În ajunul Festivalului Primăverii, a fost lansat modelul DeepSeek-R1. Cu arhitectura sa RL pură, acesta a învățat din marile inovații ale CoT și surclasează ChatGPT în matematică, cod și raționament logic.
În plus, ponderile modelelor sale open-source, costurile scăzute de formare și prețurile ieftine ale API au făcut din DeepSeek un hit pe internet, determinând chiar scăderea prețurilor acțiunilor NVIDIA și ASML pentru o perioadă.
În timp ce explodează în popularitate, DeepSeek a lansat, de asemenea, o versiune actualizată a modelului multimodal mare Janus (Janus), Janus-Pro, care moștenește arhitectura unificată a generației anterioare de înțelegere și generare multimodală și optimizează strategia de formare, scalând datele de formare și dimensiunea modelului, aducând performanțe mai puternice.

Janus-Pro
Janus-Pro este un model de limbaj multimodal unificat (MLLM) care poate procesa simultan sarcini de înțelegere multimodală și sarcini de generare, adică poate înțelege conținutul unei imagini și, de asemenea, poate genera text.
Acesta decuplează codificatoarele vizuale pentru înțelegerea și generarea multimodală (de exemplu, se utilizează tokenizere diferite pentru intrarea înțelegerii imaginii și pentru intrarea și ieșirea generării imaginii) și le procesează utilizând un transformator autoregresiv unificat.
Fiind un model avansat de înțelegere și generare multimodală, acesta este o versiune îmbunătățită a modelului Janus anterior.
În mitologia romană, Janus (Janus) este un zeu gardian cu două fețe care simbolizează contradicția și tranziția. El are două fețe, ceea ce sugerează, de asemenea, că modelul Janus poate înțelege și genera imagini, ceea ce este foarte potrivit. Deci, ce anume a actualizat PRO?
Janus, ca un model mic de 1.3B, este mai mult o versiune de previzualizare decât o versiune oficială. Acesta explorează înțelegerea și generarea multimodală unificată, dar are multe probleme, cum ar fi efecte instabile de generare a imaginilor, abateri mari de la instrucțiunile utilizatorului și detalii inadecvate.
Versiunea Pro optimizează strategia de formare, crește setul de date de formare și oferă un model mai mare (7B) din care se poate alege, oferind în același timp un model 1B.
Arhitectura modelului
Jaus-Pro și Janus sunt identice în ceea ce privește arhitectura modelului. (Doar 1,3 miliarde! Janus unifică înțelegerea și generarea multimodală)
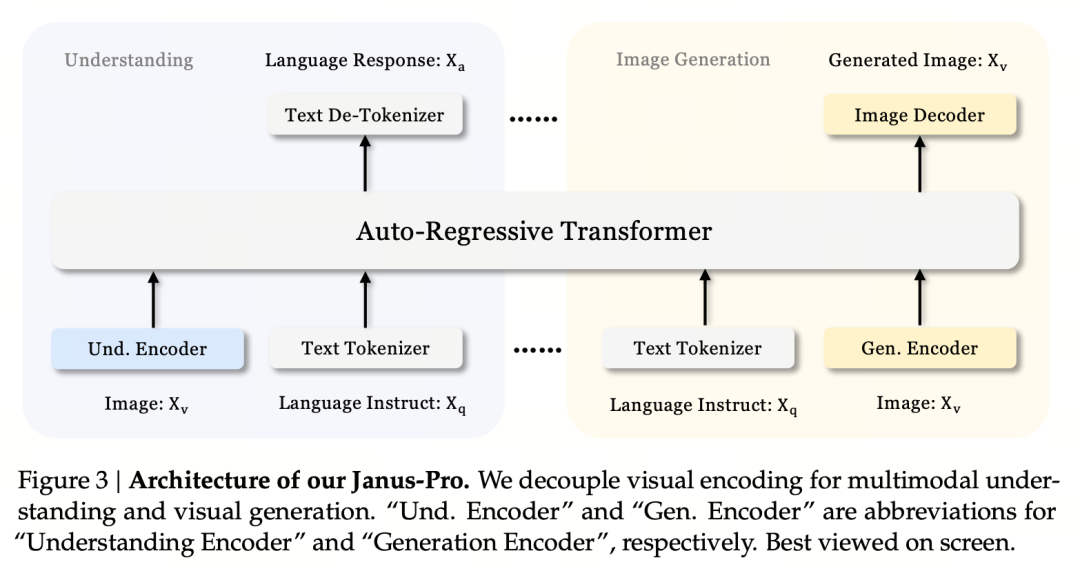
Principiul de proiectare de bază este de a decupla codificarea vizuală pentru a sprijini înțelegerea și generarea multimodală. Janus-Pro codifică separat imaginea/textul original de intrare, extrage caracteristici înalt-dimensionale și le procesează printr-un transformator autoregresiv unificat.
Înțelegerea imaginii multimodale utilizează SigLIP pentru a codifica caracteristicile imaginii (codificator albastru în figura de mai sus), iar sarcina de generare utilizează tokenizatorul VQ pentru a discretiza imaginea (codificator galben în figura de mai sus). În cele din urmă, toate secvențele de caracteristici sunt introduse în LLM pentru procesare
Strategia de formare
În ceea ce privește strategia de formare, Janus-Pro a adus mai multe îmbunătățiri. Versiunea veche a Janus folosea o strategie de formare în trei etape, în care etapa I pregătește adaptorul de intrare și capul de generare a imaginii pentru înțelegerea și generarea imaginii, etapa II efectuează o preformare unificată, iar etapa III ajustează codificatorul de înțelegere pe această bază. (Strategia de formare Janus este prezentată în figura de mai jos).
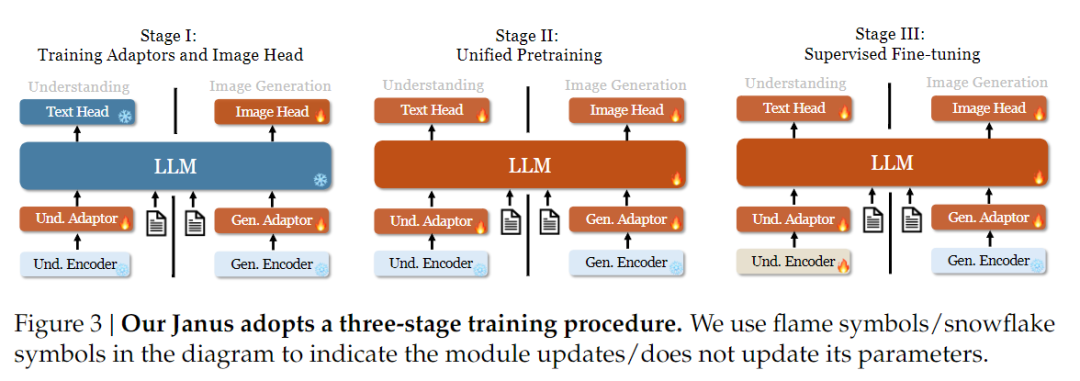
Cu toate acestea, această strategie utilizează metoda PixArt pentru a împărți formarea generării text-imagine în etapa II, ceea ce duce la o eficiență de calcul scăzută.
În acest scop, am prelungit timpul de formare din etapa I și am adăugat formarea cu date ImageNet, astfel încât modelul să poată modela eficient dependențele pixelilor cu parametri LLM stabili. În etapa a II-a, am eliminat datele ImageNet și am utilizat direct datele perechii text-imagine pentru formare, ceea ce îmbunătățește eficiența formării. În plus, am ajustat raportul de date în etapa III (date multimodale:doar text:graf vizual-semantic de la 7:3:10 la 5:1:4), îmbunătățind înțelegerea multimodală și menținând în același timp capacitățile de generare vizuală.
Scalarea datelor de formare
Janus-Pro scalează, de asemenea, datele de instruire ale Janus în ceea ce privește înțelegerea multimodală și generarea vizuală.
Înțelegerea multimodală: Datele de preantrenare din etapa a II-a se bazează pe DeepSeek-VL2 și includ aproximativ 90 de milioane de eșantioane noi, inclusiv date privind legendele imaginilor (cum ar fi YFCC) și date privind înțelegerea tabelelor, graficelor și documentelor (cum ar fi Docmatix).
Etapa III de reglaj fin supravegheat introduce în continuare înțelegerea MEME, date de dialog chinezesc etc., pentru a îmbunătăți performanța modelului în ceea ce privește procesarea multitask și capacitățile de dialog.
Generarea vizuală: Versiunile anterioare foloseau date reale de calitate scăzută și zgomot ridicat, care afectau stabilitatea și estetica imaginilor generate de text.
Janus-Pro introduce aproximativ 72 de milioane de date estetice sintetice, aducând raportul dintre datele reale și datele sintetice la 1:1. Experimentele au arătat că datele sintetice accelerează convergența modelului și îmbunătățesc semnificativ stabilitatea și calitatea estetică a imaginilor generate.
Scalarea modelului
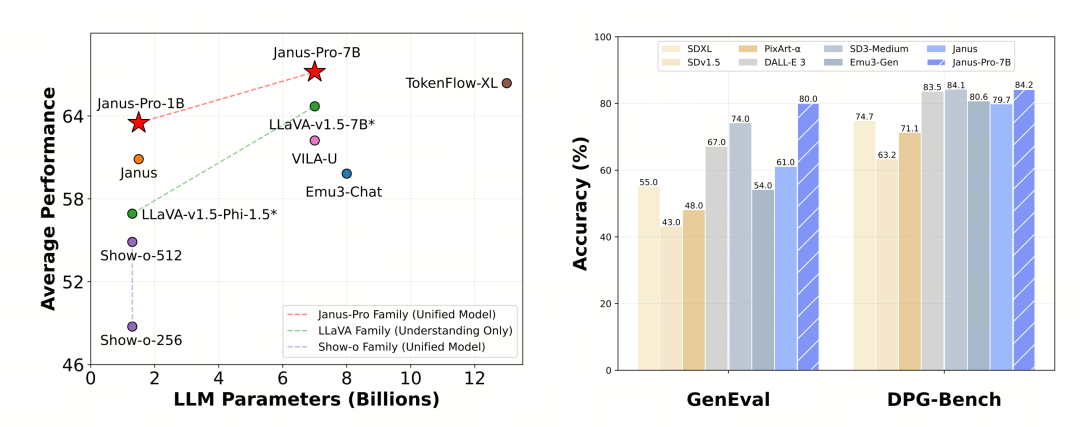
Janus Pro extinde dimensiunea modelului la 7B, în timp ce versiunea anterioară a lui Janus a utilizat 1.5B DeepSeek-LLM pentru a verifica eficacitatea decuplării codificării vizuale. Experimentele arată că un LLM mai mare accelerează semnificativ convergența înțelegerii multimodale și a generării vizuale, verificând în continuare scalabilitatea puternică a metodei.

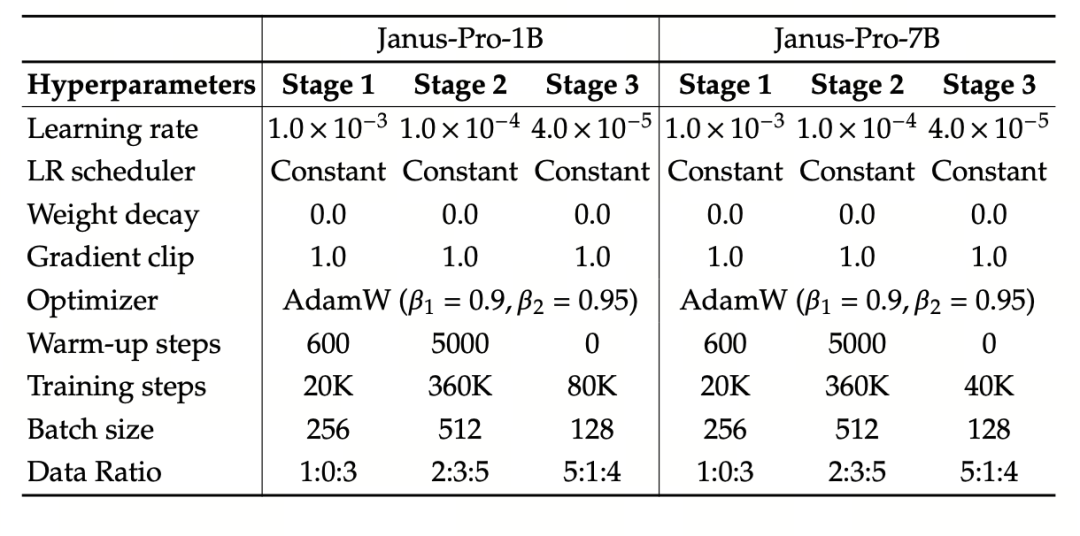
Experimentul utilizează DeepSeek-LLM (1.5B și 7B, suportând o secvență maximă de 4096) ca model lingvistic de bază. Pentru sarcina de înțelegere multimodală, SigLIP-Large-Patch16-384 este utilizat ca codificator vizual, dimensiunea dicționarului codificatorului este 16384, multiplul de downsampling al imaginii este 16, iar adaptoarele de înțelegere și de generare sunt MLP cu două straturi.
Etapa II de formare utilizează o strategie de oprire timpurie 270K, toate imaginile sunt ajustate uniform la o rezoluție de 384 × 384 și se utilizează ambalarea secvențelor pentru a îmbunătăți eficiența formării . Janus-Pro este antrenat și evaluat utilizând HAI-LLM. Versiunile 1.5B/7B au fost antrenate pe 16/32 de noduri (8×Nvidia A100 40GB per nod) timp de 9/14 zile, respectiv.
Evaluarea modelului
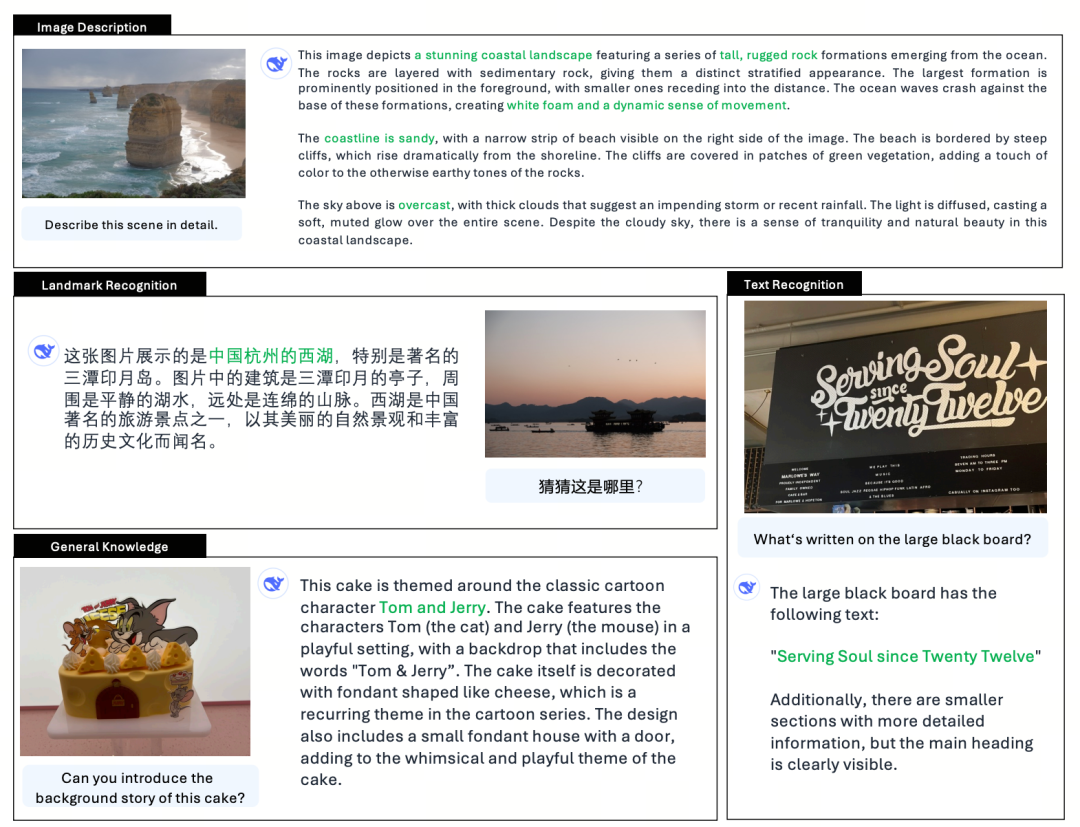
Janus-Pro a fost evaluat separat în ceea ce privește înțelegerea și generarea multimodală. În general, înțelegerea poate fi ușor slabă, dar este considerată excelentă în rândul modelelor open source de aceeași dimensiune (se presupune că este în mare măsură limitată de rezoluția fixă de intrare și de capacitățile OCR).
Janus-Pro-7B a obținut 79,2 puncte în testul de referință MMBench, care este aproape de nivelul modelelor open source de prim rang (aceeași dimensiune a InternVL2.5 și Qwen2-VL este de aproximativ 82 de puncte). Cu toate acestea, este o îmbunătățire bună față de generația anterioară de Janus.
În ceea ce privește generarea de imagini, îmbunătățirea față de generația anterioară este și mai semnificativă și este considerată a fi un nivel excelent printre modelele open source. Scorul lui Janus-Pro în testul de referință GenEval (0,80) depășește, de asemenea, modele precum DALL-E 3 (0,67) și Stable Diffusion 3 Medium (0,74).