A tavaszi fesztivál előestéjén megjelent a DeepSeek-R1 modell. Tiszta RL architektúrájával a CoT nagyszerű újításaiból tanult, és felülmúlja a ChatGPT matematika, kódolás és logikus gondolkodás.
Emellett a nyílt forráskódú modellsúlyok, az alacsony képzési költségek és az olcsó API-árak miatt a DeepSeek az egész internetet bejárta, és egy időre még az NVIDIA és az ASML részvényeinek árfolyamát is mélyrepülésbe taszította.
A népszerűség robbanásszerű növekedése közben a DeepSeek kiadta a Janus (Janus) multimodális nagy modelljének frissített változatát is, az Janus-Pro-t, amely a multimodális megértés és generálás előző generációjának egységes architektúráját örökli, és optimalizálja a képzési stratégiát, a képzési adatok és a modell méretének skálázását, erősebb teljesítményt hozva.

Janus-Pro
Janus-Pro egy olyan egységes multimodális nyelvi modell (MLLM), amely egyszerre képes multimodális megértési és generálási feladatok feldolgozására, azaz képes egy kép tartalmának megértésére és szöveg generálására is.
A multimodális megértés és generálás vizuális kódolóit szétválasztja (azaz a képmegértés bemenetéhez és a képgenerálás bemenetéhez és kimenetéhez különböző tokenizátorokat használ), és ezeket egy egységes autoregresszív transzformátorral dolgozza fel.
A fejlett multimodális megértési és generálási modell a korábbi Janus modell továbbfejlesztett változata.
A római mitológiában Janus (Janus) egy kétarcú őrző isten, aki az ellentmondást és az átmenetet szimbolizálja. Két arca van, ami arra is utal, hogy a Janus-modell képes megérteni és képeket generálni, ami nagyon helyénvaló. Tehát pontosan mit is frissített a PRO?
A Janus, mint az 1.3B kis modellje, inkább egy előzetes verzió, mint egy hivatalos verzió. Az egységes multimodális megértést és generálást vizsgálja, de számos problémája van, például instabil képgenerálási hatások, nagy eltérések a felhasználói utasításoktól és nem megfelelő részletek.
A Pro verzió optimalizálja a képzési stratégiát, növeli a képzési adathalmazt, és nagyobb modell (7B) közül választhat, miközben 1B modellt biztosít.
Modell architektúra
Jaus-Pro és Janus modellarchitektúra szempontjából azonosak. (Csak 1,3B! Janus egyesíti a multimodális megértést és generálást)
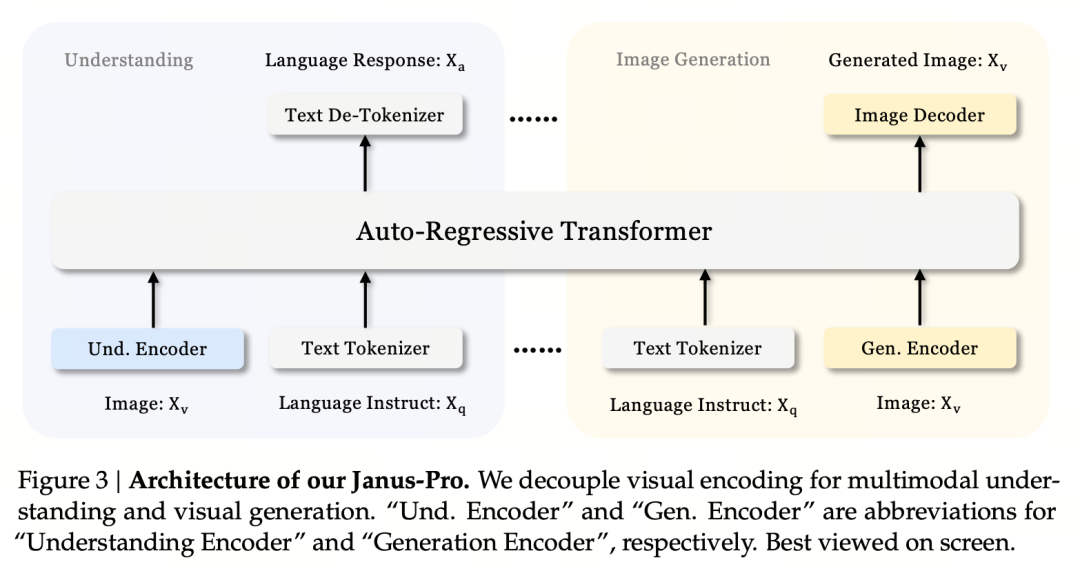
A tervezés alapelve a vizuális kódolás szétválasztása a multimodális megértés és generálás támogatása érdekében. Az Janus-Pro külön kódolja az eredeti kép/szöveg bemenetet, kivonja a nagydimenziós jellemzőket, és egy egységes autoregresszív transzformátoron keresztül dolgozza fel őket.
A multimodális képmegértés a SigLIP-et használja a képjellemzők kódolására (kék kódoló a fenti ábrán), a generálási feladat pedig a VQ tokenizálót használja a kép diszkretizálására (sárga kódoló a fenti ábrán). Végül az összes jellemzőszekvencia az LLM-be kerül feldolgozásra.
Képzési stratégia
A képzési stratégia tekintetében az Janus-Pro több fejlesztést hajtott végre. A Janus régi verziója háromlépcsős képzési stratégiát alkalmazott, amelyben az I. szakasz a bemeneti adaptert és a képgeneráló fejet képértésre és képgenerálásra képzi ki, a II. szakasz egységes előképzést végez, a III. szakasz pedig ennek alapján finomhangolja a megértő kódolót. (A Janus képzési stratégiája az alábbi ábrán látható).
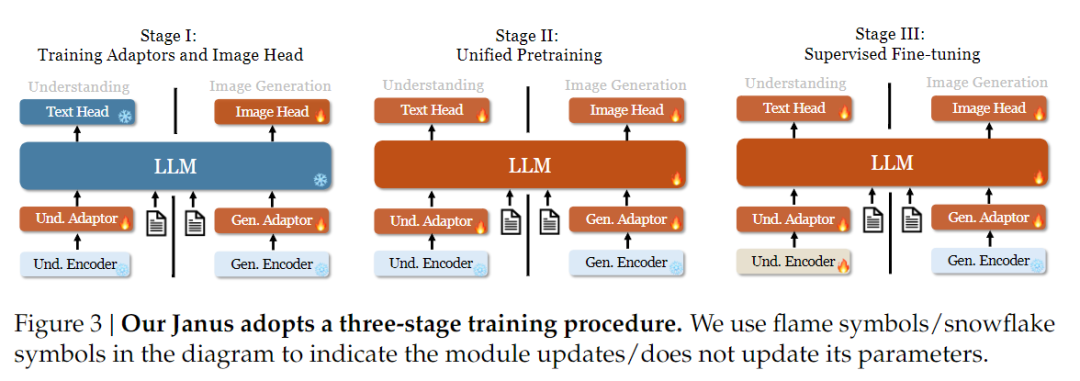
Ez a stratégia azonban a PixArt-módszert használja a szöveg-kép generálás képzésének megosztására a II. fázisban, ami alacsony számítási hatékonyságot eredményez.
Ennek érdekében meghosszabbítottuk az I. szakasz képzési idejét, és kiegészítettük az ImageNet-adatokkal történő képzéssel, hogy a modell hatékonyan modellezze a pixelfüggőségeket rögzített LLM-paraméterekkel. A II. szakaszban az ImageNet-adatokat elvetettük, és közvetlenül szöveg-képpár-adatokat használtunk a képzéshez, ami javítja a képzés hatékonyságát. Ezenkívül a III. fázisban módosítottuk az adatok arányát (multimodális:csak-szöveges:vizuális-szemantikus gráf adatok 7:3:10-ről 5:1:4-re), javítva a multimodális megértést, miközben fenntartottuk a vizuális generálási képességeket.
A képzési adatok skálázása
Az Janus-Pro a Janus képzési adatait is skálázza a multimodális megértés és a vizuális generálás szempontjából.
Multimodális megértés: A II. szakasz előképzési adatai a DeepSeek-VL2-n alapulnak, és körülbelül 90 millió új mintát tartalmaznak, köztük képfelirat-adatokat (például YFCC) és táblázat-, táblázat- és dokumentummegértési adatokat (például Docmatix).
A III. szakasz felügyelt finomhangolási szakasza további MEME-megértést, kínai párbeszédadatokat stb. vezet be, hogy javítsa a modell teljesítményét a többfeladat-feldolgozás és a párbeszédképesség terén.
Vizuális generálás: A korábbi verziók alacsony minőségű és nagy zajjal rendelkező valós adatokat használtak, ami befolyásolta a szöveggel generált képek stabilitását és esztétikáját.
Az Janus-Pro mintegy 72 millió szintetikus esztétikai adatot mutat be, így a valós adatok és a szintetikus adatok aránya 1:1-re nő. A kísérletek azt mutatták, hogy a szintetikus adatok felgyorsítják a modell konvergenciáját, és jelentősen javítják a generált képek stabilitását és esztétikai minőségét.
Modell méretezés
Az Janus Pro 7B-ra növeli a modell méretét, míg a Janus előző verziója 1,5B DeepSeek-LLM-et használt a vizuális kódolás szétválasztásának hatékonyságának ellenőrzésére. A kísérletek azt mutatják, hogy a nagyobb LLM jelentősen felgyorsítja a multimodális megértés és a vizuális generálás konvergenciáját, ami tovább igazolja a módszer erős skálázhatóságát.

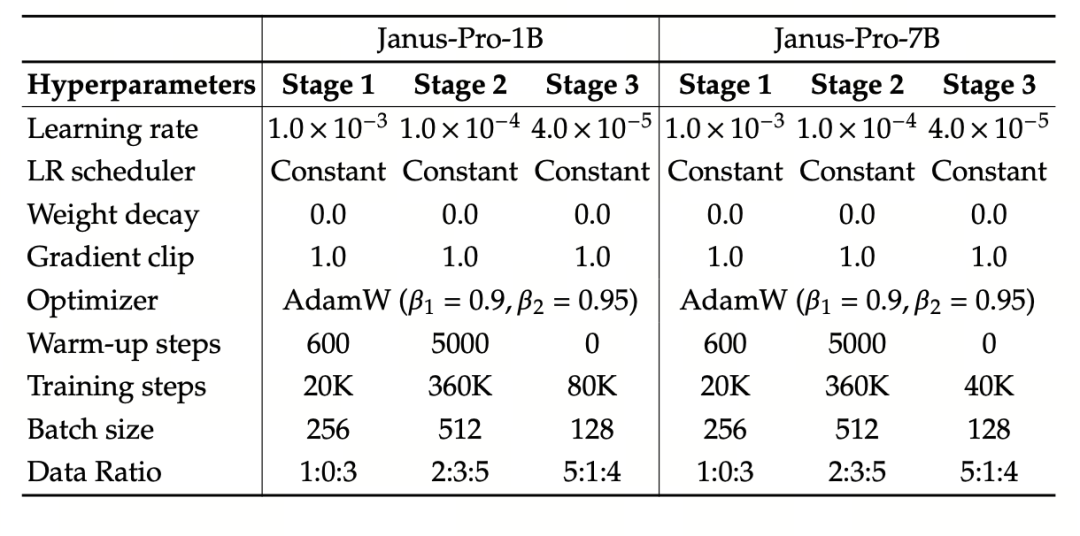
A kísérletben a DeepSeek-LLM (1,5B és 7B, maximum 4096 szekvencia támogatásával) alapnyelvi modellként szolgál. A multimodális megértési feladathoz a SigLIP-Large-Patch16-384 vizuális kódolót használjuk, a kódoló szótármérete 16384, a kép lemintavételezési többszöröse 16, és mind a megértő, mind a generáló adapter kétrétegű MLP.
A II. fázisú képzés 270K korai megállási stratégiát alkalmaz, minden képet egységesen 384×384-es felbontásra állítunk, és a képzés hatékonyságának javítása érdekében szekvenciacsomagolást használunk. Az Janus-Pro képzése és értékelése a HAI-LLM segítségével történik. Az 1,5B/7B verziókat 16/32 csomóponton (csomópontonként 8×Nvidia A100 40GB) 9/14 napon keresztül képeztük.
Modellértékelés
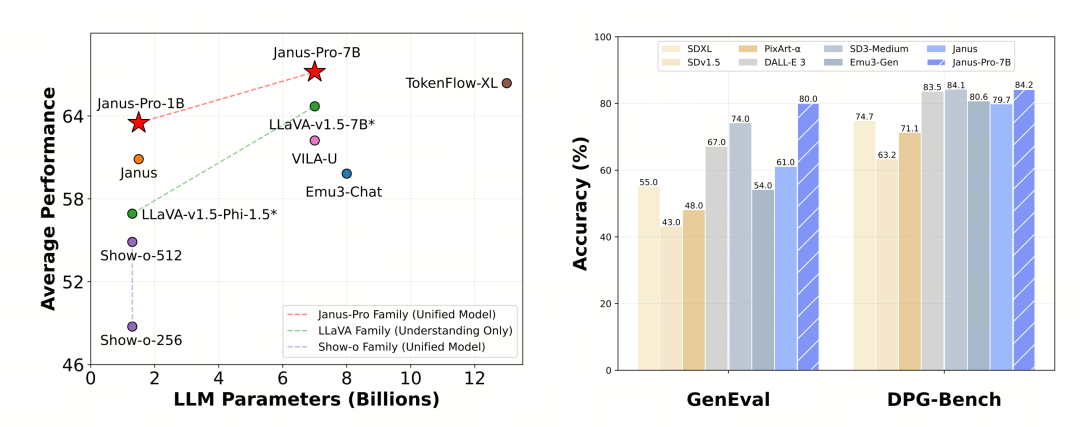
Az Janus-Pro-t külön értékelték a multimodális megértés és a generálás terén. Összességében a megértés talán kissé gyenge, de az azonos méretű nyílt forráskódú modellek között kiválónak tekinthető (gondolom, nagymértékben korlátozza a rögzített bemeneti felbontás és az OCR-képességek).
Az Janus-Pro-7B 79,2 pontot ért el az MMBench benchmark tesztben, ami közel van az első osztályú nyílt forráskódú modellek szintjéhez (az InternVL2.5 és a Qwen2-VL azonos mérete 82 pont körül van). A Janus előző generációjához képest azonban ez jó előrelépés.
A képgenerálás tekintetében még jelentősebb a javulás az előző generációhoz képest, és a nyílt forráskódú modellek között kiváló szintnek számít. Az Janus-Pro GenEval benchmark tesztben elért pontszáma (0,80) is meghaladja az olyan modelleket, mint a DALL-E 3 (0,67) és a Stable Diffusion 3 Medium (0,74).