DeepSeek-R1-malli julkaistiin kevätjuhlan aattona. Puhtaan RL-arkkitehtuurin ansiosta se on ottanut oppia CoT:n suurista innovaatioista, ja se on suorituskykyisempi kuin ChatGPT matematiikassa, koodauksessa ja loogisessa päättelyssä.
Lisäksi sen avoimen lähdekoodin mallipainot, alhaiset harjoittelukustannukset ja halvat API-hinnat ovat tehneet DeepSeekistä hitin koko internetissä, mikä on saanut jopa NVIDIAn ja ASML:n osakekurssit romahtamaan hetkeksi.
Samalla kun DeepSeek kasvatti suosiotaan räjähdysmäisesti, se julkaisi myös päivitetyn version multimodaalisesta suuresta Janus-mallista (Janus), Janus-Pro, joka perii edellisen sukupolven multimodaalisen ymmärtämisen ja sukupolven yhtenäisen arkkitehtuurin ja optimoi koulutusstrategian, skaalaa koulutusdatan ja mallin koon, mikä tuo vahvemman suorituskyvyn.

Janus-Pro
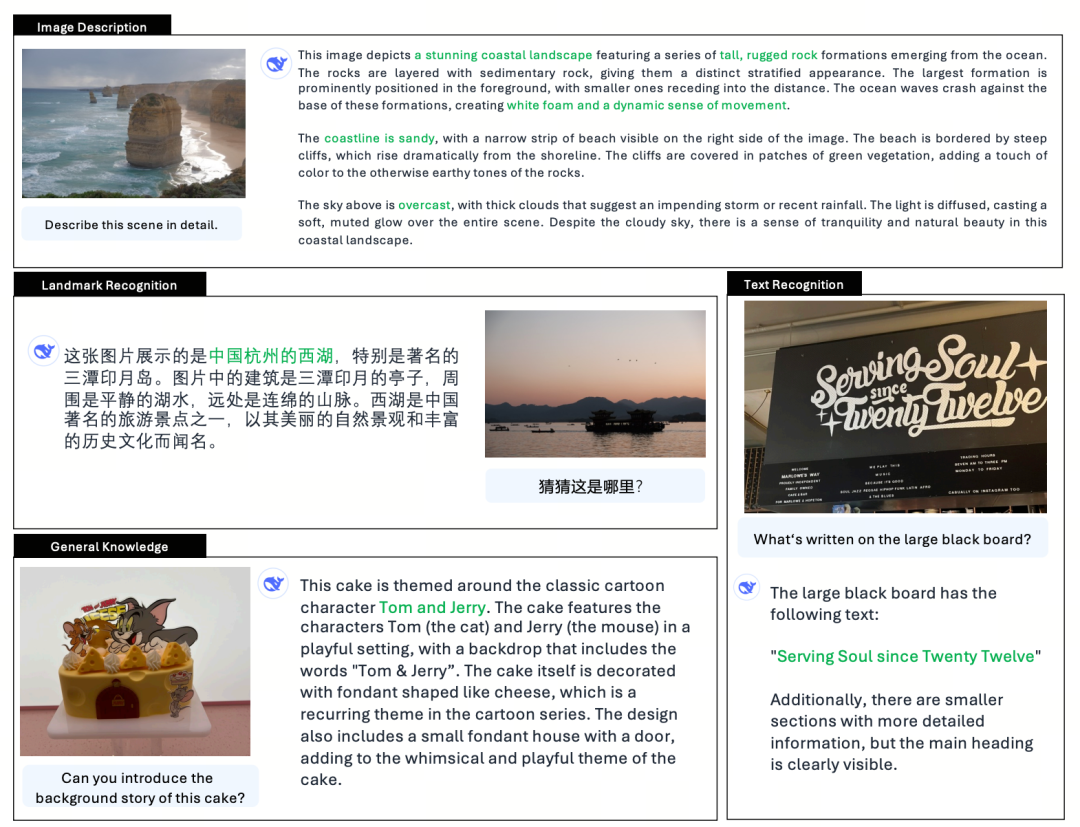
Janus-Pro on yhtenäinen multimodaalinen kielimalli (MLLM), joka voi samanaikaisesti käsitellä multimodaalisia ymmärtämis- ja tuottamistehtäviä, eli se voi ymmärtää kuvan sisällön ja myös tuottaa tekstiä.
Se irrottaa multimodaalisen ymmärtämisen ja tuottamisen visuaaliset kooderit toisistaan (eli kuvan ymmärtämisen syötteessä ja kuvan tuottamisen syötteessä ja tuotoksessa käytetään eri tokenisaattoreita) ja käsittelee ne käyttämällä yhtenäistä autoregressiivistä muunninta.
Edistynyt multimodaalinen ymmärtämis- ja tuottamismalli on parannettu versio aiemmasta Janus-mallista.
Roomalaisessa mytologiassa Janus (Janus) on kaksikasvoinen vartijajumala, joka symboloi ristiriitoja ja siirtymiä. Hänellä on kaksi kasvoa, mikä viittaa myös siihen, että Janus-malli pystyy ymmärtämään ja tuottamaan kuvia, mikä on erittäin tarkoituksenmukaista. Joten mitä tarkalleen ottaen PRO on päivittänyt?
Janus on 1.3B:n pienenä mallina enemmänkin esikatseluversio kuin virallinen versio. Siinä tutkitaan yhtenäistä multimodaalista ymmärtämistä ja tuottamista, mutta siinä on monia ongelmia, kuten epävakaat kuvantuotantotehosteet, suuret poikkeamat käyttäjän ohjeista ja riittämättömät yksityiskohdat.
Pro-versiossa optimoidaan harjoitusstrategia, kasvatetaan harjoitusdatamäärää ja tarjotaan suurempi malli (7B), josta valita, ja samalla tarjotaan 1B-malli.
Malliarkkitehtuuri
Jaus-Pro ja Janus ovat identtisiä malliarkkitehtuuriltaan. (Vain 1,3B! Janus yhdistää multimodaalisen ymmärtämisen ja tuottamisen).
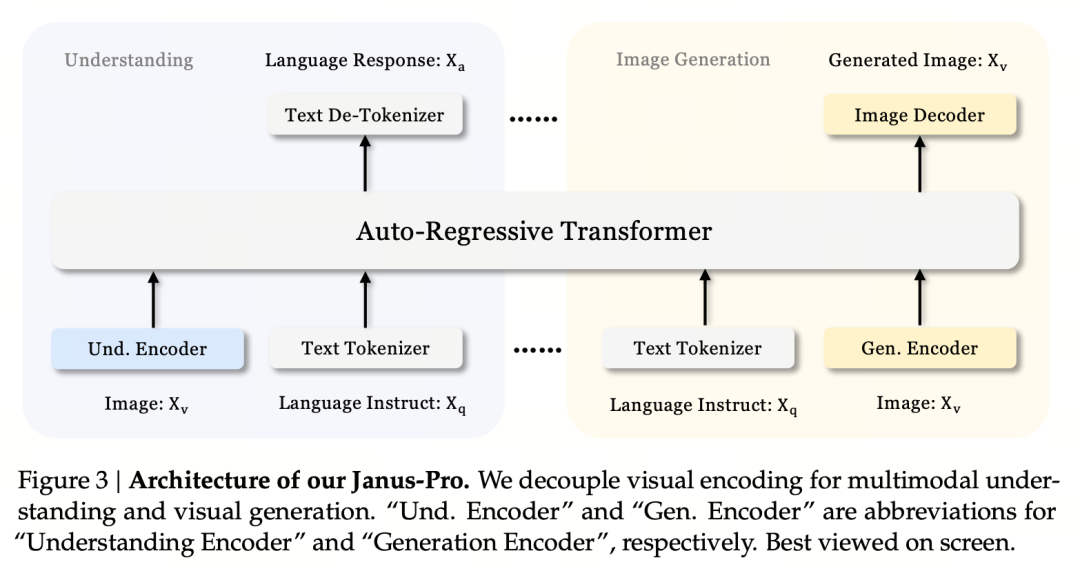
Keskeinen suunnitteluperiaate on visuaalisen koodauksen erottaminen toisistaan multimodaalisen ymmärtämisen ja tuottamisen tukemiseksi. Janus-Pro koodaa alkuperäisen kuvan ja tekstin erikseen, poimii korkea-ulotteiset piirteet ja käsittelee ne yhtenäisen autoregressiivisen muuntajan avulla.
Multimodaalinen kuvan ymmärtäminen käyttää SigLIP:tä kuvan ominaisuuksien koodaamiseen (sininen kooderi yllä olevassa kuvassa), ja generointitehtävässä käytetään VQ-tokenisaattoria kuvan diskretisointiin (keltainen kooderi yllä olevassa kuvassa). Lopuksi kaikki piirrejaksot syötetään LLM:ään käsiteltäväksi.
Koulutusstrategia
Koulutusstrategian osalta Janus-Pro on tehnyt lisää parannuksia. Januksen vanhassa versiossa käytettiin kolmivaiheista koulutusstrategiaa, jossa vaiheessa I koulutetaan syöttösovitin ja kuvanmuodostuspää kuvan ymmärtämistä ja kuvanmuodostusta varten, vaiheessa II suoritetaan yhtenäinen esikoulutus ja vaiheessa III hienosäädetään ymmärtävä kooderi tämän perusteella. (Januksen koulutusstrategia on esitetty alla olevassa kuvassa.)
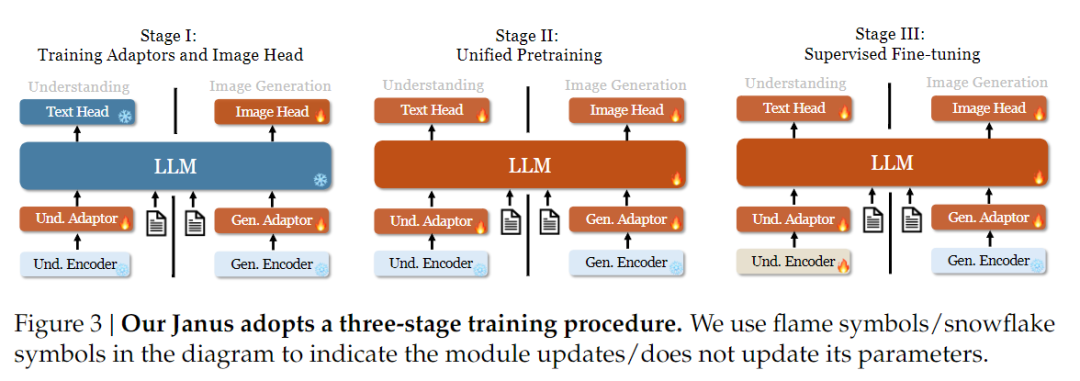
Tässä strategiassa käytetään kuitenkin PixArt-menetelmää tekstin ja kuvan välisen generoinnin harjoittelun jakamiseen vaiheessa II, mikä heikentää laskennallista tehokkuutta.
Tätä varten pidensimme vaiheen I harjoitteluaikaa ja lisäsimme harjoittelun ImageNet-tiedoilla, jotta malli voi tehokkaasti mallintaa pikseliriippuvuuksia kiinteillä LLM-parametreilla. Vaiheessa II hylkäsimme ImageNet-datan ja käytimme suoraan teksti-kuva-paridataa harjoitteluun, mikä parantaa harjoittelun tehokkuutta. Lisäksi säädimme vaiheessa III datan suhdetta (multimodaalinen:pelkkä teksti:visuaalinen-semanttinen graafidata 7:3:10:stä 5:1:4:ään), mikä parantaa multimodaalista ymmärrystä säilyttäen samalla visuaaliset generointikyvyt.
Koulutusdatan skaalaus
Janus-Pro myös skaalaa Januksen harjoitusdataa multimodaalisen ymmärtämisen ja visuaalisen tuottamisen osalta.
Multimodaalinen ymmärtäminen: Se sisältää noin 90 miljoonaa uutta näytettä, mukaan lukien kuvatekstitiedot (kuten YFCC) sekä taulukoiden, kaavioiden ja asiakirjojen ymmärtämistä koskevat tiedot (kuten Docmatix).
Vaiheen III valvotussa hienosäätövaiheessa otetaan lisäksi käyttöön MEME-ymmärrys, kiinalaista dialogia koskevat tiedot jne. mallin suorituskyvyn parantamiseksi monitehtäväprosessoinnissa ja vuoropuheluominaisuuksien parantamiseksi.
Visuaalinen sukupolvi: Aiemmat versiot käyttivät heikkolaatuisia ja kohinaisia todellisia tietoja, mikä vaikutti tekstin tuottamien kuvien vakauteen ja esteettisyyteen.
Janus-Pro sisältää noin 72 miljoonaa synteettistä esteettistä dataa, joten todellisen datan ja synteettisen datan suhde on 1:1. Kokeet ovat osoittaneet, että synteettinen data nopeuttaa mallin konvergoitumista ja parantaa merkittävästi tuotettujen kuvien vakautta ja esteettistä laatua.
Mallin skaalaus
Janus Pro laajentaa mallin kokoa 7B:hen, kun taas Januksen edellisessä versiossa käytettiin 1,5B DeepSeek-LLM:ää visuaalisen koodauksen irrottamisen tehokkuuden todentamiseksi. Kokeet osoittavat, että suurempi LLM nopeuttaa merkittävästi multimodaalisen ymmärtämisen ja visuaalisen generoinnin konvergenssia, mikä todentaa edelleen menetelmän vahvaa skaalautuvuutta.

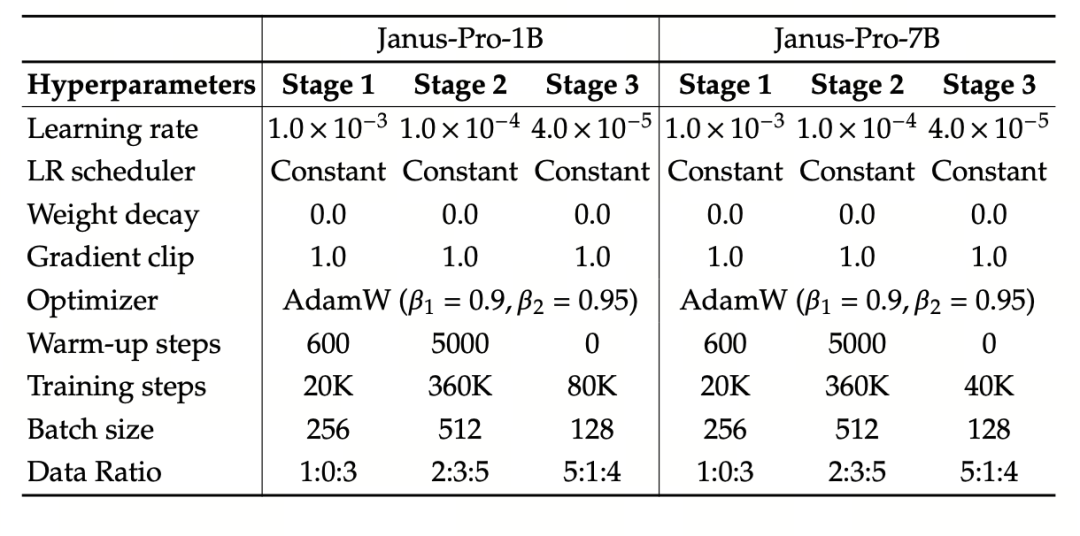
Kokeessa käytetään DeepSeek-LLM-mallia (1,5B ja 7B, tukee enintään 4096 sekvenssiä) peruskielimallina. Multimodaalisessa ymmärtämistehtävässä visuaalisena koodaajana käytetään SigLIP-Large-Patch16-384:ää, koodaajan sanakirjakoko on 16384, kuvan downsampling-kerroin on 16, ja sekä ymmärtämis- että generointisovittimet ovat kaksikerroksisia MLP-malleja.
Vaiheen II harjoittelussa käytetään 270K:n varhaista pysäytysstrategiaa, kaikki kuvat säädetään tasaisesti 384×384-resoluutioon, ja harjoittelun tehokkuuden parantamiseksi käytetään sekvenssipakkausta. Janus-Pro koulutetaan ja arvioidaan HAI-LLM:n avulla. Versiot 1,5B/7B koulutettiin 16/32 solmulla (8×Nvidia A100 40GB per solmu) 9/14 päivän ajan.
Mallin arviointi
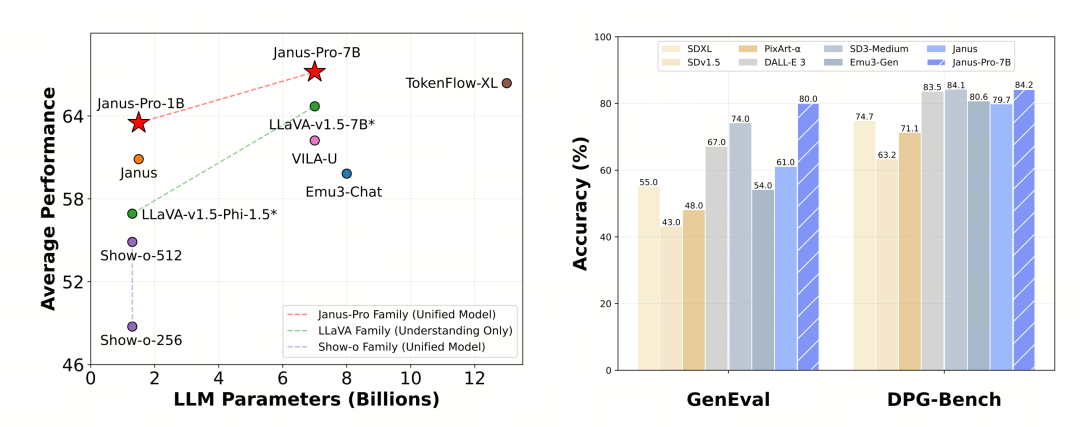
Janus-Pro:tä arvioitiin erikseen multimodaalisessa ymmärtämisessä ja tuottamisessa. Kaiken kaikkiaan ymmärtäminen saattaa olla hieman heikkoa, mutta sitä pidetään erinomaisena samankokoisten avoimen lähdekoodin mallien joukossa (arvatenkin sitä rajoittaa pitkälti kiinteä syöttötarkkuus ja OCR-ominaisuudet).
Janus-Pro-7B sai MMBench-vertailutestissä 79,2 pistettä, mikä on lähellä avoimen lähdekoodin ykkösmallien tasoa (InternVL2.5:n ja Qwen2-VL:n samankokoiset mallit ovat noin 82 pistettä). Se on kuitenkin hyvä parannus Januksen edelliseen sukupolveen verrattuna.
Kuvien luomisessa parannus edelliseen sukupolveen verrattuna on vieläkin merkittävämpi, ja sitä pidetään avoimen lähdekoodin mallien joukossa erinomaisena. Janus-Pro:n pisteet GenEval-vertailutestissä (0,80) ylittävät myös sellaiset mallit kuin DALL-E 3 (0,67) ja Stable Diffusion 3 Medium (0,74).