Na véspera do Festival da Primavera, o modelo DeepSeek-R1 foi lançado. Com sua arquitetura RL pura, ele aprendeu com as grandes inovações da CoT e supera ChatGPT em matemática, código e raciocínio lógico.
Além disso, seus pesos de modelo de código aberto, baixos custos de treinamento e preços baratos de API tornaram o DeepSeek um sucesso na Internet, fazendo até mesmo com que os preços das ações da NVIDIA e da ASML caíssem por um tempo.
Enquanto explodia em popularidade, a DeepSeek também lançou uma versão atualizada do modelo multimodal de grande porte Janus (Janus), Janus-Pro, que herda a arquitetura unificada da geração anterior de compreensão e geração multimodal e otimiza a estratégia de treinamento, dimensionando os dados de treinamento e o tamanho do modelo, proporcionando um desempenho mais forte.

Janus-Pro
Janus-Pro é um modelo de linguagem multimodal unificado (MLLM) que pode processar simultaneamente tarefas de compreensão multimodal e tarefas de geração, ou seja, ele pode compreender o conteúdo de uma imagem e também gerar texto.
Ele desacopla os codificadores visuais para compreensão e geração multimodal (ou seja, diferentes tokenizadores são usados para a entrada da compreensão da imagem e a entrada e saída da geração da imagem) e os processa usando um transformador autorregressivo unificado.
Como um modelo avançado de geração e compreensão multimodal, ele é uma versão atualizada do modelo Janus anterior.
Na mitologia romana, Jano (Janus) é um deus guardião de duas faces que simboliza a contradição e a transição. Ele tem duas faces, o que também sugere que o modelo Janus pode entender e gerar imagens, o que é muito apropriado. Então, o que exatamente o PRO atualizou?
O Janus, como um modelo pequeno de 1.3B, é mais uma versão prévia do que uma versão oficial. Ele explora a compreensão e a geração multimodais unificadas, mas tem muitos problemas, como efeitos instáveis de geração de imagens, grandes desvios das instruções do usuário e detalhes inadequados.
A versão Pro otimiza a estratégia de treinamento, aumenta o conjunto de dados de treinamento e fornece um modelo maior (7B) para escolha, além de fornecer um modelo 1B.
Arquitetura do modelo
Jaus-Pro e Janus são idênticos em termos de arquitetura de modelo. (Apenas 1,3 bilhão! Janus unifica a compreensão e a geração multimodais)
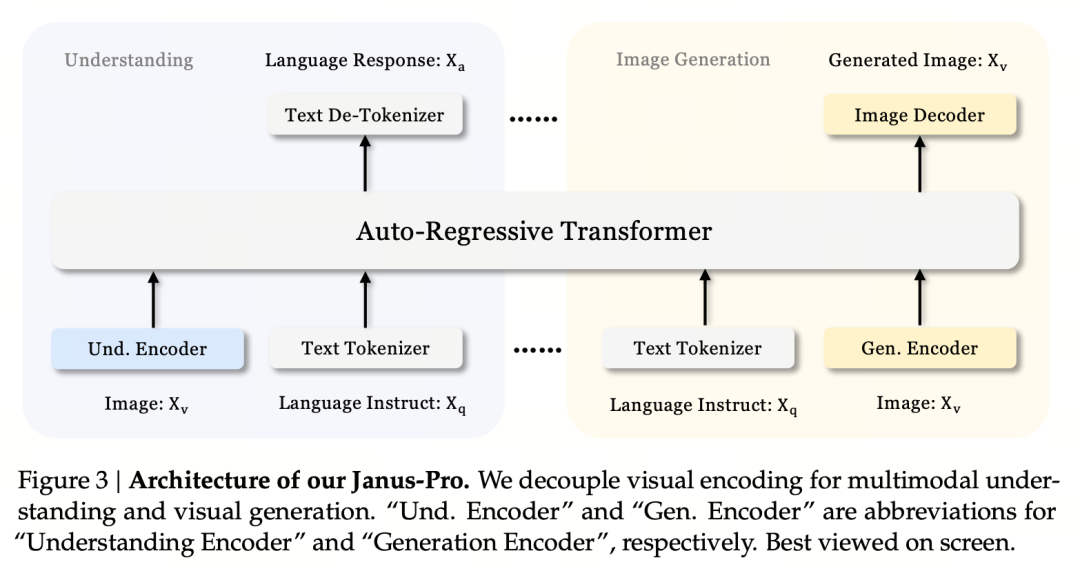
O princípio central do projeto é dissociar a codificação visual para dar suporte à compreensão e à geração multimodais. O Janus-Pro codifica a imagem original/entrada de texto separadamente, extrai recursos de alta dimensão e os processa por meio de um transformador autorregressivo unificado.
A compreensão da imagem multimodal usa o SigLIP para codificar os recursos da imagem (codificador azul na figura acima), e a tarefa de geração usa o tokenizador VQ para discretizar a imagem (codificador amarelo na figura acima). Por fim, todas as sequências de recursos são inseridas no LLM para processamento
Estratégia de treinamento
Em termos de estratégia de treinamento, o Janus-Pro fez mais melhorias. A versão antiga do Janus usava uma estratégia de treinamento de três estágios, na qual o Estágio I treina o adaptador de entrada e o cabeçote de geração de imagens para compreensão e geração de imagens, o Estágio II executa um pré-treinamento unificado e o Estágio III ajusta o codificador de compreensão com base nisso. (A estratégia de treinamento da Janus é mostrada na figura abaixo).
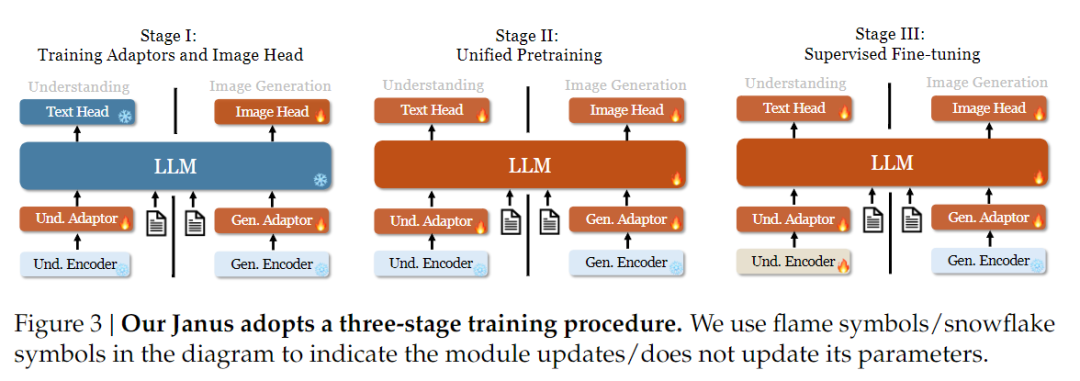
No entanto, essa estratégia usa o método PixArt para dividir o treinamento da geração de texto para imagem no Estágio II, o que resulta em baixa eficiência computacional.
Para isso, estendemos o tempo de treinamento do Estágio I e adicionamos o treinamento com dados do ImageNet, de modo que o modelo possa modelar efetivamente as dependências de pixel com parâmetros LLM fixos. No Estágio II, descartamos os dados do ImageNet e usamos diretamente os dados do par texto-imagem para treinar, o que melhora a eficiência do treinamento. Além disso, ajustamos a proporção de dados no Estágio III (multimodal: somente texto: dados de gráfico visual-semântico de 7:3:10 para 5:1:4), melhorando a compreensão multimodal e mantendo os recursos de geração visual.
Dimensionamento de dados de treinamento
O Janus-Pro também dimensiona os dados de treinamento do Janus em termos de compreensão multimodal e geração visual.
Compreensão multimodal: Os dados de pré-treinamento do Estágio II são baseados no DeepSeek-VL2 e incluem cerca de 90 milhões de novas amostras, incluindo dados de legenda de imagem (como YFCC) e dados de compreensão de tabelas, gráficos e documentos (como Docmatix).
O estágio de ajuste fino supervisionado do Estágio III introduz ainda a compreensão do MEME, dados de diálogos chineses, etc., para melhorar o desempenho do modelo no processamento multitarefa e nos recursos de diálogo.
Geração visual: As versões anteriores usavam dados reais de baixa qualidade e alto ruído, o que afetava a estabilidade e a estética das imagens geradas por texto.
O Janus-Pro introduz cerca de 72 milhões de dados estéticos sintéticos, elevando a proporção de dados reais para dados sintéticos para 1:1. Os experimentos mostraram que os dados sintéticos aceleram a convergência do modelo e melhoram significativamente a estabilidade e a qualidade estética das imagens geradas.
Dimensionamento do modelo
O Janus Pro amplia o tamanho do modelo para 7B, enquanto a versão anterior do Janus usava o DeepSeek-LLM de 1,5B para verificar a eficácia da dissociação da codificação visual. Os experimentos mostram que um LLM maior acelera significativamente a convergência da compreensão multimodal e da geração visual, verificando ainda mais a forte escalabilidade do método.

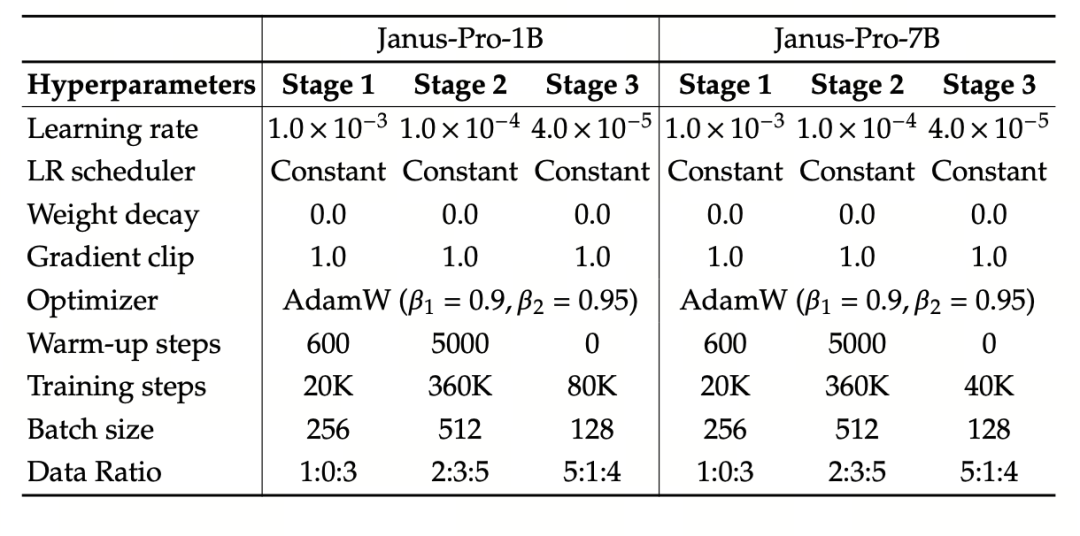
O experimento usa o DeepSeek-LLM (1,5B e 7B, suportando uma sequência máxima de 4096) como modelo básico de linguagem. Para a tarefa de compreensão multimodal, SigLIP-Large-Patch16-384 é usado como codificador visual, o tamanho do dicionário do codificador é 16384, o múltiplo de redução da amostragem da imagem é 16 e os adaptadores de compreensão e geração são MLPs de duas camadas.
O treinamento do estágio II usa uma estratégia de parada antecipada de 270K, todas as imagens são ajustadas uniformemente para uma resolução de 384×384 e o empacotamento da sequência é usado para melhorar a eficiência do treinamento. O Janus-Pro é treinado e avaliado usando HAI-LLM. As versões 1.5B/7B foram treinadas em 16/32 nós (8×Nvidia A100 40GB por nó) por 9/14 dias, respectivamente.
Avaliação do modelo
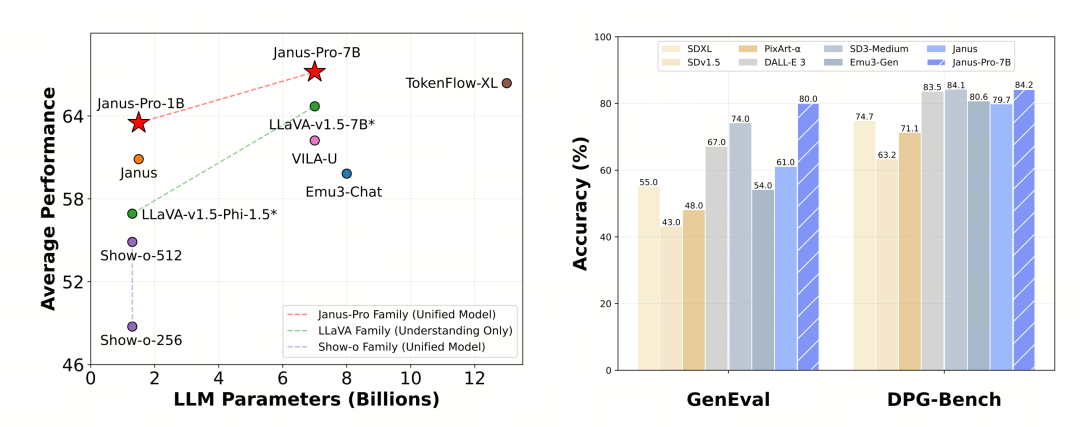
O Janus-Pro foi avaliado separadamente na compreensão e geração multimodal. De modo geral, a compreensão pode ser um pouco fraca, mas é considerada excelente entre os modelos de código aberto do mesmo tamanho (suponha que ela seja amplamente limitada pela resolução de entrada fixa e pelos recursos de OCR).
O Janus-Pro-7B obteve 79,2 pontos no teste de benchmark MMBench, que está próximo do nível dos modelos de código aberto de primeira linha (o mesmo tamanho do InternVL2.5 e do Qwen2-VL é de cerca de 82 pontos). No entanto, é uma boa melhoria em relação à geração anterior do Janus.
Em termos de geração de imagens, a melhoria em relação à geração anterior é ainda mais significativa e é considerada um nível excelente entre os modelos de código aberto. A pontuação do Janus-Pro no teste de benchmark GenEval (0,80) também supera modelos como o DALL-E 3 (0,67) e o Stable Diffusion 3 Medium (0,74).