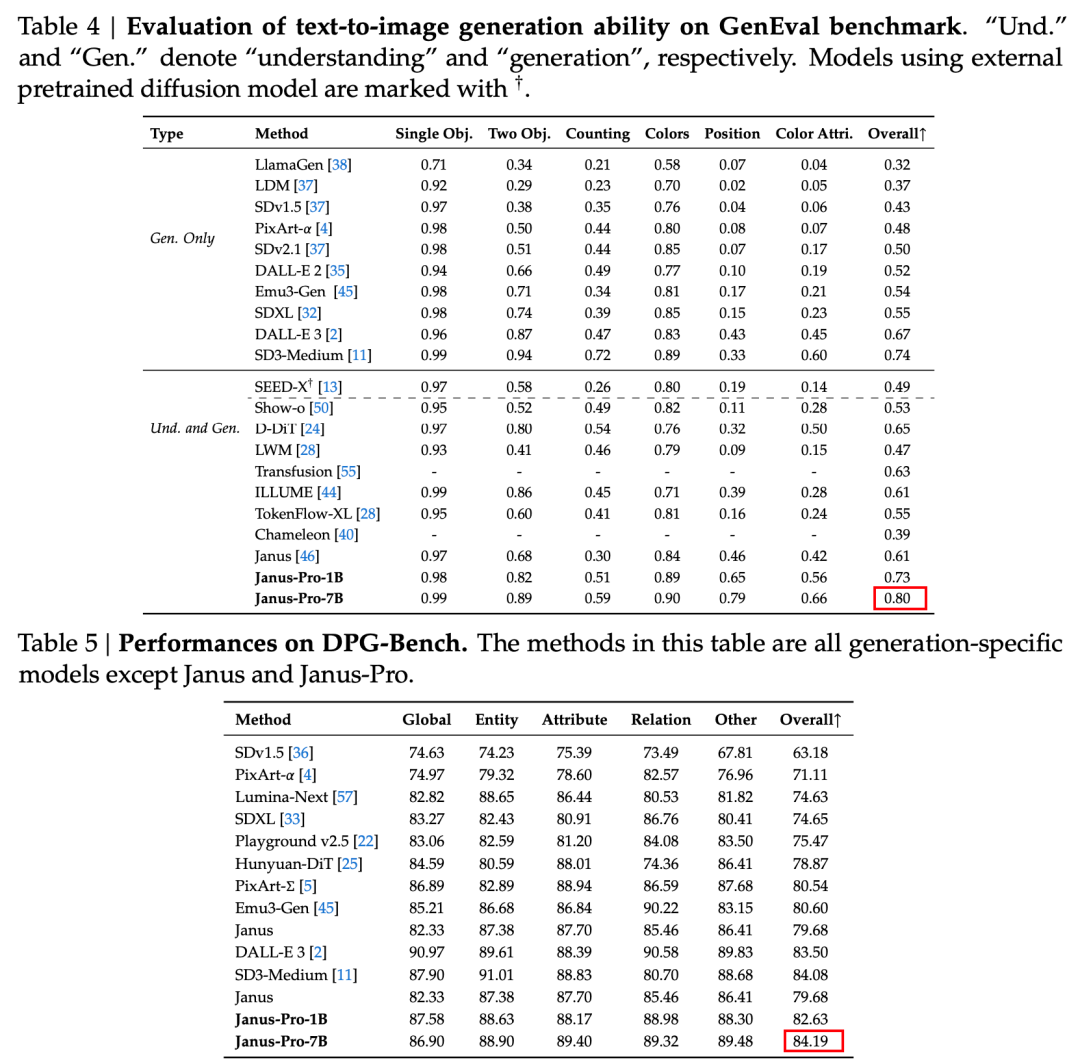
Per la generazione di immagini, Janus-Pro-7B ha ottenuto il primo posto nel punteggio complessivo su entrambi i dataset di valutazione GenEval e DPG-Bench.
Questo effetto multi-tasking è dovuto principalmente all'utilizzo, nella serie Janus, di due codificatori visivi per compiti diversi:
- Comprensione del codificatore: utilizzato per estrarre caratteristiche semantiche nelle immagini per compiti di comprensione delle immagini (come domande e risposte sulle immagini, classificazione visiva, ecc.)
- Codificatore generativo: converte le immagini in una rappresentazione discreta (ad esempio, utilizzando un codificatore VQ) per compiti di generazione di testi da immagini.
Con questa architettura, il modello è in grado di ottimizzare in modo indipendente le prestazioni di ciascun codificatore, in modo che i compiti di comprensione e generazione multimodale possano ottenere ciascuno le migliori prestazioni.
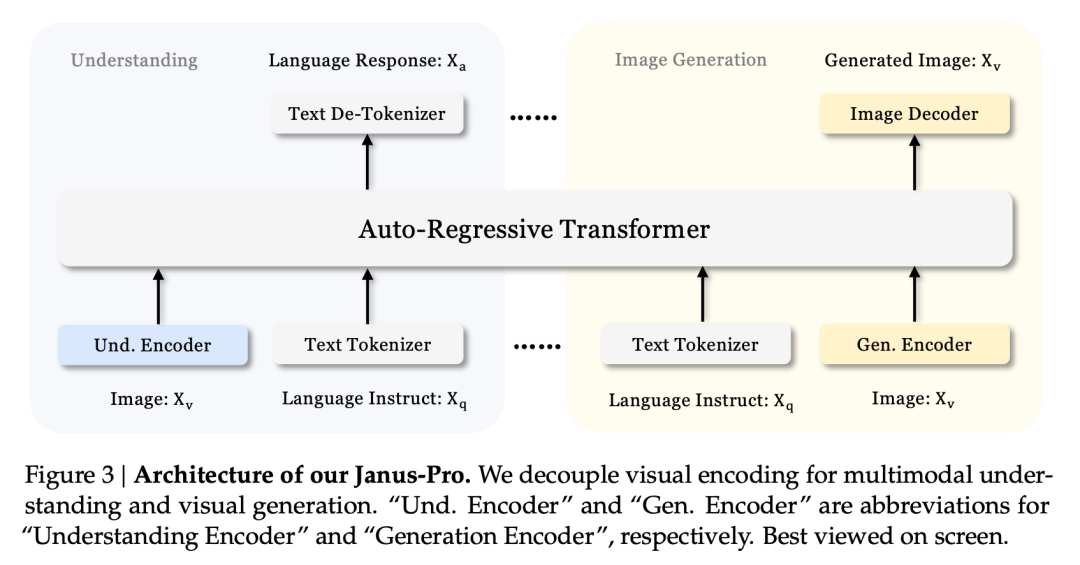
Questa architettura disaccoppiata è comune a Janus-Pro e Janus. Quali sono state le iterazioni di Janus-Pro negli ultimi mesi?
Come si può notare dai risultati del set di valutazione, l'attuale versione dell'Janus-Pro-1B ha un miglioramento di circa 10% a 20% nei punteggi dei diversi set di valutazione rispetto al precedente Janus. L'Janus-Pro-7B presenta il miglioramento più elevato, pari a circa 45% rispetto a Janus dopo aver ampliato il numero di parametri.

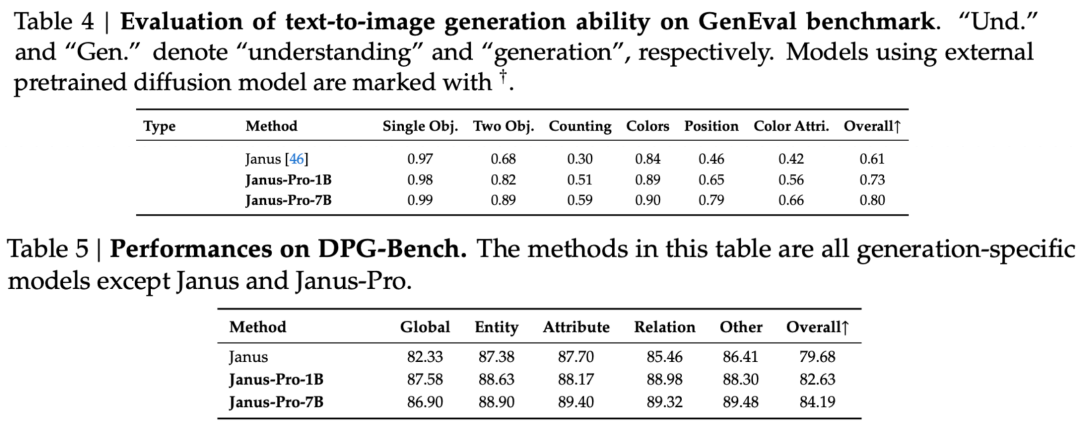
In termini di dettagli sull'addestramento, la relazione tecnica afferma che l'attuale versione di Janus-Pro, rispetto al precedente modello Janus, mantiene il design dell'architettura disaccoppiata di base, e in più itera su dimensione dei parametri, strategia di addestramento e dati di addestramento.
Per prima cosa, analizziamo i parametri.
La prima versione di Janus aveva solo 1,3B parametri, mentre l'attuale versione di Pro include modelli con 1B e 7B parametri.
Queste due dimensioni riflettono la scalabilità dell'architettura Janus. Il modello 1B, il più leggero, è già stato utilizzato da utenti esterni per l'esecuzione nel browser tramite WebGPU.
C'è anche il strategia di formazione.
In linea con la divisione delle fasi di formazione di Janus, l'Janus Pro ha un totale di tre fasi di formazione, che il documento divide direttamente in Fase I, Fase II e Fase III.
Pur mantenendo le idee formative di base e gli obiettivi formativi di ciascuna fase, l'Janus-Pro ha apportato miglioramenti alla durata e ai dati della formazione nelle tre fasi. Di seguito sono riportati i miglioramenti specifici delle tre fasi:
Fase I - Tempo di allenamento più lungo
Rispetto a Janus, Janus-Pro ha allungato i tempi di addestramento nella fase I, soprattutto per quanto riguarda l'addestramento degli adattatori e delle teste delle immagini nella parte visiva. Ciò significa che l'apprendimento delle caratteristiche visive ha ricevuto più tempo di addestramento e si spera che il modello possa comprendere appieno le caratteristiche dettagliate delle immagini (come la mappatura pixel-semantica).
Questa formazione estesa aiuta a garantire che la formazione della parte visiva non sia disturbata da altri moduli.
Fase II - Rimozione dei dati ImageNet e aggiunta di dati multimodali
Nella fase II, Janus ha fatto riferimento a PixArt e si è allenato in due parti. La prima parte è stata addestrata utilizzando il dataset ImageNet per la classificazione delle immagini, mentre la seconda parte è stata addestrata utilizzando i normali dati testo-immagine. Circa due terzi del tempo della Fase II sono stati dedicati all'addestramento della prima parte.
Janus-Pro elimina la formazione ImageNet nella fase II. Questo design consente al modello di concentrarsi sui dati da testo a immagine durante la fase II dell'addestramento. Secondo i risultati sperimentali, ciò può migliorare significativamente l'utilizzo dei dati da testo a immagine.
Oltre all'adeguamento della progettazione del metodo di addestramento, il set di dati di addestramento utilizzato nella Fase II non è più limitato a un compito di classificazione di una singola immagine, ma include anche altri tipi di dati multimodali, come la descrizione dell'immagine e il dialogo, per l'addestramento congiunto.
Fase III - Ottimizzazione del rapporto dati
Nella fase III dell'addestramento, Janus-Pro regola il rapporto tra i diversi tipi di dati di addestramento.
In precedenza, il rapporto tra dati di comprensione multimodale, dati di testo semplice e dati da testo a immagine nei dati di addestramento utilizzati da Janus nella Fase III era 7:3:10. L'Janus-Pro riduce il rapporto tra gli ultimi due tipi di dati e regola il rapporto tra i tre tipi di dati a 5:1:4, prestando cioè maggiore attenzione al compito di comprensione multimodale.
Esaminiamo i dati di allenamento.
Rispetto a Janus, questa volta l'Janus-Pro aumenta in modo significativo la quantità di dati sintetici.
Amplia la quantità e la varietà di dati di addestramento per la comprensione multimodale e la generazione di immagini.
Espansione dei dati di comprensione multimodale:
Janus-Pro fa riferimento al set di dati DeepSeek-VL2 durante l'addestramento e aggiunge circa 90 milioni di punti dati aggiuntivi, tra cui non solo set di dati di descrizione delle immagini, ma anche set di dati di scene complesse come tabelle, grafici e documenti.
Durante la fase di perfezionamento supervisionato (Fase III), continua ad aggiungere insiemi di dati relativi alla comprensione di MEME e al miglioramento dell'esperienza di dialogo (compreso il dialogo cinese).
Espansione dei dati di generazione visiva:
I dati originali del mondo reale avevano una qualità scadente e alti livelli di rumore, che hanno fatto sì che il modello producesse risultati instabili e immagini di qualità estetica insufficiente nei compiti da testo a immagine.
Janus-Pro ha aggiunto circa 72 milioni di nuovi dati sintetici ad alto contenuto estetico alla fase di addestramento, portando il rapporto tra dati reali e dati sintetici nella fase di pre-addestramento a 1:1.
I suggerimenti per i dati sintetici sono stati tutti presi da risorse pubbliche. Gli esperimenti hanno dimostrato che l'aggiunta di questi dati fa convergere il modello più velocemente e le immagini generate presentano evidenti miglioramenti in termini di stabilità e bellezza visiva.
La continuazione di una rivoluzione dell'efficienza?
Nel complesso, con questa versione DeepSeek ha portato la rivoluzione dell'efficienza nei modelli visivi.
A differenza dei modelli visivi che si concentrano su un'unica funzione o dei modelli multimodali che privilegiano un compito specifico, Janus-Pro bilancia gli effetti dei due compiti principali della generazione di immagini e della comprensione multimodale nello stesso modello.
Inoltre, nonostante i suoi parametri ridotti, ha battuto OpenAI DALL-E 3 e SD3-Medium nella valutazione.
Estesa a terra, l'azienda deve solo distribuire un modello per implementare direttamente le due funzioni di generazione e comprensione delle immagini. Se a ciò si aggiunge una dimensione di soli 7B, la difficoltà e il costo di implementazione sono molto più bassi.
In relazione ai precedenti rilasci di R1 e V3, DeepSeek sta sfidando le regole esistenti del gioco con "innovazione architettonica compatta, modelli leggeri, modelli open source e costi di formazione bassissimi".. Questo è il motivo del panico tra i giganti tecnologici occidentali e persino a Wall Street.
Proprio ora, Sam Altman, che è stato trascinato dall'opinione pubblica per diversi giorni, ha finalmente risposto positivamente alle informazioni su DeepSeek su X - mentre elogiava R1, ha detto che OpenAI farà alcuni annunci.