
ja tekoälyn aikakausi on pikkuhiljaa saapunut.
Luultavasti kukaan ei odottanut, että tämä kiinalainen uusivuosi, kuumin aihe ei olisi enää perinteinen Internet punainen kirjekuori taistelu, joka kumppanina kevätjuhla Gala, mutta AI yritykset.
Kevätjuhlan lähestyessä suuret malliyritykset eivät hellittäneet lainkaan, vaan päivittivät mallien ja tuotteiden aallon. Eniten puhuttiin kuitenkin DeepSeekistä, viime vuonna syntyneestä "suuresta malliyrityksestä".
Tammikuun 20. päivän iltana, DeepSeek julkaisi virallisen version päättelymallistaan DeepSeek-R1. Käyttämällä alhaisia koulutuskustannuksia se koulutti suoraan suorituskyvyn, joka ei ole huonompi kuin OpenAI:n päättelymalli o1. Lisäksi se on täysin ilmainen ja avoimen lähdekoodin malli, mikä aiheutti suoraan alan maanjäristyksen.
Tämä on ensimmäinen kerta, kun kotimainen tekoäly on aiheuttanut kohua teknologiamaailmassa laajamittaisesti ympäri maailmaa, erityisesti Yhdysvalloissa. Kehittäjät ovat ilmaisseet harkitsevansa DeepSeekin käyttämistä "kaiken uudelleenrakentamiseen". Tämän aallon seurauksena, viikon käymisen jälkeen, ja jopa vasta tammikuussa julkaistuna, DeepSeek-mobiilisovellus nousi nopeasti ilmaisten sovellusten rankingin kärkeen Applen App Storessa Yhdysvalloissa, ohittaen ChatGPT:n lisäksi myös muita suosittuja sovelluksia Yhdysvalloissa.
DeepSeekin menestys on jopa vaikuttanut suoraan Yhdysvaltain osakemarkkinoihin. Malli, joka on koulutettu ilman valtavaa määrää kalliita GPU:ita, on saanut ihmiset miettimään tekoälyn koulutuspolkua uudelleen, mikä on aiheuttanut suoraan tekoälyn ensimmäisen osakkeen, NVIDIAn, suurimman pudotuksen 17%.
Eikä siinä vielä kaikki.
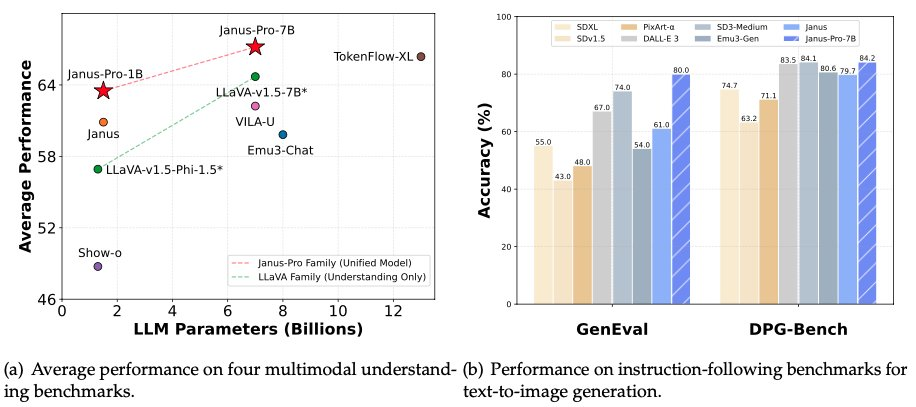
Tammikuun 28. päivän aamuna, uudenvuodenaattoa edeltävänä yönä, DeepSeek avasi jälleen lähdekoodinsa multimodaaliselle mallilleen Janus-Pro-7B ja ilmoitti, että se oli voittanut DALL-E 3:n (OpenAI:lta) ja Stable Diffusionin GenEval- ja DPG-Bench-vertailutesteissä.
Tuleeko DeepSeek todella valloittamaan tekoälyyhteisön? Päätelmämalleista multimodaalisiin malleihin, onko DeepSeek uudistamassa kaiken Käärmeen vuoden ensimmäisen aiheen?
Janus Pro, innovatiivisen multimodaalisen malliarkkitehtuurin validointi
DeepSeek julkaisi tällä kertaa myöhään illalla yhteensä kaksi mallia: Janus-Pro-7B ja Janus-Pro-1B (1,5B parametrit).
Kuten nimestä voi päätellä, itse malli on päivitys edellisestä Janus-mallista.
DeepSeek julkaisi Janus-mallin ensimmäisen kerran vasta lokakuussa 2024. Kuten DeepSeekillä on tapana, mallissa käytetään innovatiivista arkkitehtuuria. Monissa visuaalisen näkemisen sukupolven malleissa malli ottaa käyttöön yhtenäisen Transformer-arkkitehtuurin, joka voi käsitellä samanaikaisesti tekstistä kuvaksi ja kuvasta tekstiksi -tehtäviä.
DeepSeek ehdottaa uutta ideaa, jossa ymmärryksen (graafi-teksti) ja generointitehtävien (teksti-graafi) visuaalinen koodaus erotetaan toisistaan, mikä parantaa mallien koulutuksen joustavuutta ja lievittää tehokkaasti yhden visuaalisen koodauksen käytöstä aiheutuvia ristiriitoja ja suorituskyvyn pullonkauloja.
Tämän vuoksi DeepSeek nimesi mallin Janukseksi. Janus on muinaisen Rooman ovijumala, joka on kuvattu kahdella vastakkaisiin suuntiin osoittavalla naamalla. DeepSeekin mukaan malli on nimetty Janukseksi, koska se voi katsoa visuaalista dataa eri silmillä, koodata piirteet erikseen ja käyttää sitten samaa kehoa (Transformer) näiden tulosignaalien käsittelyyn.
Tämä uusi idea on tuottanut hyviä tuloksia Janus-mallisarjassa. Tiimi kertoo, että Janus-mallilla on vahvat komentojen seuraamisominaisuudet, monikielisyysominaisuudet ja malli on älykkäämpi, sillä se pystyy lukemaan meemikuvia. Se pystyy myös hoitamaan tehtäviä, kuten lateksikaavojen muuntamisen ja graafien muuntamisen koodiksi.
Janus Pro-mallisarjassa tiimi on osittain muuttanut mallin koulutusprosessia, mikä on suoraan johtanut tuloksiin, jotka päihittävät DALL-E 3:n ja Stable Diffusionin GenEval- ja DPG-Bench-vertailutesteissä.
Itse mallin lisäksi DeepSeek on julkaissut myös uuden multimodaalisen tekoälykehyksen Janus Flow, jonka tarkoituksena on yhdistää kuvien ymmärtämis- ja tuottamistehtävät.
Malli Janus Pro voi tuottaa vakaamman tulosteen lyhyillä kehotuksilla, joilla on parempi visuaalinen laatu, runsaammat yksityiskohdat ja kyky tuottaa yksinkertaista tekstiä.
Malli pystyy luomaan kuvia ja kuvaamaan kuvia, tunnistamaan maamerkkejä (kuten Hangzhoun länsijärvi), tunnistamaan tekstiä kuvista ja kuvaamaan tietoa kuvista (kuten Tom ja Jerry -kakut).
One x.com, Monet ihmiset ovat jo alkaneet kokeilla uutta mallia.

Kuvantunnistustesti näkyy yllä olevassa kuvassa vasemmalla, kun taas kuvanluontitesti näkyy oikealla.

Kuten voidaan nähdä, Janus Pro lukee myös kuvat hyvin ja tarkasti. Se pystyy tunnistamaan matemaattisten lausekkeiden ja tekstin sekatekstit. Tulevaisuudessa voi olla tärkeämpää käyttää sitä päättelymallin kanssa.
1B:n ja 7B:n parametrit voivat avata uusia sovelluskohteita.
Multimodaalisissa ymmärtämistehtävissä uusi malli Janus-Pro käyttää SigLIP-L:ää visuaalisena kooderina ja tukee 384 x 384 pikselin kokoisia kuvia. Kuvanmuodostustehtävissä Janus-Pro käyttää tietystä lähteestä peräisin olevaa tokenisaattoria, jonka downsampling-nopeus on 16.
Tämä on vielä suhteellisen pieni kuvakoko. X Käyttäjäanalyysissä Janus Pro-malli on enemmänkin suuntaa-antava tarkistus. Jos verifiointi on luotettava, julkaistaan malli, joka voidaan ottaa tuotantoon.
On kuitenkin syytä huomata, että Januksen tällä kertaa julkaisema uusi malli ei ole ainoastaan arkkitehtuuriltaan innovatiivinen multimodaalisten mallien osalta, vaan se on myös uusi tutkimusmatka parametrien määrän suhteen.
DeepSeek Janus Pro:n tällä kertaa vertailema DALL-E 3 -malli ilmoitti aiemmin, että siinä on 12 miljardia parametria, kun taas Janus Pro:n suurikokoisessa mallissa on vain 7 miljardia parametria. Näin pienen koon ansiosta on jo erittäin hyvä, että Janus Pro pystyy saavuttamaan tällaisia tuloksia.
Erityisesti Janus Pro:n 1B-mallissa käytetään vain 1,5 miljardia parametria. Käyttäjät ovat jo lisänneet mallin tuen transformers.js:ään ulkoisessa verkossa. Tämä tarkoittaa sitä, että mallia voi nyt ajaa 100% selaimissa WebGPU:lla!
Vaikka kirjoittaja ei ole vielä lehdistötiedotteeseen mennessä onnistunut käyttämään Janus Pro:n uutta mallia verkkoversiossa, se, että parametrien määrä on tarpeeksi pieni, jotta sitä voidaan käyttää suoraan verkkopuolella, on silti hämmästyttävä parannus.
Tämä tarkoittaa, että kuvien tuottamisen ja ymmärtämisen kustannukset laskevat jatkuvasti. Meillä on mahdollisuus nähdä tekoälyn käyttö yhä useammissa paikoissa, joissa raakakuvia ja kuvien ymmärtämistä ei ole aiemmin voitu käyttää, mikä muuttaa elämäämme.
Yksi vuoden 2024 tärkeimmistä kysymyksistä on se, miten tekoälylaitteistot, joilla on lisätty multimodaalista ymmärrystä, voivat puuttua elämäämme. Multimodaalisen ymmärryksen mallit, joiden parametrit ovat yhä pienempiä, tai mallit, joiden voidaan odottaa toimivan reunalla, voivat mahdollistaa tekoälylaitteistojen räjähdysmäisen kasvun.
DeepSeek on sekoittanut uuden vuoden. Voidaanko kaikki tehdä uudelleen kiinalaisen tekoälyn avulla?
Tekoälyn maailma muuttuu päivä päivältä.
Viime vuoden kevätjuhlien aikaan maailmaa kuohutti OpenAI:n Sora-malli. Vuoden aikana kiinalaiset yritykset ovat kuitenkin ottaneet videon tuottamisessa täysin kiinni, joten Sora-mallin julkaisu vuoden lopussa näyttää hieman synkältä.
Tänä vuonna maailmaa on kuohuttanut Kiinan DeepSeek.
DeepSeek ei ole perinteinen teknologiayritys, mutta se on valmistanut erittäin innovatiivisia malleja kustannuksiltaan paljon alhaisemmilla hinnoilla kuin suurten amerikkalaisten malliyritysten GPU-kortit, mikä on suoraan järkyttänyt amerikkalaisia kollegojaan. Amerikkalaiset ovat huudahtaneet: "R1-mallin koulutus maksoi vain 5,6 miljoonaa Yhdysvaltain dollaria, mikä vastaa jopa minkä tahansa johtajan palkkaa Meta GenAI -tiimissä. Mikä on tämä salaperäinen idän voima?"
DeepSeekin perustajaa Liang Wenfengiä jäljittelevä parodiatili julkaisi mielenkiintoisen kuvan suoraan X:ssä:

Kuvassa käytettiin trenditietoista meemiä maailmankuulusta turkkilaisesta ampujasta vuonna 2024.
Pariisin olympialaisten ampumahiihdon 10 metrin ilmapistoolin loppukilpailussa 51-vuotias turkkilainen ampuja Mithat Dikec, jolla oli päällään vain tavalliset likinäköiset silmälasit ja unikorvatulpat, pokkasi rauhallisesti hopeamitalin yhdellä kädellä taskussaan. Kaikki muut paikalla olleet ampujat tarvitsivat kaksi ammattilaislinssiä tarkennusta ja valonsuojausta varten sekä parin melua vaimentavia korvatulppia aloittaakseen kilpailun.
Koska DeepSeek "murtautui" OpenAI:n päättelymallisuuret yhdysvaltalaiset teknologiayritykset ovat joutuneet voimakkaan paineen alle. Tänään Sam Altman vastasi vihdoin virallisella lausunnolla.

Onko vuosi 2025 se vuosi, jolloin kiinalainen tekoäly vaikuttaa amerikkalaisten käsityksiin?
DeepSeekillä on vielä salaisuuksia hihassaan - tästä on määrä tulla poikkeuksellinen kevätjuhla.


