
وقد وصل عصر الذكاء الاصطناعي بهدوء.
ربما لم يتوقع أحد أن الموضوع الأكثر سخونة في هذه السنة الصينية الجديدة لن يكون معركة المظروف الأحمر التقليدية على الإنترنت، التي شاركت في حفل عيد الربيع، بل شركات الذكاء الاصطناعي.
مع اقتراب مهرجان الربيع، لم تهدأ شركات النماذج الكبرى على الإطلاق، حيث قامت بتحديث موجة من النماذج والمنتجات. ومع ذلك، كان أكثر ما تم الحديث عنه هو شركة DeepSeek، وهي "شركة نماذج كبرى" ظهرت العام الماضي.
في مساء يوم 20 يناير, العمقSإيك النسخة الرسمية من نموذجها الاستدلالي DeepSeek-R1. وباستخدام تكلفة تدريب منخفضة، قام بتدريب أداء لا يقل مباشرةً عن نموذج الاستدلال OpenAI o1. وعلاوة على ذلك، فهو مجاني ومفتوح المصدر تمامًا، وهو ما أحدث زلزالًا في الصناعة بشكل مباشر.
هذه هي المرة الأولى التي يُحدث فيها ذكاء اصطناعي محلي ضجة في عالم التكنولوجيا على نطاق واسع في جميع أنحاء العالم، وخاصة في الولايات المتحدة. وقد أعرب المطورون عن أنهم يفكرون في استخدام DeepSeek "لإعادة بناء كل شيء". في أعقاب هذه الموجة، وبعد أسبوع من التخمير، وحتى بعد إطلاقه في يناير/كانون الثاني، وصل تطبيق DeepSeek للهاتف المحمول بسرعة إلى قمة تصنيفات التطبيقات المجانية على متجر تطبيقات Apple في الولايات المتحدة، متجاوزاً ليس فقط تطبيق ChatGPT، بل أيضاً تطبيقات أخرى شائعة في الولايات المتحدة.
حتى أن نجاح DeepSeek أثر بشكل مباشر على سوق الأسهم الأمريكية. فقد جعل النموذج الذي تم تدريبه دون استخدام كمية هائلة من وحدات معالجة الرسومات باهظة الثمن الناس يعيدون التفكير في مسار تدريب الذكاء الاصطناعي، مما تسبب بشكل مباشر في أكبر انخفاض قدره 17% في أول سهم للذكاء الاصطناعي، وهو سهم NVIDIA.
وهذا ليس كل شيء.
في الصباح الباكر من يوم 28 يناير، أي في الليلة التي سبقت ليلة رأس السنة الجديدة، فتحت DeepSeek مرة أخرى مصدر نموذجها متعدد الوسائط Janus-Pro-7B، معلنةً أنها هزمت DALL-E 3 (من OpenAI) و Stable Diffusion في اختبارات المقارنة المعيارية GenEval و DPG-Bench.
هل سيكتسح DeepSeek حقاً مجتمع الذكاء الاصطناعي؟ من النماذج الاستدلالية إلى النماذج متعددة الوسائط، هل سيعيد DeepSeek هيكلة كل شيء في أول موضوع في عام الأفعى؟
Janus Proالتحقق من صحة بنية نموذج مبتكرة متعددة الوسائط
أصدرت شركة DeepSeek ما مجموعه نموذجين في وقت متأخر من الليل هذه المرة: Janus-Pro-7B وJanus-Pro-1B (1.5B معلمات).
كما يوحي الاسم، فإن الطراز نفسه هو ترقية من طراز Janus السابق.
أصدرت DeepSeek نموذج Janus لأول مرة فقط في أكتوبر 2024. وكعادة DeepSeek، يعتمد النموذج بنية مبتكرة. في العديد من نماذج توليد الرؤية، يتبنى النموذج بنية محول موحدة يمكنها معالجة مهام تحويل النص إلى صورة والصورة إلى نص في آن واحد.
يقترح DeepSeek فكرة جديدة، وهي الفصل بين الترميز المرئي لمهام الفهم (من الرسم البياني إلى النص) ومهام التوليد (من النص إلى الرسم البياني)، مما يحسن مرونة تدريب النموذج ويخفف بشكل فعال من التعارضات واختناقات الأداء الناجمة عن استخدام ترميز مرئي واحد.
هذا هو سبب تسمية DeepSeek للنموذج جانوس. ويانوس هو إله الأبواب الروماني القديم، وقد صُوِّر بوجهين متعاكسين في اتجاهين متعاكسين. قال موقع DeepSeek إن النموذج سُمي جانوس لأنه يستطيع النظر إلى البيانات المرئية بعيون مختلفة، وترميز الميزات بشكل منفصل، ثم استخدام نفس الجسم (المحول) لمعالجة إشارات الإدخال هذه.
وقد أثمرت هذه الفكرة الجديدة نتائج جيدة في سلسلة نماذج Janus. يقول الفريق إن نموذج Janus يتمتع بقدرات قوية على اتباع الأوامر، وقدرات متعددة اللغات، كما أن النموذج أكثر ذكاءً، وقادر على قراءة صور الميم. ويمكنه أيضًا التعامل مع مهام مثل تحويل صيغ اللاتكس وتحويل الرسوم البيانية إلى رموز.
في سلسلة النماذج Janus Pro، قام الفريق بتعديل جزئي لعملية تدريب النموذج، مما حقق نتائج مباشرة تفوقت على DALL-E 3 و Stable Diffusion في اختبارات GenEval و DPG-Bench القياسية.
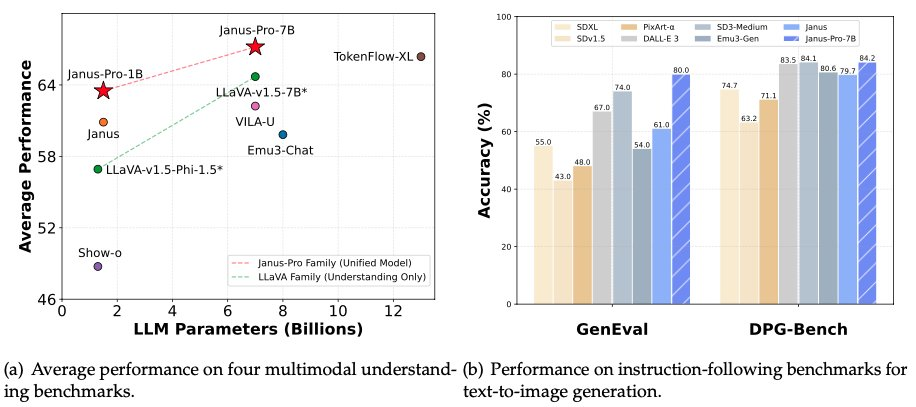
إلى جانب النموذج نفسه، أصدرت DeepSeek أيضاً إطار عمل الذكاء الاصطناعي الجديد متعدد الوسائط Janus Flow، والذي يهدف إلى توحيد مهام فهم الصور وتوليدها.
الطراز Janus Pro يمكن أن يوفر مخرجات أكثر استقرارًا باستخدام مطالبات قصيرة، مع جودة بصرية أفضل وتفاصيل أكثر ثراءً وقدرة على توليد نص بسيط.
يمكن للنموذج توليد الصور ووصف الصور، وتحديد معالم الجذب السياحي (مثل بحيرة هانغتشو الغربية)، والتعرف على النص في الصور، ووصف المعرفة في الصور (مثل كعك "توم وجيري").
كوم One x.com، بدأ العديد من الأشخاص بالفعل في تجربة النموذج الجديد.

يظهر اختبار التعرف على الصور على اليسار في الشكل أعلاه، بينما يظهر اختبار توليد الصور على اليمين.

كما هو واضح، يقوم Janus Pro أيضًا بعمل جيد في قراءة الصور بدقة عالية. ويمكنه التعرف على التنضيد المختلط للتعبيرات الرياضية والنصوص. في المستقبل، قد يكون من الأهمية بمكان استخدامه مع نموذج استدلالي.
قد تفتح معلمات 1 ب و7 ب سيناريوهات تطبيق جديدة
في مهام الفهم متعدد الوسائط، يستخدم النموذج الجديد Janus-Pro نموذج Janus-Pro SigLIP-L كمشفر مرئي ويدعم مدخلات الصور بحجم 384 × 384 بكسل. في مهام توليد الصور، يستخدم النموذج Janus-Pro أداة ترميز من مصدر محدد بمعدل تصغير 16 بكسل.
لا يزال حجم الصورة صغيرًا نسبيًا. X بالنسبة لتحليل المستخدم، فإن نموذج Janus Pro هو أكثر من مجرد تحقق اتجاهي. إذا كان التحقق موثوقًا، فسيتم إصدار نموذج يمكن وضعه في الإنتاج.
ومع ذلك، تجدر الإشارة إلى أن النموذج الجديد الذي أصدرته جانوس هذه المرة ليس مبتكرًا من الناحية المعمارية للنماذج متعددة الوسائط فحسب، بل هو أيضًا استكشاف جديد من حيث عدد المعلمات.
النموذج الذي تمت مقارنته بواسطة DeepSeek Janus Pro هذه المرة، DALL-E 3، الذي أعلن سابقاً أنه يحتوي على 12 مليار معلمة، في حين أن النموذج الكبير الحجم لـ Janus Pro يحتوي على 7 مليارات معلمة فقط. مع هذا الحجم الصغير، من الجيد بالفعل أن يتمكن Janus Pro من تحقيق مثل هذه النتائج.
على وجه الخصوص، يستخدم النموذج 1B من Janus Pro 1.5 مليار معلمة فقط. أضاف المستخدمون بالفعل دعمًا للنموذج إلى محولات.js على الشبكة الخارجية. هذا يعني أن النموذج يمكنه الآن تشغيل 100% في المتصفحات على WebGPU!
على الرغم من أنه حتى وقت نشر هذا المقال، لم يتمكن المؤلف حتى الآن من استخدام النموذج الجديد من Janus Pro بنجاح على إصدار الويب، إلا أن حقيقة أن عدد المعلمات صغير بما يكفي لتشغيله مباشرة على جانب الويب لا يزال يمثل تحسناً مذهلاً.
وهذا يعني أن تكلفة توليد الصور/فهم الصور في انخفاض مستمر. لدينا الفرصة لرؤية استخدام الذكاء الاصطناعي في المزيد من الأماكن التي لم يكن من الممكن استخدام الصور الخام وفهم الصور فيها من قبل، مما يغير حياتنا.
تكمن إحدى النقاط الساخنة الرئيسية في عام 2024 في كيفية تدخل أجهزة الذكاء الاصطناعي ذات الفهم المتعدد الوسائط المضافة في حياتنا. قد تمكّن نماذج الفهم متعدد الوسائط ذات المعلمات المنخفضة بشكل متزايد، أو النماذج التي يمكن توقع تشغيلها على الحافة، أجهزة الذكاء الاصطناعي من تحقيق المزيد من الانتشار.
لقد أثار DeepSeek العام الجديد. هل يمكن إعادة صياغة كل شيء باستخدام الذكاء الاصطناعي الصيني؟
يتغير عالم الذكاء الاصطناعي يوماً بعد يوم.
خلال مهرجان الربيع العام الماضي، كان ما أثار العالم هو نموذج Sora الخاص بشركة OpenAI. ومع ذلك، على مدار العام، استحوذت الشركات الصينية على إنتاج الفيديو تمامًا، مما جعل إصدار Sora في نهاية العام يبدو كئيبًا بعض الشيء.
في هذا العام، أصبح ما أثار العالم هذا العام هو "ديبسيك" الصيني.
إن شركة DeepSeek ليست شركة تكنولوجية تقليدية، ولكنها صنعت نماذج مبتكرة للغاية بتكلفة أقل بكثير من تكلفة بطاقات وحدات معالجة الرسومات الخاصة بشركات الطرازات الأمريكية الكبرى، وهو ما صدم نظراءها الأمريكيين بشكل مباشر. فقد صرخ الأمريكيون "تكلف تدريب نموذج R1 5.6 مليون دولار أمريكي فقط، وهو ما يعادل حتى راتب أي مدير تنفيذي في فريق Meta GenAI. ما هذه القوة الشرقية الغامضة؟
نشر حساب ساخر يقلد مؤسس DeepSeek ليانغ وينفنغ صورة مثيرة للاهتمام مباشرة على X:

استخدمت الصورة الميم الرائجة لمطلق النار التركي الشهير عالميًا في عام 2024.
في نهائي المسدس الهوائي لمسافة 10 أمتار ضمن منافسات الرماية في أولمبياد باريس، تمكن الرامي التركي مدحت ديكيتش البالغ من العمر 51 عامًا من الفوز بالميدالية الفضية بهدوء وهو يرتدي نظارة عادية فقط وزوج من سدادات الأذنين لحجب الضوء، وكان يضع في جيبه يدًا واحدة فقط. احتاج جميع الرماة الآخرين الحاضرين إلى عدستين احترافيتين للتركيز وحجب الضوء وزوج من سدادات الأذن المانعة للضوضاء لبدء المنافسة.
منذ أن "اخترق" DeepSeek النموذج المنطقي للذكاء الاصطناعي المفتوح، تعرضت شركات التكنولوجيا الأمريكية الكبرى لضغوط شديدة. اليوم، رد سام ألتمان أخيرًا ببيان رسمي.

هل سيكون عام 2025 هو العام الذي سيؤثر فيه الذكاء الاصطناعي الصيني على التصورات الأمريكية؟
لا يزال لدى DeepSeek بعض الأسرار في جعبته - من المقدر أن يكون مهرجان الربيع استثنائيًا.


