
iar era IA a sosit în liniște.
Probabil că nimeni nu se aștepta ca în acest An Nou Chinezesc, cel mai fierbinte subiect să nu mai fie tradiționala bătălie a plicului roșu de pe Internet, care s-a asociat cu Gala Festivalului Primăverii, ci companiile AI.
Pe măsură ce Festivalul Primăverii se apropia, companiile majore de modele nu s-au relaxat deloc, actualizând un val de modele și produse. Cu toate acestea, cel mai discutat a fost DeepSeek, o "companie majoră de modele" care a apărut anul trecut.
În seara zilei de 20 ianuarie, AdâncSeek a lansat versiunea oficială a modelului său de raționament DeepSeek-R1. Folosind un cost scăzut de formare, acesta a antrenat direct o performanță care nu este inferioară modelului de raționament OpenAI o1. În plus, acesta este complet gratuit și open source, ceea ce a declanșat în mod direct un cutremur în industrie.
Este pentru prima dată când o inteligență artificială națională provoacă agitație în lumea tehnologiei pe scară largă în întreaga lume, în special în Statele Unite. Dezvoltatorii au exprimat că se gândesc să folosească DeepSeek pentru a "reconstrui totul". În urma acestui val, după o săptămână de fermentare, și chiar abia lansată în ianuarie, aplicația mobilă DeepSeek a ajuns rapid în fruntea clasamentului aplicațiilor gratuite de pe Apple App Store din SUA, depășind nu numai ChatGPT, ci și alte aplicații populare în SUA.
Succesul DeepSeek a afectat direct chiar și piața bursieră din SUA. Un model antrenat fără a utiliza o cantitate uriașă de GPU-uri scumpe a făcut ca oamenii să regândească calea de antrenare a AI, cauzând în mod direct cea mai mare scădere de 17% a primei acțiuni a AI, NVIDIA.
Și asta nu e tot.
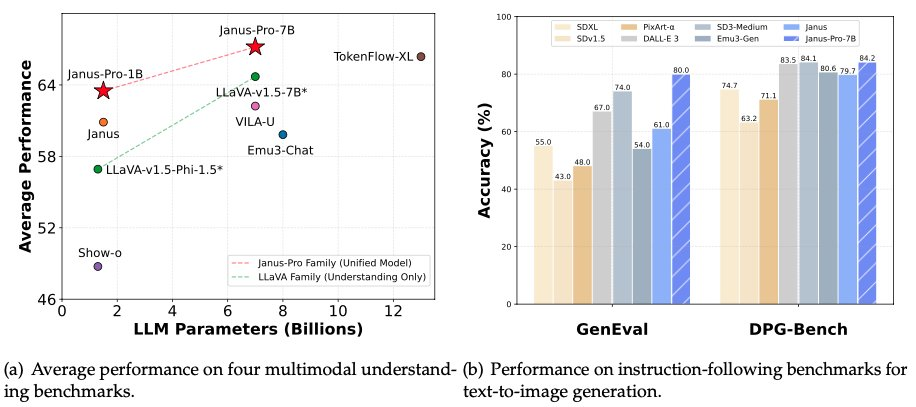
În dimineața zilei de 28 ianuarie, cu o noapte înainte de Anul Nou, DeepSeek a deschis din nou sursa modelului său multimodal Janus-Pro-7B, anunțând că a învins DALL-E 3 (de la OpenAI) și Stable Diffusion în testele de referință GenEval și DPG-Bench.
DeepSeek chiar va mătura comunitatea AI? De la modele de inferență la modele multimodale, DeepSeek restructurează totul primul subiect al Anului Șarpelui?
Janus Pro, validarea unei arhitecturi inovatoare de model multimodal
DeepSeek a lansat un total de două modele târziu în noapte de data aceasta: Janus-Pro-7B și Janus-Pro-1B (parametri 1,5B).
După cum sugerează și numele, modelul în sine este un upgrade față de modelul Janus anterior.
DeepSeek a lansat modelul Janus pentru prima dată abia în octombrie 2024. Ca de obicei cu DeepSeek, modelul adoptă o arhitectură inovatoare. În multe modele de generare a viziunii, modelul adoptă o arhitectură Transformer unificată care poate procesa simultan sarcinile de transformare a textului în imagine și a imaginii în text.
DeepSeek propune o idee nouă, decuplarea codificării vizuale a sarcinilor de înțelegere (de la grafic la text) și de generare (de la text la grafic), care îmbunătățește flexibilitatea formării modelului și ameliorează în mod eficient conflictele și blocajele de performanță cauzate de utilizarea unei singure codificări vizuale.
Acesta este motivul pentru care DeepSeek a denumit modelul Janus. Janus este zeul antic roman al ușilor și este reprezentat cu două fețe orientate în direcții opuse. DeepSeek a declarat că modelul este numit Janus deoarece poate privi datele vizuale cu ochi diferiți, poate codifica caracteristicile separat și apoi poate utiliza același corp (Transformer) pentru a procesa aceste semnale de intrare.
Această nouă idee a produs rezultate bune în seria de modele Janus. Echipa spune că modelul Janus are capacități puternice de urmărire a comenzilor, capacități multilingve, iar modelul este mai inteligent, capabil să citească imagini meme. De asemenea, poate gestiona sarcini precum conversia formulelor latex și conversia graficelor în cod.
În seria de modele Janus Pro, echipa a modificat parțial procesul de formare a modelului, care a obținut rezultate directe care au depășit DALL-E 3 și Stable Diffusion în testele de referință GenEval și DPG-Bench.
Pe lângă modelul în sine, DeepSeek a lansat și noul cadru AI multimodal Janus Flow, care vizează unificarea sarcinilor de înțelegere și generare a imaginilor.
Modelul Janus Pro poate furniza rezultate mai stabile folosind indicații scurte, cu o calitate vizuală mai bună, detalii mai bogate și capacitatea de a genera text simplu.
Modelul poate genera imagini și descrie imagini, poate identifica atracții de referință (cum ar fi Lacul de Vest din Hangzhou), poate recunoaște text în imagini și poate descrie cunoștințe în imagini (cum ar fi prăjiturile "Tom și Jerry").
One x.com, Mulți oameni au început deja să experimenteze cu noul model.

Testul de recunoaștere a imaginilor este prezentat în stânga în figura de mai sus, în timp ce testul de generare a imaginilor este prezentat în dreapta.

După cum se poate observa, Janus Pro face, de asemenea, o treabă bună de citire a imaginilor cu o precizie ridicată. Acesta poate recunoaște scrierea mixtă a expresiilor matematice și a textului. În viitor, ar putea fi mai importantă utilizarea acestuia cu un model de raționament.
Parametrii din 1B și 7B pot debloca noi scenarii de aplicare
În sarcinile de înțelegere multimodală, noul model Janus-Pro utilizează SigLIP-L ca codificator vizual și acceptă intrări de imagini de 384 x 384 pixeli. În sarcinile de generare a imaginilor, Janus-Pro utilizează un tokenizer dintr-o sursă specifică cu o rată de downsampling de 16.
Aceasta este încă o dimensiune relativ mică a imaginii. X În ceea ce privește analiza utilizatorului, modelul Janus Pro este mai degrabă o verificare direcțională. Dacă verificarea este fiabilă, va fi lansat un model care poate fi pus în producție.
Cu toate acestea, este demn de remarcat faptul că noul model lansat de Janus de această dată nu este doar inovator din punct de vedere arhitectural pentru modelele multimodale, ci și o nouă explorare în ceea ce privește numărul de parametri.
Modelul comparat de DeepSeek Janus Pro de această dată, DALL-E 3, a anunțat anterior că are 12 miliarde de parametri, în timp ce modelul de dimensiuni mari al Janus Pro are doar 7 miliarde de parametri. Cu o dimensiune atât de compactă, este deja foarte bine că Janus Pro poate obține astfel de rezultate.
În special, modelul 1B al Janus Pro utilizează doar 1,5 miliarde de parametri. Utilizatorii au adăugat deja suport pentru model la transformers.js pe rețeaua externă. Aceasta înseamnă că modelul poate rula acum 100% în browsere pe WebGPU!
Deși, până la închiderea ediției, autorul nu a reușit încă să utilizeze cu succes noul model de Janus Pro pe versiunea web, faptul că numărul de parametri este suficient de mic pentru a fi rulat direct pe partea web reprezintă totuși o îmbunătățire uimitoare.
Aceasta înseamnă că costul generării de imagini/înțelegerii imaginilor continuă să scadă. Avem oportunitatea de a vedea utilizarea inteligenței artificiale în mai multe locuri în care imaginile brute și înțelegerea imaginilor nu puteau fi utilizate înainte, schimbându-ne viața.
Un punct de interes major în 2024 îl reprezintă modul în care hardware-ul IA cu înțelegere multimodală sporită poate interveni în viața noastră. Modelele de înțelegere multimodală cu parametri din ce în ce mai mici sau modelele care se pot aștepta să funcționeze la limită pot permite hardware-ului IA să explodeze în continuare.
DeepSeek a tulburat noul an. Poate fi totul refăcut cu ajutorul inteligenței artificiale chinezești?
Lumea inteligenței artificiale se schimbă de la o zi la alta.
În jurul Festivalului Primăverii de anul trecut, ceea ce a agitat lumea a fost modelul Sora al OpenAI. Cu toate acestea, pe parcursul anului, companiile chineze au recuperat complet decalajul în ceea ce privește generarea de videoclipuri, ceea ce face ca lansarea lui Sora la sfârșitul anului să pară puțin cam sumbră.
Anul acesta, DeepSeek al Chinei a stârnit interesul lumii.
DeepSeek nu este o companie tehnologică tradițională, dar a realizat modele extrem de inovatoare la un cost mult mai mic decât cel al cardurilor GPU ale marilor companii americane de modele, ceea ce a șocat direct omologii săi americani. Americanii au exclamat: "Pregătirea modelului R1 a costat doar 5,6 milioane de dolari americani, ceea ce este chiar echivalent cu salariul oricărui executiv din echipa Meta GenAI. Ce este această misterioasă putere orientală?".
Un cont de parodie care îl imita pe fondatorul DeepSeek, Liang Wenfeng, a postat o imagine interesantă direct pe X:

Imaginea a folosit meme-ul trending al faimosului shooter turc din 2024.
În finala probei de tir cu pistolul cu aer comprimat de 10 metri de la Jocurile Olimpice de la Paris, trăgătorul turc Mithat Dikec, în vârstă de 51 de ani, purtând doar o pereche de ochelari obișnuiți pentru miopi și o pereche de dopuri de urechi pentru somn, a încasat cu calm medalia de argint cu o singură mână în buzunar. Toți ceilalți trăgători prezenți au avut nevoie de două lentile profesionale pentru focalizare și blocarea luminii și de o pereche de dopuri de urechi cu anulare a zgomotului pentru a începe competiția.
Deoarece DeepSeek a "spart" Modelul de raționament al OpenAI, marile companii americane de tehnologie au fost supuse unor presiuni intense. Astăzi, Sam Altman a răspuns în cele din urmă cu o declarație oficială.

Va fi 2025 anul în care inteligența artificială chineză va afecta percepția americanilor?
DeepSeek are încă câteva secrete în mânecă - acesta este destinat să fie un Festival de primăvară extraordinar.



