À la veille de la fête du printemps, le modèle DeepSeek-R1 est sorti. Avec son architecture RL pure, il a tiré les leçons des grandes innovations de CoT, et surpasse les performances du modèle DeepSeek-R1. ChatGPT en mathématiques, en code et en raisonnement logique.
En outre, les poids des modèles en source ouverte, les faibles coûts de formation et les prix peu élevés des API ont fait de DeepSeek un succès sur l'internet, provoquant même une chute des cours des actions de NVIDIA et d'ASML pendant un certain temps.
Alors que sa popularité explose, DeepSeek a également publié une version actualisée du grand modèle multimodal Janus (Janus), Janus-Pro, qui hérite de l'architecture unifiée de la génération précédente de compréhension et de génération multimodales, et optimise la stratégie d'entraînement, en augmentant la taille des données d'entraînement et du modèle, ce qui permet d'améliorer les performances.

Janus-Pro
Janus-Pro est un modèle de langage multimodal unifié (MLLM) qui peut traiter simultanément des tâches de compréhension et de génération multimodales, c'est-à-dire qu'il peut comprendre le contenu d'une image et générer du texte.
Il découple les encodeurs visuels pour la compréhension et la génération multimodales (c'est-à-dire que des tokenizers différents sont utilisés pour l'entrée de la compréhension de l'image et pour l'entrée et la sortie de la génération de l'image), et les traite en utilisant un transformateur autorégressif unifié.
En tant que modèle avancé de compréhension et de génération multimodale, il s'agit d'une version améliorée du précédent modèle Janus.
Dans la mythologie romaine, Janus est un dieu gardien à deux visages qui symbolise la contradiction et la transition. Il a deux visages, ce qui suggère également que le modèle Janus peut comprendre et générer des images, ce qui est tout à fait approprié. Qu'est-ce que PRO a amélioré exactement ?
Janus, en tant que petit modèle de 1.3B, ressemble plus à une version préliminaire qu'à une version officielle. Il explore la compréhension et la génération multimodales unifiées, mais présente de nombreux problèmes, tels que des effets de génération d'images instables, des écarts importants par rapport aux instructions de l'utilisateur et des détails inadéquats.
La version Pro optimise la stratégie d'entraînement, augmente l'ensemble des données d'entraînement et fournit un plus grand modèle (7B) à choisir tout en fournissant un modèle 1B.
Architecture du modèle
Jaus-Pro et Janus sont identiques en termes d'architecture du modèle. (Seulement 1.3B ! Janus unifie la compréhension et la génération multimodale)
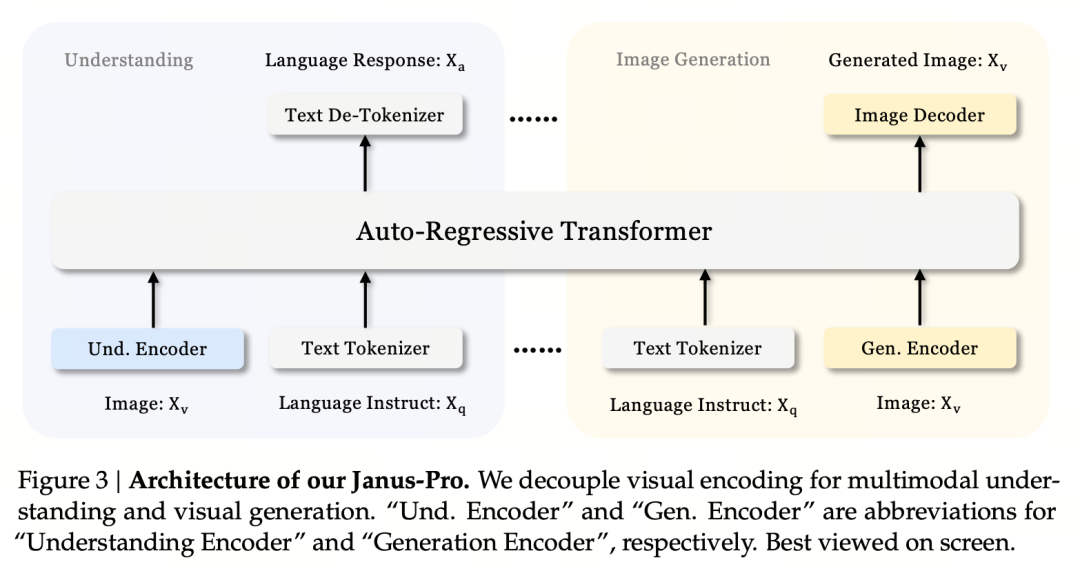
Le principe de base de la conception est de découpler l'encodage visuel pour favoriser la compréhension et la génération multimodales. Janus-Pro encode séparément l'image ou le texte d'origine, extrait des caractéristiques à haute dimension et les traite au moyen d'un transformateur autorégressif unifié.
La compréhension multimodale d'images utilise SigLIP pour encoder les caractéristiques de l'image (encodeur bleu dans la figure ci-dessus), et la tâche de génération utilise le tokenizer VQ pour discrétiser l'image (encodeur jaune dans la figure ci-dessus). Enfin, toutes les séquences de caractéristiques sont introduites dans le LLM pour traitement
Stratégie de formation
En ce qui concerne la stratégie de formation, Janus-Pro a apporté d'autres améliorations. L'ancienne version de Janus utilisait une stratégie de formation en trois étapes, dans laquelle l'étape I entraîne l'adaptateur d'entrée et la tête de génération d'images pour la compréhension et la génération d'images, l'étape II effectue un pré-entraînement unifié et l'étape III affine l'encodeur de compréhension sur cette base. (La stratégie de formation de Janus est illustrée dans la figure ci-dessous).
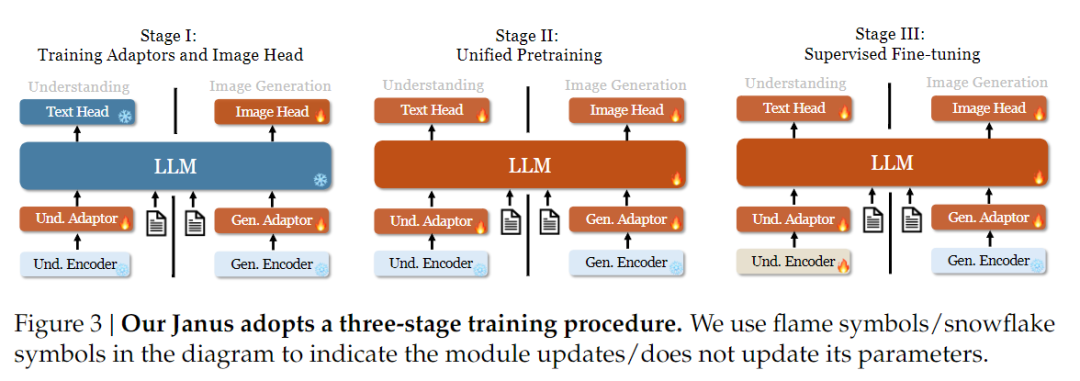
Cependant, cette stratégie utilise la méthode PixArt pour diviser la formation de la génération de texte en image dans l'étape II, ce qui entraîne une faible efficacité de calcul.
À cette fin, nous avons prolongé le temps d'apprentissage de la phase I et ajouté l'apprentissage avec les données ImageNet, de sorte que le modèle puisse modéliser efficacement les dépendances entre les pixels avec des paramètres LLM fixes. À l'étape II, nous avons supprimé les données ImageNet et utilisé directement les données de paires texte-image pour l'entraînement, ce qui améliore l'efficacité de l'entraînement. En outre, nous avons ajusté le ratio de données à l'étape III (données multimodales:texte seul:graphique visuel-sémantique de 7:3:10 à 5:1:4), améliorant ainsi la compréhension multimodale tout en conservant les capacités de génération visuelle.
Mise à l'échelle des données d'apprentissage
Janus-Pro met également à l'échelle les données d'entraînement de Janus en termes de compréhension multimodale et de génération visuelle.
Compréhension multimodale : Les données de pré-entraînement de l'étape II sont basées sur DeepSeek-VL2 et comprennent environ 90 millions de nouveaux échantillons, y compris des données de légende d'images (telles que YFCC) et des données de compréhension de tableaux, de graphiques et de documents (telles que Docmatix).
L'étape III de mise au point supervisée introduit en outre la compréhension de MEME, des données de dialogue chinoises, etc., afin d'améliorer les performances du modèle en matière de traitement multitâche et de capacités de dialogue.
Génération visuelle : Les versions précédentes utilisaient des données réelles de faible qualité et très bruitées, ce qui affectait la stabilité et l'esthétique des images générées par le texte.
Janus-Pro introduit environ 72 millions de données esthétiques synthétiques, ce qui porte le rapport entre les données réelles et les données synthétiques à 1:1. Les expériences ont montré que les données synthétiques accélèrent la convergence des modèles et améliorent considérablement la stabilité et la qualité esthétique des images générées.
Mise à l'échelle du modèle
Janus Pro étend la taille du modèle à 7B, alors que la version précédente de Janus utilisait 1,5B DeepSeek-LLM pour vérifier l'efficacité du découplage de l'encodage visuel. Les expériences montrent qu'un LLM plus grand accélère considérablement la convergence de la compréhension multimodale et de la génération visuelle, ce qui confirme la forte évolutivité de la méthode.

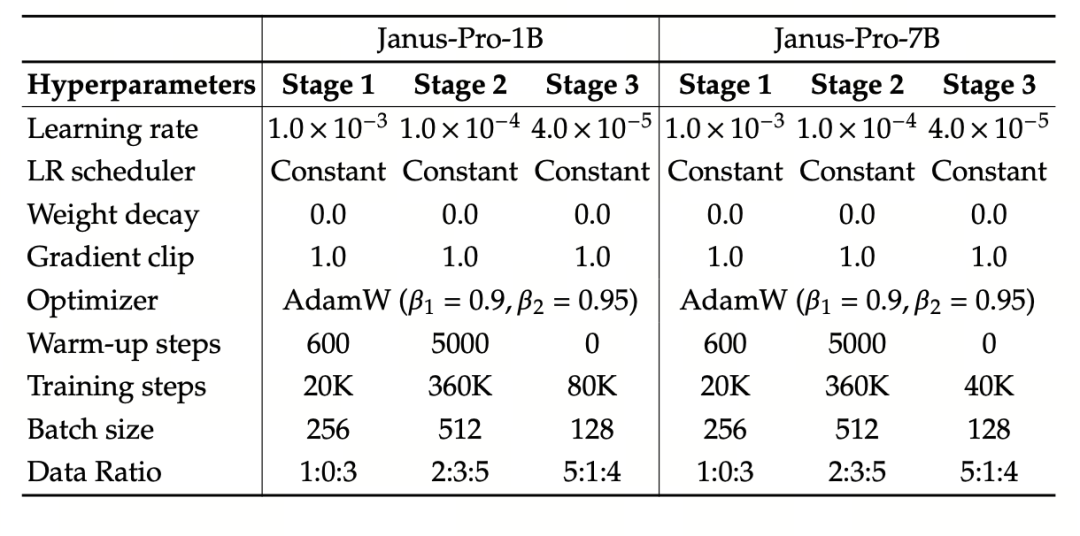
L'expérience utilise DeepSeek-LLM (1.5B et 7B, supportant une séquence maximale de 4096) comme modèle de langage de base. Pour la tâche de compréhension multimodale, SigLIP-Large-Patch16-384 est utilisé comme codeur visuel, la taille du dictionnaire du codeur est de 16384, le multiple de sous-échantillonnage de l'image est de 16, et les adaptateurs de compréhension et de génération sont des MLP à deux couches.
La phase II de la formation utilise une stratégie d'arrêt précoce de 270K, toutes les images sont uniformément ajustées à une résolution de 384×384, et l'emballage des séquences est utilisé pour améliorer l'efficacité de la formation. Le Janus-Pro est entraîné et évalué à l'aide de HAI-LLM. Les versions 1.5B/7B ont été entraînées sur 16/32 nœuds (8×Nvidia A100 40GB par nœud) pendant 9/14 jours respectivement.
Évaluation du modèle
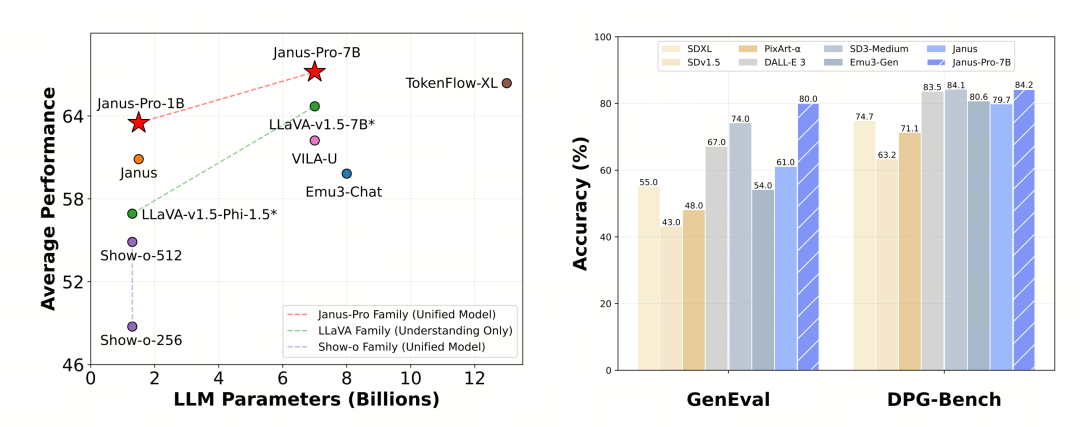
Janus-Pro a été évalué séparément pour la compréhension et la génération multimodales. Dans l'ensemble, la compréhension peut être légèrement faible, mais elle est considérée comme excellente parmi les modèles open source de la même taille (on suppose qu'elle est largement limitée par la résolution d'entrée fixe et les capacités d'OCR).
Le Janus-Pro-7B a obtenu un score de 79,2 au test de référence MMBench, ce qui est proche du niveau des modèles open source de premier plan (la même taille d'InternVL2.5 et de Qwen2-VL est d'environ 82 points). Cependant, il s'agit d'une bonne amélioration par rapport à la génération précédente de Janus.
En termes de génération d'images, l'amélioration par rapport à la génération précédente est encore plus significative et est considérée comme un excellent niveau parmi les modèles open source. Le score de Janus-Pro dans le test de référence GenEval (0,80) dépasse également des modèles tels que DALL-E 3 (0,67) et Stable Diffusion 3 Medium (0,74).