
und das Zeitalter der KI ist in aller Stille angebrochen.
Wahrscheinlich hat niemand damit gerechnet, dass das heißeste Thema dieses chinesischen Neujahrs nicht mehr die traditionelle Internet-Schlacht um den roten Umschlag sein würde, die mit der Frühlingsfest-Gala einhergeht, sondern KI-Unternehmen.
Mit dem Herannahen des Frühlingsfestes haben sich die großen Modellbauunternehmen nicht ausgeruht und eine Reihe von Modellen und Produkten auf den neuesten Stand gebracht. Am meisten von sich reden machte jedoch DeepSeek, ein "großes Modellbauunternehmen", das im vergangenen Jahr gegründet wurde.
Am Abend des 20. Januar, TiefSeek hat die offizielle Version seines schlussfolgernden Modells DeepSeek-R1 veröffentlicht. Mit geringen Trainingskosten hat es direkt eine Leistung trainiert, die dem OpenAI-Schlussfolgermodell o1 in nichts nachsteht. Außerdem ist es völlig kostenlos und quelloffen, was direkt ein Erdbeben in der Branche auslöste.
Es ist das erste Mal, dass eine einheimische KI in großem Umfang für Aufsehen in der Tech-Welt sorgt, insbesondere in den Vereinigten Staaten. Entwickler haben geäußert, dass sie in Erwägung ziehen, DeepSeek zu nutzen, um "alles neu zu machen". Im Zuge dieser Welle erreichte die DeepSeek-Mobilanwendung nach einer Woche der Gärung und nach der Veröffentlichung im Januar schnell die Spitze der Rangliste der kostenlosen Anwendungen im Apple App Store in den USA und übertraf nicht nur ChatGPT, sondern auch andere beliebte Anwendungen in den USA.
Der Erfolg von DeepSeek hat sich sogar direkt auf den US-Aktienmarkt ausgewirkt. Ein Modell, das ohne den Einsatz einer großen Menge teurer Grafikprozessoren trainiert wurde, hat die Menschen dazu veranlasst, den Trainingsweg der KI zu überdenken, was direkt den größten Rückgang von 17% bei der ersten KI-Aktie, NVIDIA, verursachte.
Und das ist noch nicht alles.
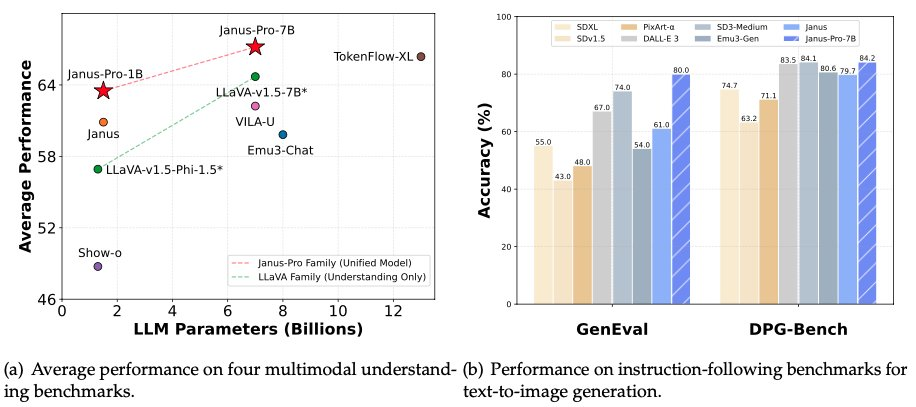
Am frühen Morgen des 28. Januar, in der Nacht vor Silvester, öffnete DeepSeek erneut die Quellen seines multimodalen Modells Janus-Pro-7B und gab bekannt, dass es DALL-E 3 (von OpenAI) und Stable Diffusion in den Benchmark-Tests GenEval und DPG-Bench besiegt hatte.
Wird DeepSeek wirklich die KI-Gemeinschaft umwälzen? Von Inferenzmodellen bis hin zu multimodalen Modellen - strukturiert DeepSeek alles um - das erste Thema des Jahres der Schlange?
Janus Prodie Validierung einer innovativen multimodalen Modellarchitektur
DeepSeek hat dieses Mal spät in der Nacht insgesamt zwei Modelle veröffentlicht: Janus-Pro-7B und Janus-Pro-1B (1,5B Parameter).
Wie der Name schon andeutet, ist das Modell selbst ein Upgrade des Vorgängermodells Janus.
DeepSeek hat das Modell Janus erst im Oktober 2024 zum ersten Mal veröffentlicht. Wie bei DeepSeek üblich, verfügt das Modell über eine innovative Architektur. Wie bei vielen Modellen zur Erzeugung von Visionen wird eine einheitliche Transformer-Architektur verwendet, die gleichzeitig die Aufgaben Text-zu-Bild und Bild-zu-Text verarbeiten kann.
DeepSeek schlägt eine neue Idee vor, die visuelle Kodierung der Verstehens- (Graph-zu-Text) und der Generierungsaufgaben (Text-zu-Graph) zu entkoppeln, was die Flexibilität des Modelltrainings verbessert und die Konflikte und Leistungsengpässe, die durch die Verwendung einer einzigen visuellen Kodierung verursacht werden, effektiv mindert.
Aus diesem Grund hat DeepSeek das Modell Janus genannt. Janus ist der antike römische Gott der Türen und wird mit zwei Gesichtern dargestellt, die in entgegengesetzte Richtungen weisen. Laut DeepSeek heißt das Modell Janus, weil es visuelle Daten mit verschiedenen Augen betrachten, Merkmale getrennt kodieren und dann denselben Körper (Transformer) zur Verarbeitung dieser Eingangssignale verwenden kann.
Diese neue Idee hat zu guten Ergebnissen bei der Janus-Modellreihe geführt. Das Team sagt, dass das Janus-Modell über starke Fähigkeiten zur Befolgung von Befehlen und über mehrsprachige Fähigkeiten verfügt und dass das Modell intelligenter ist und Meme-Bilder lesen kann. Es kann auch Aufgaben wie die Konvertierung von Latex-Formeln und die Umwandlung von Diagrammen in Code bewältigen.
Bei der Modellserie Janus Pro hat das Team den Trainingsprozess des Modells teilweise geändert, was direkt zu Ergebnissen geführt hat, die DALL-E 3 und Stable Diffusion in den Benchmark-Tests GenEval und DPG-Bench übertreffen.
Neben dem Modell selbst hat DeepSeek auch das neue multimodale KI-Framework Janus Flow veröffentlicht, das darauf abzielt, Aufgaben des Bildverständnisses und der Bilderzeugung zu vereinheitlichen.
Das Modell Janus Pro kann bei kurzen Eingabeaufforderungen eine stabilere Ausgabe mit besserer visueller Qualität, mehr Details und der Möglichkeit, einfachen Text zu erzeugen, liefern.
Das Modell kann Bilder generieren und beschreiben, Sehenswürdigkeiten identifizieren (z. B. den Westsee in Hangzhou), Text in Bildern erkennen und Wissen in Bildern beschreiben (z. B. "Tom und Jerry"-Kuchen).
One x.com, Viele Menschen haben bereits begonnen, mit dem neuen Modell zu experimentieren.

Der Bilderkennungstest ist in der obigen Abbildung links dargestellt, während der Bilderzeugungstest rechts zu sehen ist.

Wie zu sehen ist, leistet Janus Pro auch beim Lesen von Bildern mit hoher Präzision gute Arbeit. Es kann gemischte Schriftsätze aus mathematischen Ausdrücken und Text erkennen. In Zukunft könnte es von größerer Bedeutung sein, es mit einem Argumentationsmodell zu verwenden.
Die Parameter von 1B und 7B können neue Anwendungsszenarien erschließen
Bei multimodalen Verstehensaufgaben verwendet das neue Modell Janus-Pro SigLIP-L als visuellen Encoder und unterstützt Bildeingaben von 384 x 384 Pixeln. Bei Aufgaben zur Bilderzeugung verwendet Janus-Pro einen Tokenizer aus einer bestimmten Quelle mit einer Downsampling-Rate von 16.
Dies ist immer noch eine relativ kleine Bildgröße. X Bei der Nutzeranalyse handelt es sich bei dem Janus Pro-Modell eher um eine Richtungsprüfung. Wenn die Überprüfung zuverlässig ist, wird ein produktionsfähiges Modell freigegeben.
Es ist jedoch erwähnenswert, dass das neue Modell, das Janus dieses Mal herausgebracht hat, nicht nur architektonisch innovativ für multimodale Modelle ist, sondern auch eine neue Exploration in Bezug auf die Anzahl der Parameter darstellt.
Das Modell, mit dem DeepSeek Janus Pro dieses Mal verglichen wurde, DALL-E 3, hatte zuvor bekannt gegeben, dass es 12 Milliarden Parameter hat, während das großformatige Modell von Janus Pro nur 7 Milliarden Parameter hat. Bei einer so kompakten Größe ist es schon sehr gut, dass Janus Pro solche Ergebnisse erzielen kann.
Insbesondere das 1B-Modell von Janus Pro verwendet nur 1,5 Milliarden Parameter. Die Benutzer haben bereits Unterstützung für das Modell zu transformers.js im externen Netzwerk hinzugefügt. Dies bedeutet, dass das Modell jetzt 100% in Browsern auf WebGPU laufen kann!
Obwohl der Autor bei Redaktionsschluss noch nicht in der Lage war, das neue Modell von Janus Pro erfolgreich in der Web-Version zu verwenden, ist die Tatsache, dass die Anzahl der Parameter klein genug ist, um direkt auf der Web-Seite zu laufen, dennoch eine erstaunliche Verbesserung.
Dies bedeutet, dass die Kosten für die Bilderzeugung und das Bildverständnis weiter sinken. Wir haben die Möglichkeit, den Einsatz von KI an mehr Stellen zu sehen, an denen Rohbilder und Bildverstehen bisher nicht genutzt werden konnten, was unser Leben verändern wird.
Ein wichtiges Thema im Jahr 2024 ist die Frage, wie KI-Hardware mit zusätzlichem multimodalen Verständnis in unser Leben eingreifen kann. Multimodale Verstehensmodelle mit immer niedrigeren Parametern oder Modelle, von denen erwartet werden kann, dass sie am Rande der Legalität laufen, könnten der KI-Hardware zu einer weiteren Explosion verhelfen.
DeepSeek hat das neue Jahr aufgewirbelt. Kann mit chinesischer KI alles neu gemacht werden?
Die Welt der KI verändert sich täglich.
Rund um das Frühlingsfest im letzten Jahr hat das Sora-Modell von OpenAI die Welt in Aufruhr versetzt. Doch im Laufe des Jahres haben chinesische Unternehmen bei der Videoerstellung vollständig aufgeholt, so dass die Veröffentlichung von Sora am Ende des Jahres ein wenig trostlos erscheint.
Was in diesem Jahr die Welt in Aufruhr versetzt hat, ist Chinas DeepSeek.
DeepSeek ist kein traditionelles Technologieunternehmen, aber es hat äußerst innovative Modelle zu einem Preis hergestellt, der weit unter dem der GPU-Karten großer amerikanischer Hersteller liegt, was seine amerikanischen Kollegen direkt schockiert hat. Die Amerikaner haben ausgerufen: "Die Ausbildung des R1-Modells hat nur 5,6 Millionen US-Dollar gekostet, was sogar dem Gehalt einer Führungskraft im Meta GenAI-Team entspricht. Was ist das für eine geheimnisvolle östliche Macht?"
Ein Parodie-Account, der den DeepSeek-Gründer Liang Wenfeng imitiert, postete ein interessantes Bild direkt auf X:

In dem Bild wurde das trendige Mem des weltberühmten türkischen Schützen im Jahr 2024 verwendet.
Im 10-Meter-Luftpistolen-Finale der Schießwettbewerbe bei den Olympischen Spielen in Paris nahm der 51-jährige türkische Schütze Mithat Dikec, der nur eine gewöhnliche kurzsichtige Brille und ein Paar Schlafohrstöpsel trug, die Silbermedaille in aller Ruhe mit einer Hand in der Tasche entgegen. Alle anderen anwesenden Schützen brauchten zwei professionelle Brillengläser zur Fokussierung und Lichtabschirmung und ein Paar geräuschunterdrückende Ohrstöpsel, um den Wettkampf zu beginnen.
Seit DeepSeek "geknackt" wurde Das Argumentationsmodell von OpenAIDie großen US-Technologieunternehmen sind stark unter Druck geraten. Heute hat Sam Altman endlich mit einer offiziellen Erklärung reagiert.

Wird 2025 das Jahr sein, in dem die chinesische KI die Wahrnehmung der Amerikaner beeinflusst?
DeepSeek hat noch einige Geheimnisse in petto - dies wird ein außergewöhnliches Frühlingsfest werden.


