قامت شركة DeepSeek بتحديث موقعها الإلكتروني.
في الساعات الأولى من ليلة رأس السنة الجديدة، أعلنت شركة DeepSeek فجأة على GitHub أن مساحة مشروع جانوس قد فتحت مصدر نموذج Janus-Pro والتقرير الفني.
أولاً، دعنا نسلط الضوء على بعض النقاط الرئيسية:
- إن طراز Janus-Pro الذي تم إصداره هذه المرة هو نموذج متعدد الوسائط أداء مهام الفهم متعدد الوسائط وتوليد الصور في نفس الوقت. لديها ما مجموعه نسختان من المعلمات, Janus-Pro-1B و Janus-Pro-7B.
- إن الابتكار الأساسي في Janus-Pro هو فصل فهم وتوليد متعدد الوسائط، وهما مهمتان مختلفتان. وهذا يسمح بإكمال هاتين المهمتين بكفاءة في نفس النموذج.
- يتوافق Janus-Pro مع بنية نموذج Janus الذي أصدرته شركة DeepSeek في أكتوبر/تشرين الأول الماضي، ولكن في ذلك الوقت لم يكن لدى Janus حجم كبير. أخبرنا الدكتور تشارلز، وهو خبير خوارزميات في مجال الرؤية، أن نموذج جانوس السابق كان "متوسطاً" و"ليس بجودة نموذج لغة DeepSeek".

وهو يهدف إلى حل المشكلة الصعبة التي تواجهها الصناعة: تحقيق التوازن بين الفهم متعدد الوسائط وتوليد الصور
وفقًا للمقدمة الرسمية لموقع DeepSeek, Janus-Pro لا يمكنه فقط فهم الصور واستخراج النص الموجود في الصور وفهمه فحسب، بل يمكنه أيضًا توليد الصور في الوقت نفسه.
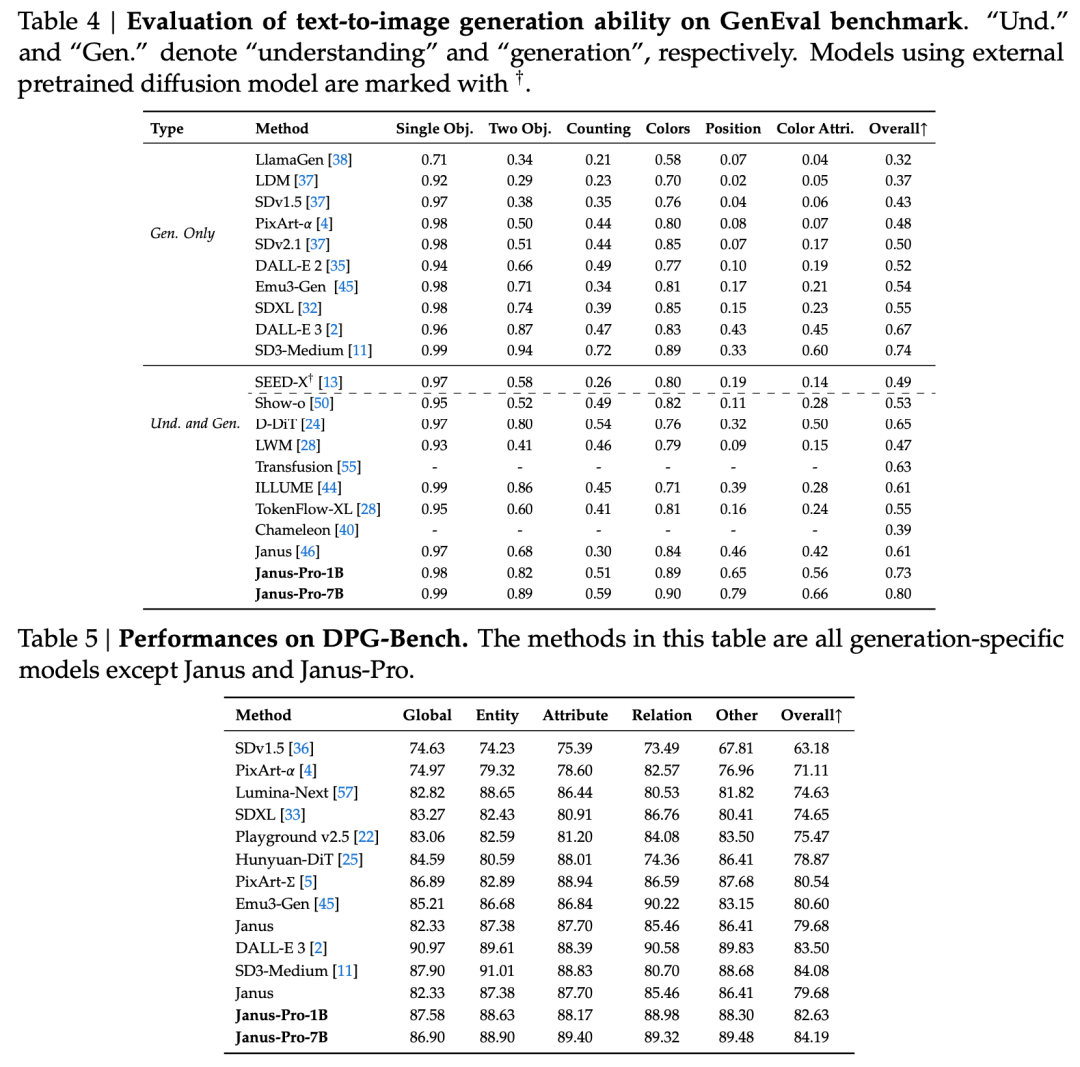
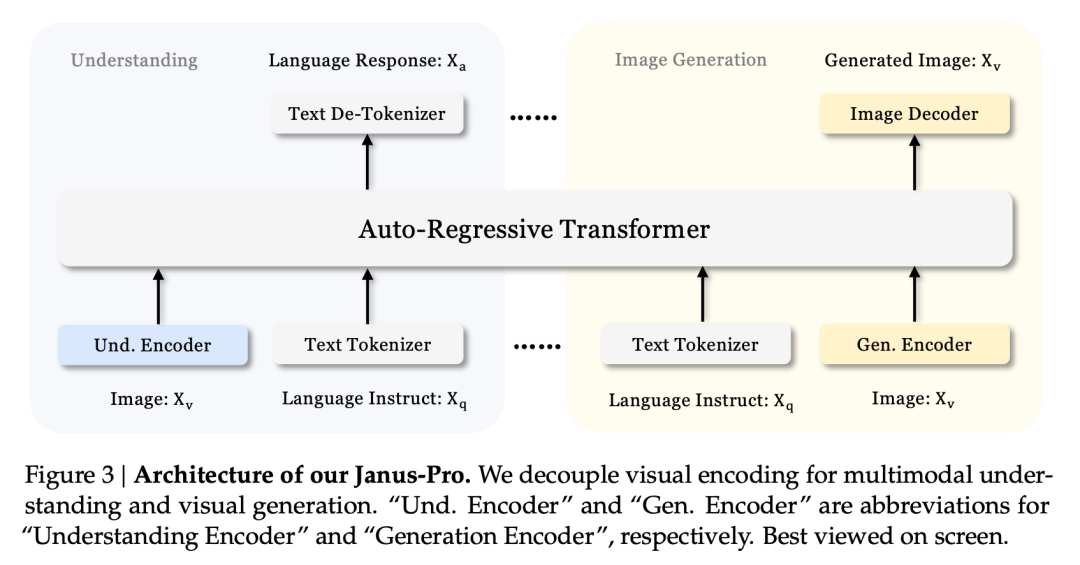
يشير التقرير الفني إلى أنه بالمقارنة مع النماذج الأخرى من نفس النوع والرتبة، فإن نتائج Janus-Pro-7B في مجموعتي اختبار GenEval وDPG-Bench تفوق تلك الموجودة في الطرازات الأخرى مثل SD3-Medium وDALL-E 3.
يعطي المسؤول أيضًا أمثلة 👇:
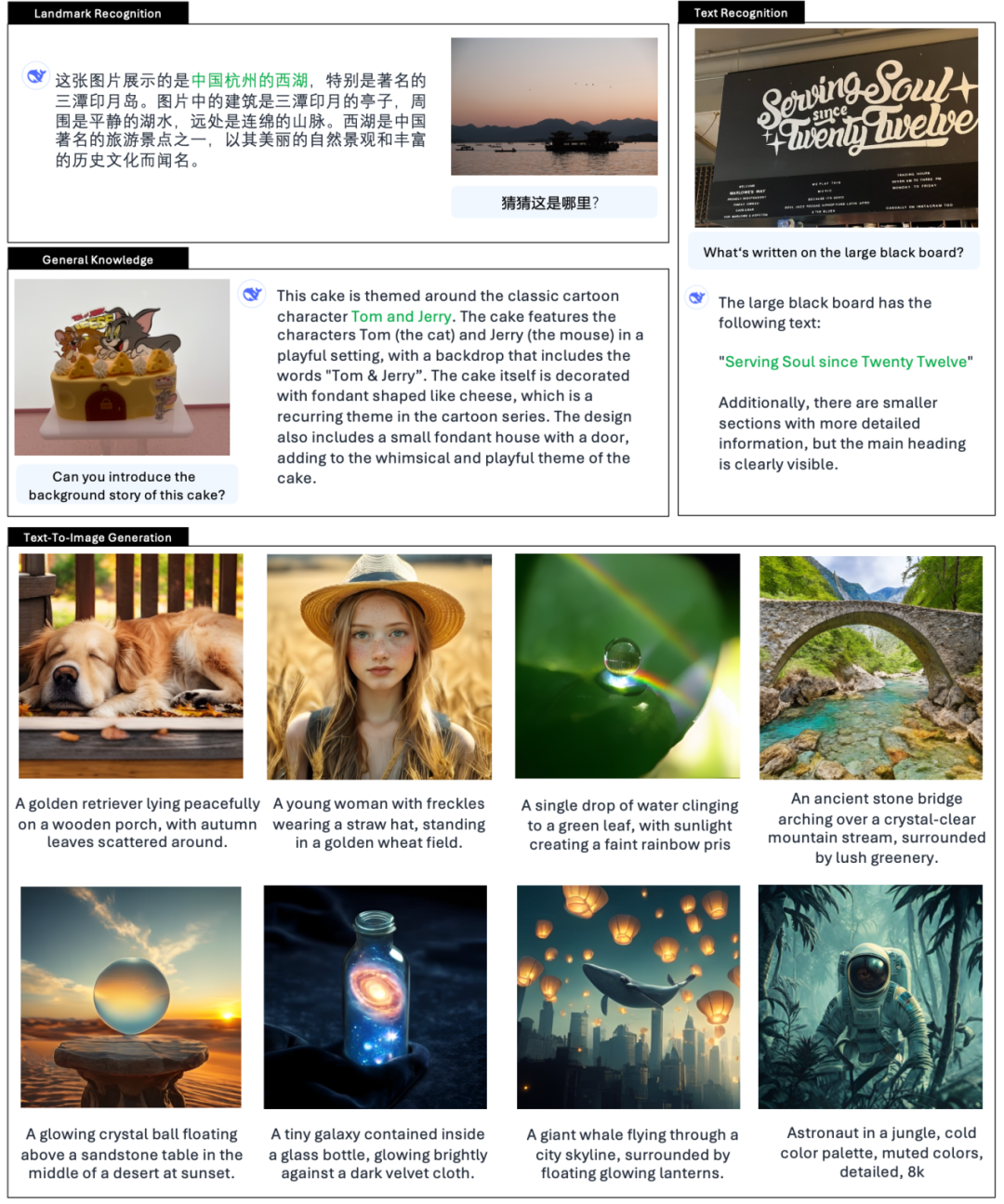
هناك أيضاً العديد من مستخدمي الإنترنت على X يجربون الميزات الجديدة.

ولكن هناك أيضاً أعطال عرضية.
بالرجوع إلى الأوراق الفنية على ديبسيك، وجدنا أن Janus Pro هو تحسين يعتمد على Janus، والذي تم إصداره منذ ثلاثة أشهر.
الابتكار الأساسي لهذه السلسلة من النماذج هو فصل مهام الفهم البصري عن مهام التوليد البصري، بحيث يمكن موازنة تأثيرات المهمتين.
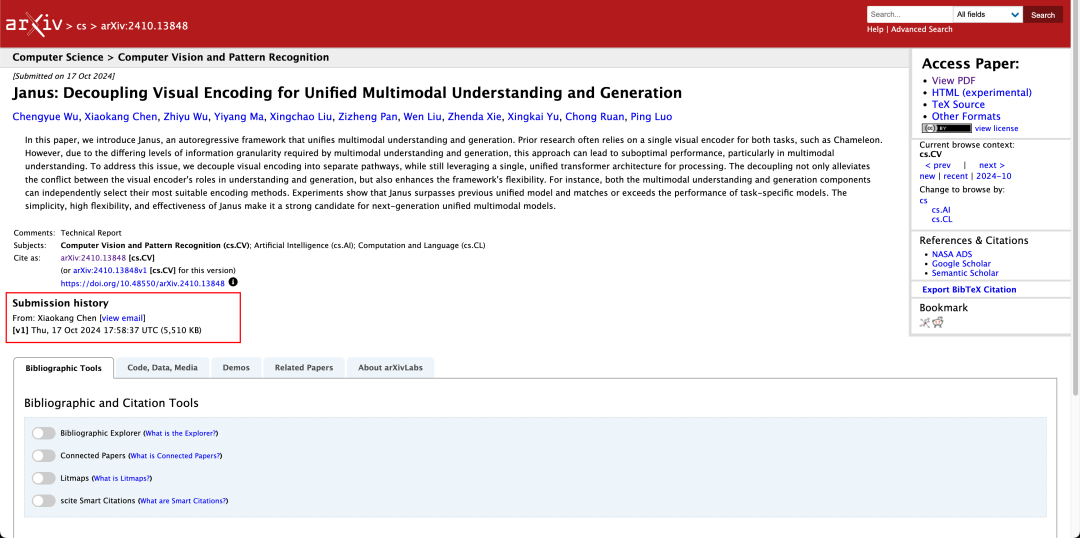
ليس من غير المألوف أن يقوم النموذج بأداء فهم وتوليد متعدد الوسائط في نفس الوقت. يتمتع كل من D-DiT و TokenFlow-XL في مجموعة الاختبار هذه بهذه القدرة.
ومع ذلك، فإن ما يميز جانوس هو أن من خلال فصل المعالجة، فإن النموذج الذي يمكنه إجراء فهم وتوليد متعدد الوسائط يوازن بين فعالية المهمتين.
تعد الموازنة بين فعالية المهمتين مشكلة صعبة في هذه الصناعة. في السابق، كان التفكير في السابق هو استخدام نفس أداة التشفير لتنفيذ الفهم والتوليد متعدد الوسائط قدر الإمكان.
وتتمثل مزايا هذا النهج في بساطة البنية وعدم وجود نشر زائد عن الحاجة، والمواءمة مع نماذج النصوص (التي تستخدم أيضًا نفس الأساليب لتحقيق توليد النص وفهم النص). حجة أخرى هي أن هذا الدمج بين القدرات المتعددة يمكن أن يؤدي إلى درجة معينة من الظهور.
ومع ذلك، في الواقع، بعد دمج التوليد والفهم، ستتعارض المهمتان في الواقع - يتطلب فهم الصورة أن يقوم النموذج بالتجريد في أبعاد عالية واستخراج الدلالات الأساسية للصورة، وهو أمر منحاز نحو المستوى الكلي. من ناحية أخرى، يركز توليد الصور على التعبير عن التفاصيل المحلية وتوليدها على مستوى البكسل.
تتمثل الممارسة المعتادة في الصناعة في إعطاء الأولوية لقدرات توليد الصور. وينتج عن ذلك نماذج متعددة الوسائط توليد صور عالية الجودة، ولكن نتائج فهم الصور غالبًا ما تكون متواضعة.
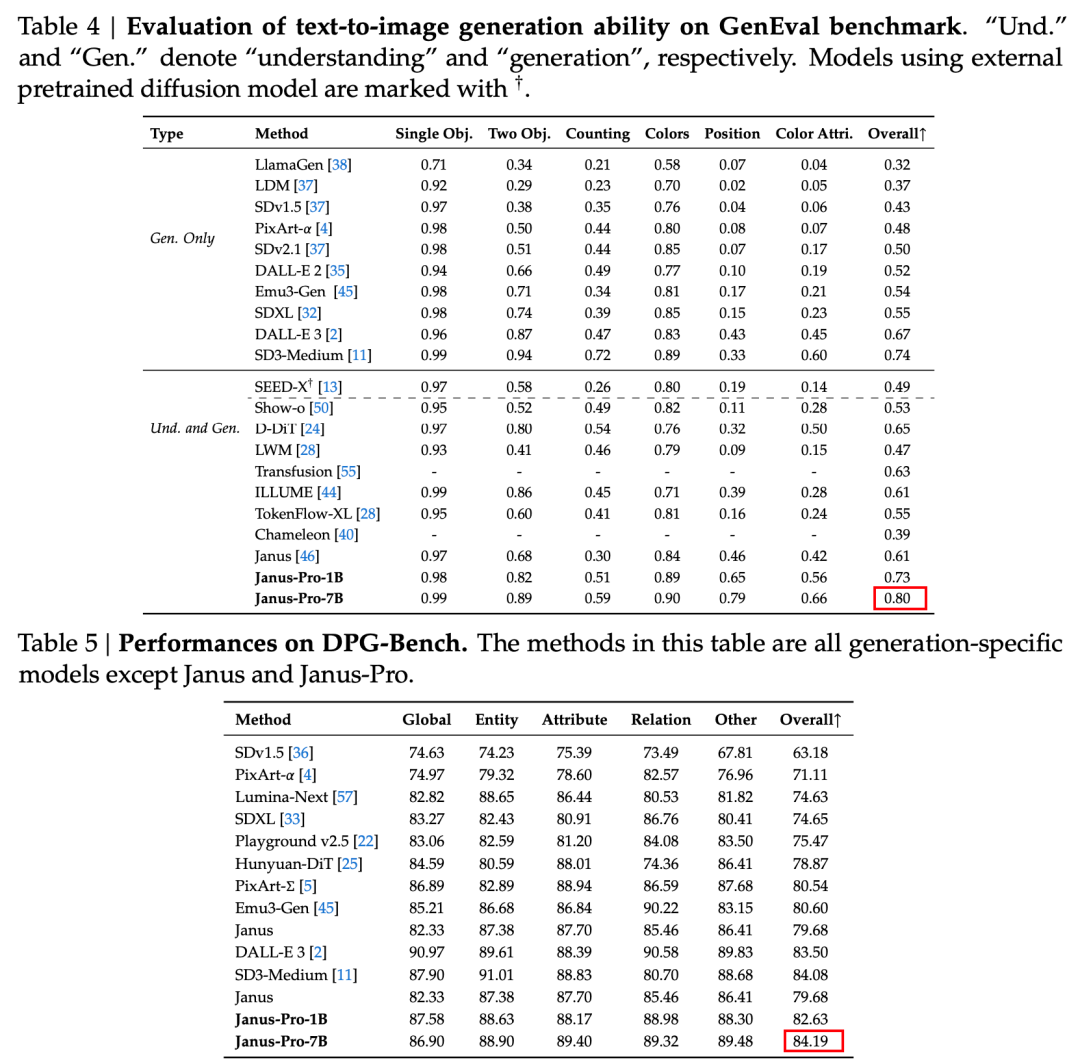
بنية جانوس المنفصلة واستراتيجية التدريب المحسّنة ل Janus-Pro
تسمح بنية جانوس المنفصلة للنموذج بتحقيق التوازن بين مهام الفهم والتوليد من تلقاء نفسه.
ووفقًا للنتائج الواردة في التقرير الفني الرسمي، سواء كان الأمر يتعلق بالفهم متعدد الوسائط أو توليد الصور، فإن أداء Janus-Pro-7B جيد على مجموعات اختبار متعددة.

للفهم متعدد الوسائط, حقق Janus-Pro-7B المركز الأول في أربع من مجموعات بيانات التقييم السبع، والمركز الثاني في المجموعات الثلاث المتبقية، متأخرًا قليلاً عن النموذج الأعلى تصنيفًا.
لتوليد الصور, حقق Janus-Pro-7B المركز الأول في النتيجة الإجمالية على مجموعتي بيانات تقييم GenEval وDPG-Bench.
ويرجع هذا التأثير متعدد المهام بشكل أساسي إلى استخدام سلسلة Janus لجهازي تشفير بصريين لمهام مختلفة:
- فهم التشفير: تُستخدم لاستخراج السمات الدلالية في الصور لمهام فهم الصور (مثل الأسئلة والأجوبة على الصور، والتصنيف البصري، وما إلى ذلك).
- المشفر التوليدي: تحويل الصور إلى تمثيل منفصل (على سبيل المثال، باستخدام أداة تشفير VQ) لمهام تحويل النص إلى صورة.
مع هذه البنية يمكن للنموذج تحسين أداء كل مشفر بشكل مستقل، بحيث يمكن لكل من مهام الفهم والتوليد متعدد الوسائط تحقيق أفضل أداء لكل منهما.
هذه البنية المنفصلة مشتركة بين Janus-Pro وJanus. إذن، ما هي التكرارات التي شهدها Janus-Pro في الأشهر القليلة الماضية؟
كما يتبين من نتائج مجموعة التقييم، فإن الإصدار الحالي من Janus-Pro-1B يتمتع بتحسن بحوالي 10% إلى 20% في درجات مجموعات التقييم المختلفة مقارنةً بـ Janus السابق. ويتمتع الإصدار Janus-Pro-7B بأعلى تحسن بحوالي 45% مقارنةً بـ Janus بعد زيادة عدد المعلمات.

فيما يتعلق بتفاصيل التدريب، يشير التقرير الفني إلى أن الإصدار الحالي من Janus-Pro، مقارنةً بنموذج جانوس السابق، يحتفظ بتصميم البنية الأساسية المنفصلة، بالإضافة إلى ذلك يكرر حجم البارامتر، واستراتيجية التدريب، وبيانات التدريب.
أولاً، دعونا نلقي نظرة على المعلمات.
كان الإصدار الأول من Janus يحتوي على معلمات 1.3B فقط، ويتضمن الإصدار الحالي من Pro نماذج بمعلمات 1B و7B.
يعكس هذان الحجمان قابلية التوسع في بنية Janus. وقد تم استخدام النموذج 1B، وهو الأخف وزناً، من قبل مستخدمين خارجيين للتشغيل في المتصفح باستخدام WebGPU.
يوجد أيضًا فإن استراتيجية التدريب.
وتماشيًا مع تقسيم مراحل التدريب في جانوس، يحتوي Janus Pro على ثلاث مراحل تدريبية، وتقسمها الورقة البحثية مباشرةً إلى المرحلة الأولى والمرحلة الثانية والمرحلة الثالثة.
مع الاحتفاظ بأفكار التدريب الأساسية وأهداف التدريب في كل مرحلة، أدخلت Janus-Pro تحسينات على مدة التدريب وبيانات التدريب في المراحل الثلاث. وفيما يلي التحسينات المحددة في المراحل الثلاث:
المرحلة الأولى - وقت التدريب الأطول
مقارنةً بـ Janus، قام Janus-Pro بإطالة وقت التدريب في المرحلة الأولى، خاصةً في تدريب المحولات ورؤوس الصور في الجزء المرئي. هذا يعني أن تعلم الميزات البصرية قد مُنح وقتًا أطول في التدريب، ومن المأمول أن يتمكن النموذج من فهم الميزات التفصيلية للصور (مثل التحويل من بكسل إلى دلالي).
يساعد هذا التدريب الموسع في ضمان عدم تشويش تدريب الجزء المرئي على الوحدات الأخرى.
المرحلة الثانية - إزالة بيانات ImageNet وإضافة بيانات متعددة الوسائط
في المرحلة الثانية، أشار جانوس سابقًا إلى PixArt وتم تدريبه على جزأين. تم تدريب الجزء الأول باستخدام مجموعة بيانات ImageNet لمهمة تصنيف الصور، وتم تدريب الجزء الثاني باستخدام بيانات تحويل النص إلى صورة عادية. تم قضاء حوالي ثلثي الوقت في المرحلة الثانية في التدريب على الجزء الأول.
Janus-Pro يزيل تدريب ImageNet في المرحلة الثانية. يسمح هذا التصميم للنموذج بالتركيز على بيانات تحويل النص إلى صورة أثناء تدريب المرحلة الثانية. وفقًا للنتائج التجريبية، يمكن أن يؤدي ذلك إلى تحسين الاستفادة من بيانات تحويل النص إلى صورة بشكل كبير.
وبالإضافة إلى تعديل تصميم طريقة التدريب، لم تعد مجموعة بيانات التدريب المستخدمة في المرحلة الثانية تقتصر على مهمة تصنيف صورة واحدة، بل تتضمن أيضًا المزيد من الأنواع الأخرى من البيانات متعددة الوسائط، مثل وصف الصورة والحوار، للتدريب المشترك.
المرحلة الثالثة - تحسين نسبة البيانات
في المرحلة الثالثة من التدريب، يقوم Janus-Pro بضبط نسبة الأنواع المختلفة من بيانات التدريب.
في السابق، كانت نسبة بيانات الفهم متعدد الوسائط وبيانات النص العادي وبيانات تحويل النص إلى صورة في بيانات التدريب التي استخدمها جانوس في المرحلة الثالثة هي 7:3:10. يقلل Janus-Pro من نسبة النوعين الأخيرين من البيانات ويعدل نسبة الأنواع الثلاثة من البيانات إلى 5:1:4، أي إيلاء المزيد من الاهتمام لمهمة الفهم متعدد الوسائط.
لنلقِ نظرة على بيانات التدريب.
مقارنةً بـ Janus، يزيد Janus-Pro هذه المرة بشكل كبير من كمية بيانات اصطناعية.
فهو يوسّع من كمية وتنوع بيانات التدريب لفهم متعدد الوسائط وتوليد الصور.
توسيع نطاق بيانات الفهم المتعدد الوسائط:
Janus-Pro تشير إلى مجموعة بيانات DeepSeek-VL2 أثناء التدريب وتضيف حوالي 90 مليون نقطة بيانات إضافية، بما في ذلك ليس فقط مجموعات بيانات وصف الصور، ولكن أيضًا مجموعات بيانات المشاهد المعقدة مثل الجداول والمخططات والمستندات.
خلال مرحلة الضبط الدقيق الخاضع للإشراف (المرحلة الثالثة)، يستمر في إضافة مجموعات البيانات المتعلقة بتحسين تجربة فهم MEME والحوار (بما في ذلك الحوار الصيني).
توسيع نطاق بيانات التوليد المرئي:
كانت بيانات العالم الحقيقي الأصلية ذات جودة رديئة ومستويات ضوضاء عالية، مما تسبب في إنتاج مخرجات غير مستقرة وصور ذات جودة جمالية غير كافية في مهام تحويل النص إلى صورة.
أضافت Janus-Pro حوالي 72 مليون بيانات اصطناعية جديدة عالية الجمالية إلى مرحلة التدريب، مما رفع نسبة البيانات الحقيقية إلى البيانات الاصطناعية في مرحلة ما قبل التدريب إلى 1:1.
تم أخذ جميع مطالبات البيانات التركيبية من مصادر عامة. وقد أظهرت التجارب أن إضافة هذه البيانات تجعل النموذج يتقارب بشكل أسرع، كما أن الصور التي تم إنشاؤها تتمتع بتحسينات واضحة في الاستقرار والجمال البصري.
استمرار ثورة الكفاءة؟
بشكل عام، مع هذا الإصدار، جلبت DeepSeek ثورة الكفاءة إلى النماذج المرئية.
على عكس النماذج البصرية التي تركز على وظيفة واحدة أو النماذج متعددة الوسائط التي تفضل مهمة محددة، فإن Janus-Pro يوازن بين تأثيرات المهمتين الرئيسيتين لتوليد الصور والفهم متعدد الوسائط في نفس النموذج.
وعلاوة على ذلك، وعلى الرغم من صغر معلماته، إلا أنه تفوق على أوبن إيه آي DALL-E 3 و SD3-Medium في التقييم.
تمديدها إلى أرض الواقع، تحتاج المؤسسة فقط إلى نشر نموذج لتنفيذ وظيفتي توليد الصور وفهمها مباشرةً. إلى جانب حجم 7B فقط، فإن صعوبة وتكلفة النشر أقل بكثير.
فيما يتعلق بالإصدارين السابقين من R1 و V3، يتحدى DeepSeek القواعد الحالية للعبة مع "ابتكار معماري مدمج، ونماذج خفيفة الوزن، ونماذج مفتوحة المصدر، وتكاليف تدريب منخفضة للغاية". وهذا هو سبب الذعر الذي أصاب عمالقة التكنولوجيا الغربية وحتى وول ستريت.
وأخيراً، ردّ سام ألتمان، الذي انجرف مع الرأي العام لعدة أيام، بشكل إيجابي على المعلومات حول DeepSeek على X - بينما أشاد بـ R1، قال إن OpenAI سيصدر بعض الإعلانات.