Menjelang Festival Musim Semi, model DeepSeek-R1 dirilis. Dengan arsitektur RL murni, model ini telah belajar dari inovasi hebat CoT, dan mengungguli ChatGPT dalam matematika, kode, dan penalaran logis.
Selain itu, bobot model sumber terbuka, biaya pelatihan yang rendah, dan harga API yang murah telah membuat DeepSeek menjadi populer di internet, bahkan menyebabkan harga saham NVIDIA dan ASML anjlok untuk sementara waktu.
Sementara meledak dalam popularitas, DeepSeek juga merilis versi terbaru dari model besar multimodal Janus (Janus), Janus-Pro, yang mewarisi arsitektur terpadu dari generasi pemahaman dan generasi multimodal sebelumnya, dan mengoptimalkan strategi pelatihan, menskalakan data pelatihan dan ukuran model, menghadirkan kinerja yang lebih kuat.

Janus-Pro
Janus-Pro adalah model bahasa multimodal terpadu (MLLM) yang secara bersamaan dapat memproses tugas pemahaman multimodal dan tugas pembuatan, yaitu dapat memahami konten gambar dan juga menghasilkan teks.
Ini memisahkan penyandi visual untuk pemahaman dan pembuatan multimodal (yaitu, tokenizer yang berbeda digunakan untuk input pemahaman gambar dan input serta output pembuatan gambar), dan memprosesnya menggunakan transformator autoregresif terpadu.
Sebagai model pemahaman dan generasi multimodal tingkat lanjut, ini adalah versi upgrade dari model Janus sebelumnya.
Dalam mitologi Romawi, Janus (Janus) adalah dewa pelindung bermuka dua yang melambangkan kontradiksi dan transisi. Dia memiliki dua wajah, yang juga menunjukkan bahwa model Janus dapat memahami dan menghasilkan gambar, yang sangat tepat. Jadi, apa sebenarnya yang sudah ditingkatkan oleh PRO?
Janus, sebagai model kecil 1.3B, lebih mirip versi pratinjau daripada versi resmi. Model ini mengeksplorasi pemahaman dan pembangkitan multimodal terpadu, tetapi memiliki banyak masalah, misalnya, efek pembangkitan gambar yang tidak stabil, penyimpangan yang besar dari petunjuk pengguna, dan detail yang tidak memadai.
Versi Pro mengoptimalkan strategi pelatihan, meningkatkan kumpulan data pelatihan, dan menyediakan model yang lebih besar (7B) untuk dipilih sambil menyediakan model 1B.
Arsitektur model
Jaus-Pro dan Janus identik dalam hal arsitektur model. (Hanya 1,3 miliar! Janus menyatukan pemahaman dan generasi multimodal)
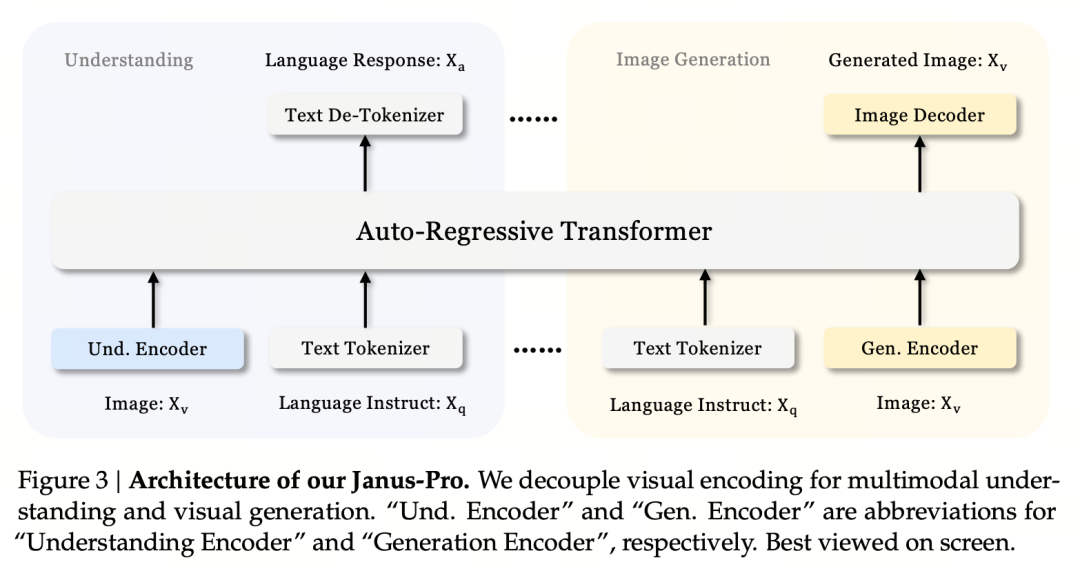
Prinsip desain intinya adalah memisahkan pengkodean visual untuk mendukung pemahaman dan pembuatan multimodal. Janus-Pro mengkodekan input gambar/teks asli secara terpisah, mengekstrak fitur dimensi tinggi, dan memprosesnya melalui Transformer autoregresif terpadu.
Pemahaman gambar multimodal menggunakan SigLIP untuk menyandikan fitur gambar (penyandi biru pada gambar di atas), dan tugas pembangkitan menggunakan tokenizer VQ untuk mendiskritkan gambar (penyandi kuning pada gambar di atas). Terakhir, semua urutan fitur dimasukkan ke LLM untuk diproses
Strategi pelatihan
Dari segi strategi pelatihan, Janus-Pro telah membuat lebih banyak perbaikan. Versi lama Janus menggunakan strategi pelatihan tiga tahap, di mana Tahap I melatih adaptor input dan kepala pembangkitan gambar untuk pemahaman gambar dan pembangkitan gambar, Tahap II melakukan pra-pelatihan terpadu, dan Tahap III menyempurnakan encoder pemahaman atas dasar ini. (Strategi pelatihan Janus ditunjukkan pada gambar di bawah ini).
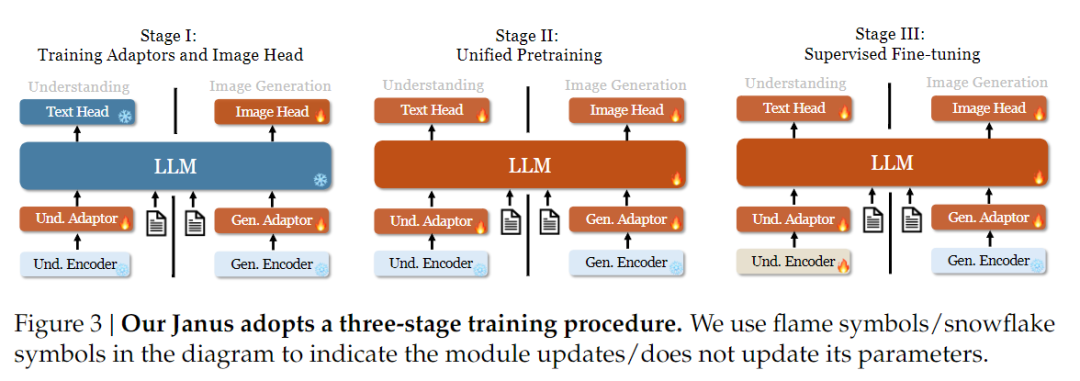
Namun demikian, strategi ini menggunakan metode PixArt untuk membagi pelatihan pembuatan teks-ke-gambar pada Tahap II, yang menghasilkan efisiensi komputasi yang rendah.
Untuk itu, kami memperpanjang waktu pelatihan Tahap I dan menambahkan pelatihan dengan data ImageNet, sehingga model dapat secara efektif memodelkan ketergantungan piksel dengan parameter LLM yang tetap. Pada Tahap II, kami membuang data ImageNet dan langsung menggunakan data pasangan teks-gambar untuk melatih, yang meningkatkan efisiensi pelatihan. Selain itu, kami menyesuaikan rasio data pada Tahap III (data grafik multimodal: teks saja: visual-semantik dari 7:3:10 menjadi 5:1:4), sehingga meningkatkan pemahaman multimodal sekaligus mempertahankan kemampuan pembuatan visual.
Penskalaan data pelatihan
Janus-Pro juga menskalakan data pelatihan Janus dalam hal pemahaman multimodal dan pembuatan visual.
Pemahaman multimodal: Data pra-pelatihan Tahap II didasarkan pada DeepSeek-VL2 dan mencakup sekitar 90 juta sampel baru, termasuk data keterangan gambar (seperti YFCC) dan data pemahaman tabel, bagan, dan dokumen (seperti Docmatix).
Tahap penyempurnaan yang diawasi Tahap III lebih lanjut memperkenalkan pemahaman MEME, data dialog bahasa Mandarin, dll., untuk meningkatkan kinerja model dalam pemrosesan multi-tugas dan kemampuan dialog.
Pembuatan visual: Versi terdahulu menggunakan data nyata dengan kualitas rendah dan noise yang tinggi, yang memengaruhi stabilitas dan estetika gambar yang dihasilkan teks.
Janus-Pro memperkenalkan sekitar 72 juta data estetika sintetis, sehingga rasio data nyata dan data sintetis menjadi 1:1. Eksperimen telah menunjukkan bahwa data sintetis mempercepat konvergensi model dan secara signifikan meningkatkan stabilitas dan kualitas estetika gambar yang dihasilkan.
Penskalaan model
Janus Pro memperluas ukuran model menjadi 7B, sedangkan versi Janus sebelumnya menggunakan 1,5B DeepSeek-LLM untuk memverifikasi keefektifan pemisahan pengkodean visual. Eksperimen menunjukkan bahwa LLM yang lebih besar secara signifikan mempercepat konvergensi pemahaman multimodal dan pembuatan visual, yang selanjutnya memverifikasi skalabilitas yang kuat dari metode ini.

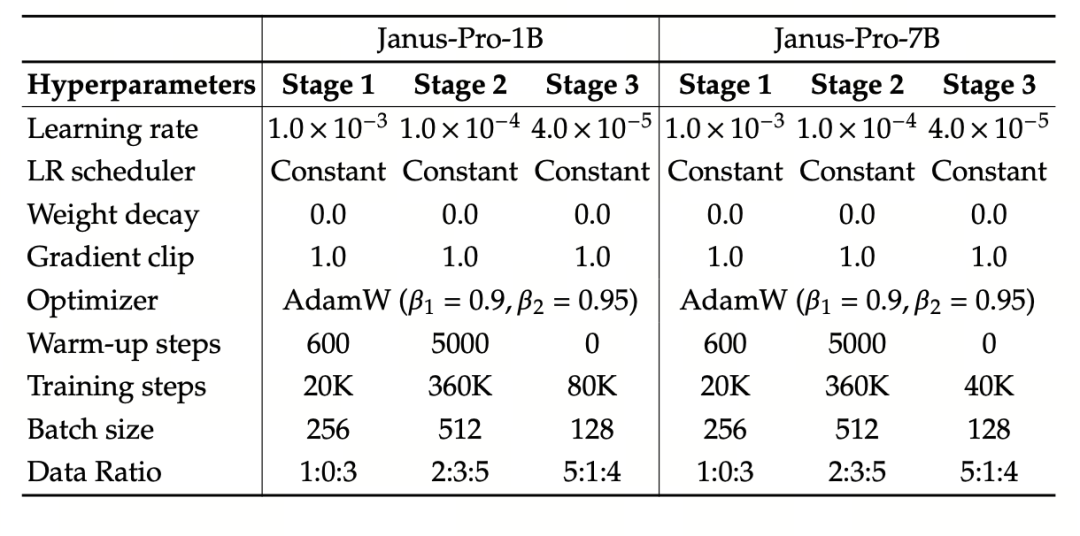
Eksperimen ini menggunakan DeepSeek-LLM (1,5B dan 7B, mendukung urutan maksimum 4096) sebagai model bahasa dasar. Untuk tugas pemahaman multimodal, SigLIP-Large-Patch16-384 digunakan sebagai penyandi visual, ukuran kamus penyandi adalah 16384, kelipatan downsampling gambar adalah 16, dan baik adaptor pemahaman maupun pembangkitan adalah MLP dua lapis.
Pelatihan tahap II menggunakan strategi penghentian awal 270K, semua gambar disesuaikan secara seragam ke resolusi 384×384, dan pengemasan urutan digunakan untuk meningkatkan efisiensi pelatihan. Janus-Pro dilatih dan dievaluasi menggunakan HAI-LLM. Versi 1.5B/7B dilatih pada 16/32 node (8×Nvidia A100 40GB per node) masing-masing selama 9/14 hari.
Evaluasi model
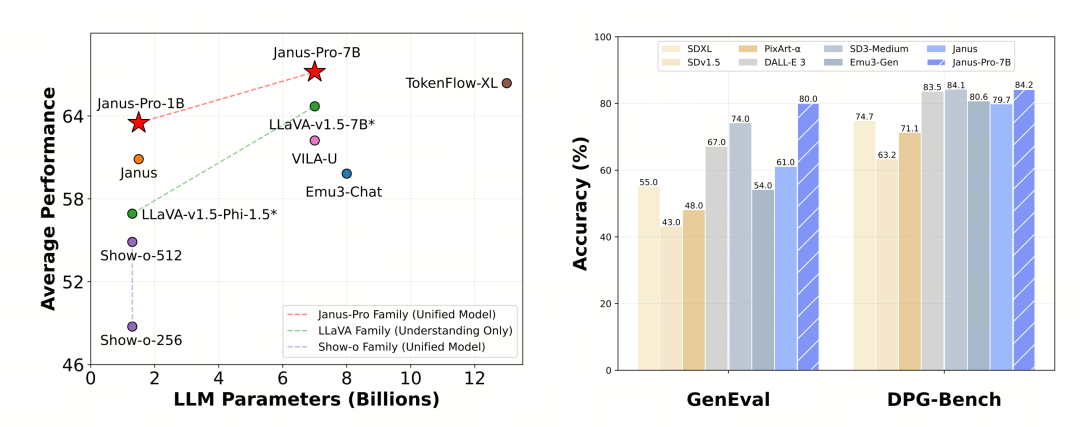
Janus-Pro dievaluasi secara terpisah dalam pemahaman dan pembuatan multimodal. Secara keseluruhan, pemahamannya mungkin agak lemah, tetapi dianggap sangat baik di antara model open source dengan ukuran yang sama (saya kira sebagian besar dibatasi oleh resolusi input tetap dan kemampuan OCR).
Janus-Pro-7B mendapatkan skor 79,2 pada pengujian benchmark MMBench, yang mendekati level model open source tingkat pertama (ukuran yang sama dengan InternVL2.5 dan Qwen2-VL sekitar 82 poin). Namun, ini merupakan peningkatan yang baik dari generasi Janus sebelumnya.
Dari segi pembuatan gambar, peningkatan dari generasi sebelumnya bahkan lebih signifikan, dan ini dianggap sebagai tingkat yang sangat baik di antara model open source. Skor Janus-Pro dalam uji tolok ukur GenEval (0,80) juga melampaui model seperti DALL-E 3 (0,67) dan Stable Diffusion 3 Medium (0,74).