A DeepSeek frissítette weboldalát.
Szilveszter kora estéjén a DeepSeek hirtelen bejelentette a GitHubon, hogy a Janus projekttér megnyitotta az Janus-Pro modell és a technikai jelentés forrását.
Először is, emeljünk ki néhány kulcsfontosságú pontot:
- A Janus-Pro modell ezúttal egy multimodális modell, amely egyszerre képes multimodális megértési és képalkotási feladatokat ellátni. Összesen két paraméteres változata van, Janus-Pro-1B és Janus-Pro-7B.
- Az Janus-Pro alapvető újítása a következők szétválasztása multimodális megértés és generálás, két különböző feladat. Ez lehetővé teszi e két feladat hatékony elvégzését ugyanabban a modellben..
- Az Janus-Pro összhangban van a DeepSeek által tavaly októberben közzétett Janus modell architektúrájával, de akkoriban a Janus nem rendelkezett nagy volumennel. Dr. Charles, egy algoritmus-szakértő a látás területén elmondta, hogy a korábbi Janus "átlagos" volt, és "nem volt olyan jó, mint a DeepSeek nyelvi modellje".

Az iparág nehéz problémáját hivatott megoldani: a multimodális megértés és a képalkotás egyensúlyban tartása.
A DeepSeek hivatalos bemutatása szerint, Janus-Pro nem csak a képek megértésére, a képekben lévő szöveg kivonására és megértésére képes, hanem egyúttal képeket is generál.
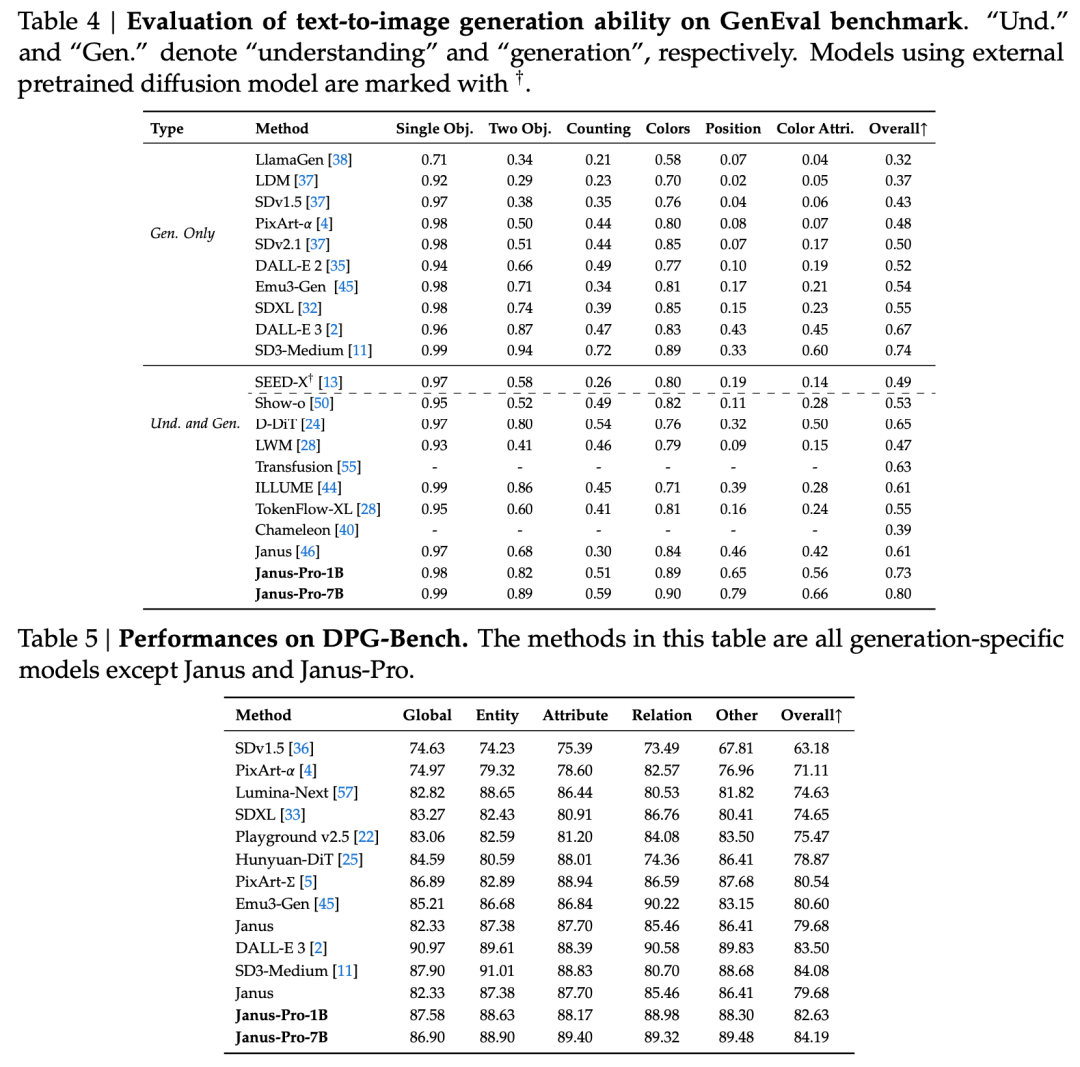
A műszaki jelentés megemlíti, hogy más, azonos típusú és nagyságrendű modellekkel összehasonlítva az Janus-Pro-7B eredményei a GenEval és a DPG-Bench tesztkészleteken a következők voltak meghaladja más modellek, például az SD3-Medium és a DALL-E 3 modellét.
A tisztviselő példákat is hoz 👇:
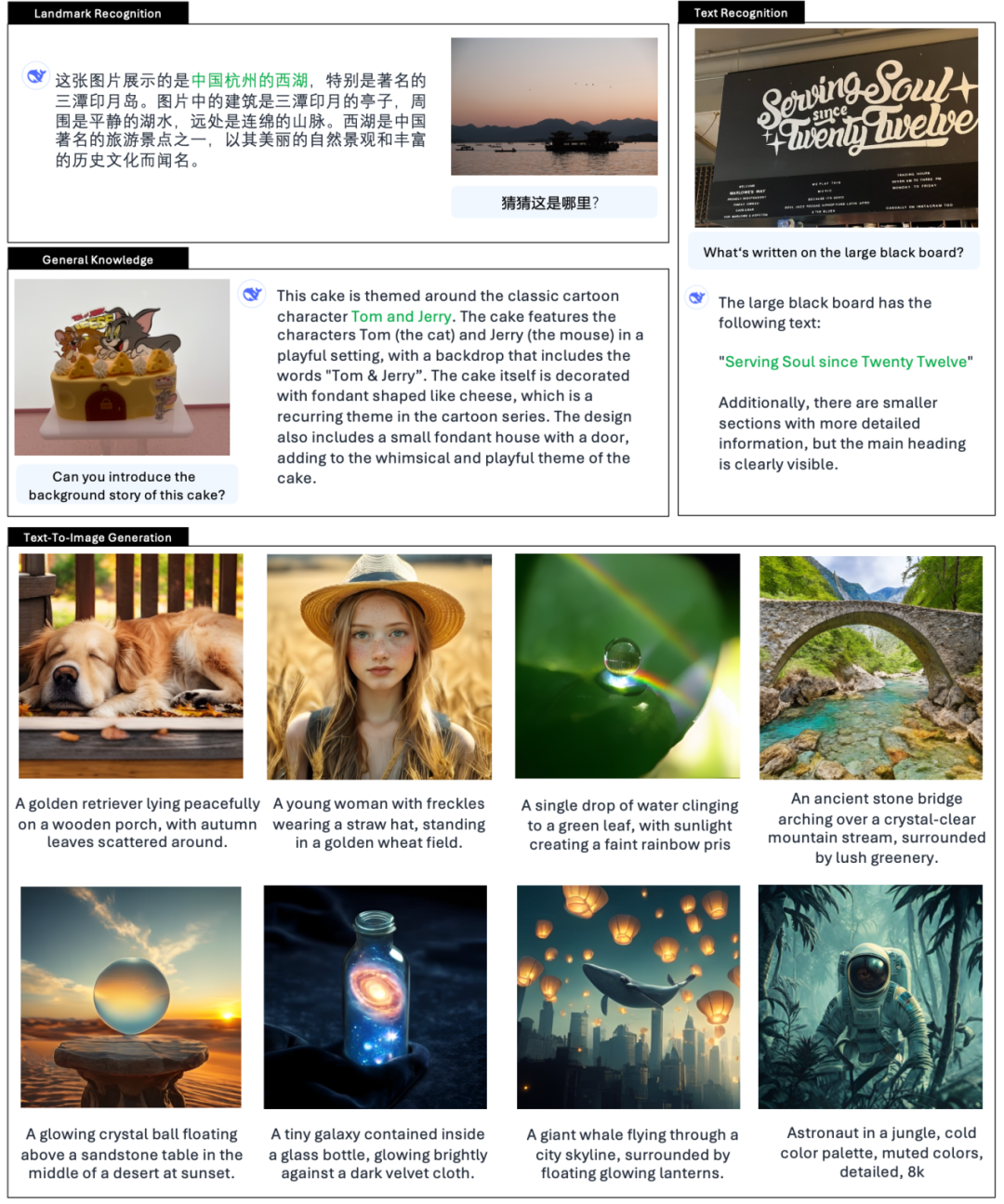
Az X-en is sok netező próbálja ki az új funkciókat.

De vannak alkalmi összeomlások is.
A következő technikai dokumentumokkal való konzultációval DeepSeek, kiderült, hogy az Janus Pro egy három hónapja megjelent Januson alapuló optimalizálás.
E modellsorozat alapvető újítása a következő a vizuális megértési feladatok szétválasztása a vizuális generálási feladatoktól, hogy a két feladat hatása kiegyensúlyozható legyen.
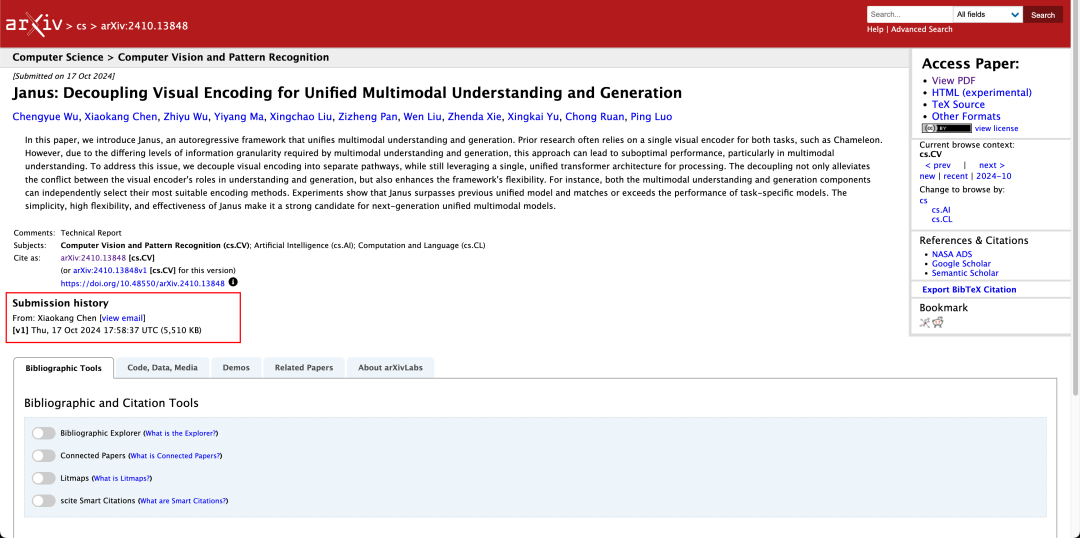
Nem ritka, hogy egy modell egyszerre végez multimodális megértést és generálást. A D-DiT és a TokenFlow-XL ebben a tesztkészletben egyaránt rendelkezik ezzel a képességgel.
Janusra azonban az a jellemző, hogy a feldolgozás szétválasztásával a multimodális megértésre és generálásra képes modell kiegyensúlyozza a két feladat hatékonyságát.
A két feladat hatékonyságának kiegyensúlyozása nehéz probléma az iparágban. Korábban úgy gondolták, hogy ugyanazt a kódolót használják a multimodális megértés és generálás megvalósításához, amennyire csak lehetséges.
E megközelítés előnye az egyszerű felépítés, a redundáns telepítés elkerülése, valamint a szövegmodellekkel való összehangolás (amelyek szintén ugyanazokat a módszereket használják a szöveggenerálás és a szövegértés eléréséhez). Egy másik érv az, hogy több képesség ilyen fúziója bizonyos fokú emergenciához vezethet.
Valójában azonban a generálás és a megértés egyesítése után a két feladat konfliktusba kerül - a képmegértés megköveteli, hogy a modell nagy dimenziókban absztraháljon, és kivonja a kép alapvető szemantikáját, ami a makroszkopikus irányba hajlik. A képgenerálás ezzel szemben a helyi részletek pixelszintű kifejezésére és generálására összpontosít.
Az iparág szokásos gyakorlata az, hogy a képalkotási képességeket helyezik előtérbe. Ez olyan multimodális modelleket eredményez, amelyek jobb minőségű képeket tudnak generálni, de a képmegértés eredményei gyakran közepesek.
A Janus szétválasztott architektúrája és az Janus-Pro optimalizált képzési stratégiája
A Janus szétválasztott architektúrája lehetővé teszi, hogy a modell önállóan egyensúlyozzon a megértés és a generálás feladatai között.
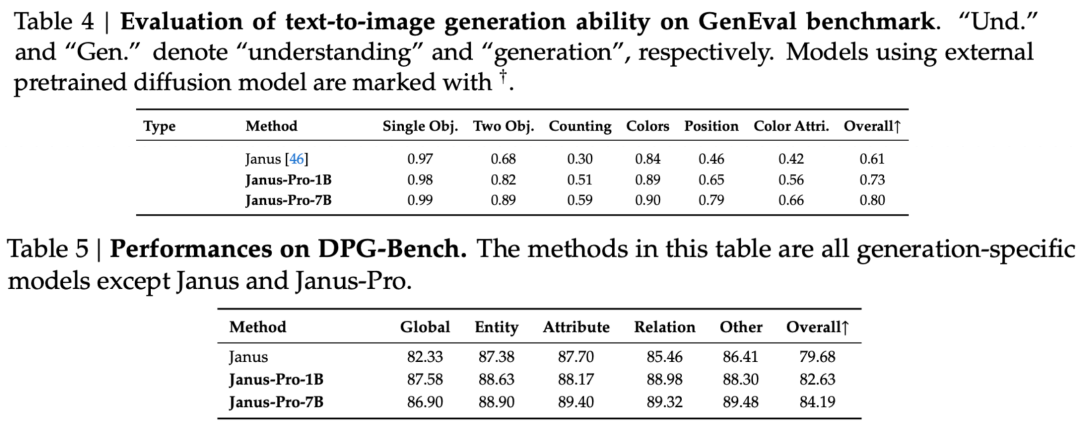
A hivatalos technikai jelentésben szereplő eredmények szerint az Janus-Pro-7B akár multimodális megértésről, akár képgenerálásról van szó, több tesztkészleten is jól teljesít.

A multimodális megértés érdekében, Az Janus-Pro-7B a hét értékelési adathalmazból négyben az első, a maradék háromban pedig a második helyet szerezte meg, kissé lemaradva a legjobban rangsorolt modell mögött.
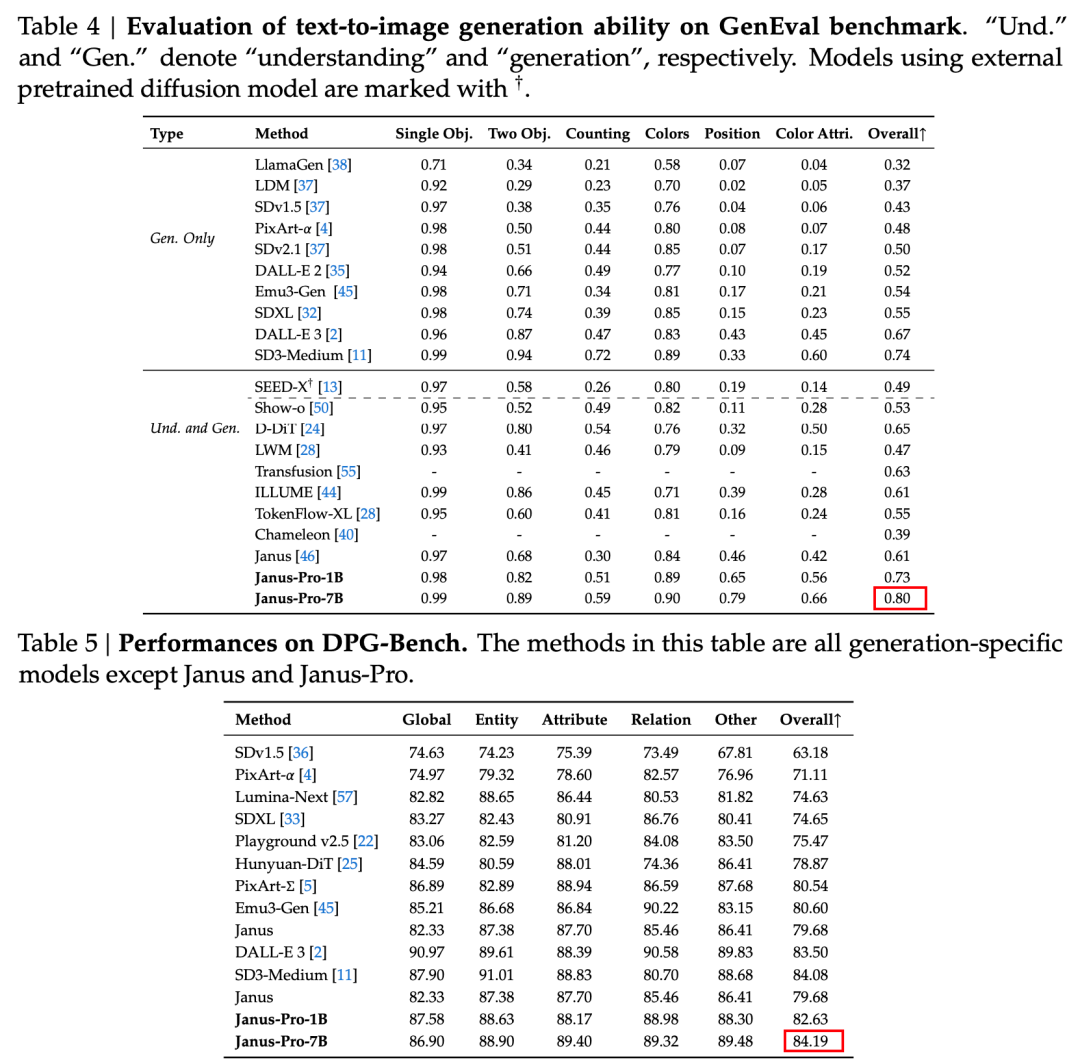
Képgeneráláshoz, Az Janus-Pro-7B mind a GenEval, mind a DPG-Bench értékelő adathalmazokon az első helyet szerezte meg az összesített pontszámban.
Ez a többfeladatos hatás elsősorban annak köszönhető, hogy a Janus sorozat két vizuális kódolót használ különböző feladatokhoz:
- A kódoló megértése: a képek szemantikai jellemzőinek kinyerésére használják képmegértési feladatokhoz (például képi kérdések és válaszok, vizuális osztályozás stb.).
- Generatív kódoló: a képeket diszkrét reprezentációvá alakítja (pl. VQ kódoló segítségével) a szöveg-kép generálási feladatokhoz.
Ezzel az architektúrával, a modell képes az egyes kódolók teljesítményét egymástól függetlenül optimalizálni, így a multimodális megértési és generálási feladatok mindegyike a legjobb teljesítményt érheti el.
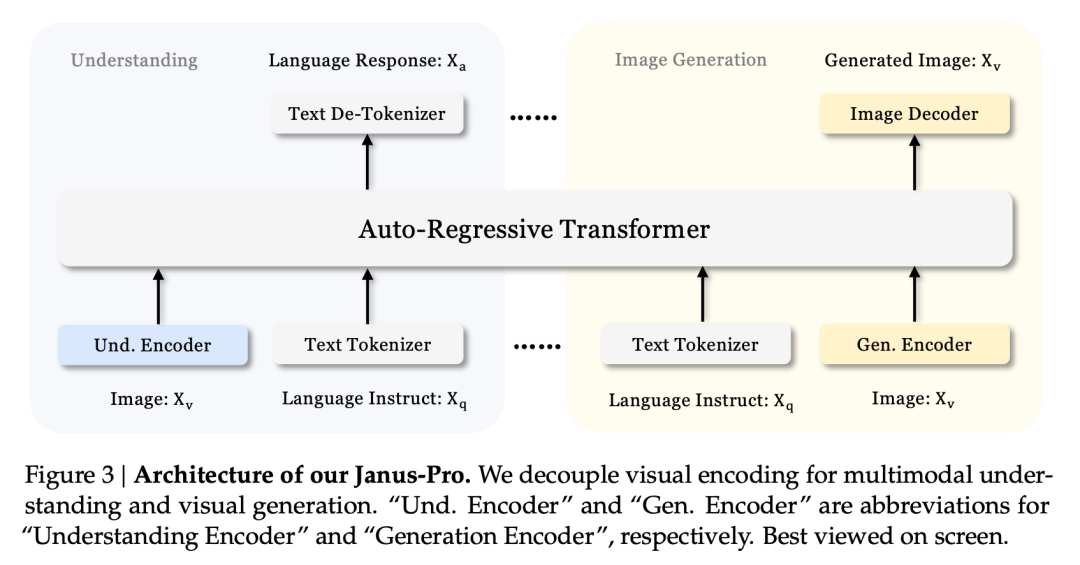
Ez a szétválasztott architektúra közös az Janus-Pro és a Janus esetében. Milyen iterációkon ment keresztül az Janus-Pro az elmúlt hónapokban?
Amint az értékelőkészlet eredményei alapján látható, az Janus-Pro-1B jelenlegi kiadása a különböző értékelőkészletek pontszámai tekintetében körülbelül 10% és 20% közötti javulást mutat a korábbi Janushoz képest. Az Janus-Pro-7B a paraméterek számának kibővítése után a legnagyobb, mintegy 45% javulást mutatja a Janushoz képest.

A képzés részleteit illetően a műszaki jelentés szerint az Janus-Pro jelenlegi kiadása a korábbi Janus modellhez képest megtartja az alapvető, szétválasztott architektúra kialakítását, és emellett a következő elemeket is továbbfejlesztette. paraméterméret, képzési stratégia és képzési adatok.
Először nézzük meg a paramétereket.
A Janus első verziója csak 1,3B paraméterekkel rendelkezett, a Pro jelenlegi verziója pedig 1B és 7B paraméterekkel rendelkező modelleket tartalmaz.
Ez a két méret a Janus architektúra skálázhatóságát tükrözi. Az 1B modellt, amely a legkönnyebb, külső felhasználók már használták a böngészőben történő futtatásra a WebGPU segítségével.
Van még a képzési stratégia.
A Janus képzési fázisok felosztásával összhangban az Janus Pro összesen három képzési fázist tartalmaz, és a dokumentum ezeket közvetlenül I., II. és III. szakaszra osztja.
Az Janus-Pro megtartotta az egyes fázisok alapvető képzési elképzeléseit és képzési céljait, ugyanakkor a három fázisban fejlesztett a képzési időtartamon és a képzési adatokon. Az alábbiakban a három szakasz konkrét fejlesztései következnek:
I. szakasz - Hosszabb képzési idő
A Janushoz képest az Janus-Pro az I. fázisban meghosszabbította a képzési időt, különösen az adapterek és a képfejek képzésében a vizuális részben. Ez azt jelenti, hogy a vizuális jellemzők tanulása több képzési időt kapott, és remélhetőleg a modell teljes mértékben megérti a képek részletes jellemzőit (például a pixel-szemantikai leképezést).
Ez a kiterjesztett képzés segít biztosítani, hogy a vizuális rész képzését ne zavarják meg más modulok.
II. szakasz - ImageNet adatok eltávolítása és multimodális adatok hozzáadása
A II. szakaszban Janus korábban a PixArtra hivatkozott, és két részben képezte magát. Az első részt az ImageNet adathalmazon képosztályozási feladatra, a második részt pedig a szokásos szöveg-kép adatokon képeztük. A II. fázisban az idő körülbelül kétharmadát az első rész betanításával töltöttük.
Az Janus-Pro eltávolítja az ImageNet képzést a II. szakaszban. Ez a kialakítás lehetővé teszi a modell számára, hogy a II. fázisban a szövegből képbe történő képzés során a szövegből képbe történő adatokra összpontosítson. A kísérleti eredmények szerint ez jelentősen javíthatja a szöveg-kép adatok kihasználását.
A képzési módszer kialakításának kiigazítása mellett a II. szakaszban használt képzési adathalmaz már nem korlátozódik egyetlen képosztályozási feladatra, hanem több más típusú multimodális adatot, például képleírást és párbeszédet is tartalmaz a közös képzéshez.
III. szakasz - Az adatarány optimalizálása
A III. képzési szakaszban az Janus-Pro beállítja a különböző típusú képzési adatok arányát.
Korábban a Janus által a III. szakaszban használt képzési adatokban a multimodális megértési adatok, a sima szöveges adatok és a szöveg-kép adatok aránya 7:3:10 volt. Az Janus-Pro csökkenti az utóbbi két adattípus arányát, és a három adattípus arányát 5:1:4-re állítja be, vagyis nagyobb figyelmet fordít a multimodális megértési feladatra.
Nézzük meg a képzési adatokat.
A Janushoz képest az Janus-Pro ezúttal jelentősen növeli a kiváló minőségű szintetikus adatok.
A multimodális megértéshez és képgeneráláshoz szükséges képzési adatok mennyiségét és változatosságát bővíti.
A multimodális megértési adatok bővítése:
Az Janus-Pro a képzés során a DeepSeek-VL2 adathalmazra hivatkozik, és mintegy 90 millió további adatpontot ad hozzá, amelyek nemcsak képleíró adathalmazokat, hanem összetett jelenetek, például táblázatok, diagramok és dokumentumok adathalmazait is tartalmazzák.
A felügyelt finomhangolási szakasz (III. szakasz) során a MEME megértésével és a párbeszéd (beleértve a kínai párbeszédet is) tapasztalatainak javításával kapcsolatos adathalmazok hozzáadása folytatódik.
A vizuális generációs adatok bővítése:
Az eredeti valós adatok rossz minőségűek és nagy zajszintűek voltak, ami miatt a modell instabil kimeneteket és nem megfelelő esztétikai minőségű képeket produkált a szöveg-kép feladatokban.
Az Janus-Pro körülbelül 72 millió új, magas esztétikai szintetikus adatot adott hozzá a képzési fázishoz, így a valós adatok és a szintetikus adatok aránya az előzetes képzési fázisban 1:1-re nőtt.
A szintetikus adatokra vonatkozó kérések mind nyilvános forrásokból származnak. A kísérletek azt mutatták, hogy ezen adatok hozzáadásával a modell gyorsabban konvergál, és a generált képek stabilitása és vizuális szépsége egyértelműen javul.
A hatékonysági forradalom folytatása?
Összességében ezzel a kiadással a DeepSeek forradalmasította a vizuális modellek hatékonyságát.
Az egyetlen funkcióra összpontosító vizuális modellekkel vagy az egy adott feladatot előnyben részesítő multimodális modellekkel ellentétben az Janus-Pro a két fő feladat, a képalkotás és a multimodális megértés hatásait egyazon modellben egyensúlyozza.
Ráadásul kis paraméterei ellenére az értékelésben megelőzte az OpenAI DALL-E 3 és az SD3-Mediumot.
A földre kiterjesztve a vállalkozásnak csak egy modellt kell telepítenie a képgenerálás és a megértés két funkciójának közvetlen megvalósításához. A mindössze 7B mérethez párosulva a telepítés nehézsége és költsége sokkal kisebb.
Az R1 és a V3 korábbi kiadásaihoz kapcsolódóan a DeepSeek a meglévő játékszabályokat kérdőjelezi meg a következőkkel "kompakt építészeti innováció, könnyű modellek, nyílt forráskódú modellek és rendkívül alacsony képzési költségek". Ez az oka a nyugati technológiai óriások, sőt a Wall Street pánikjának.
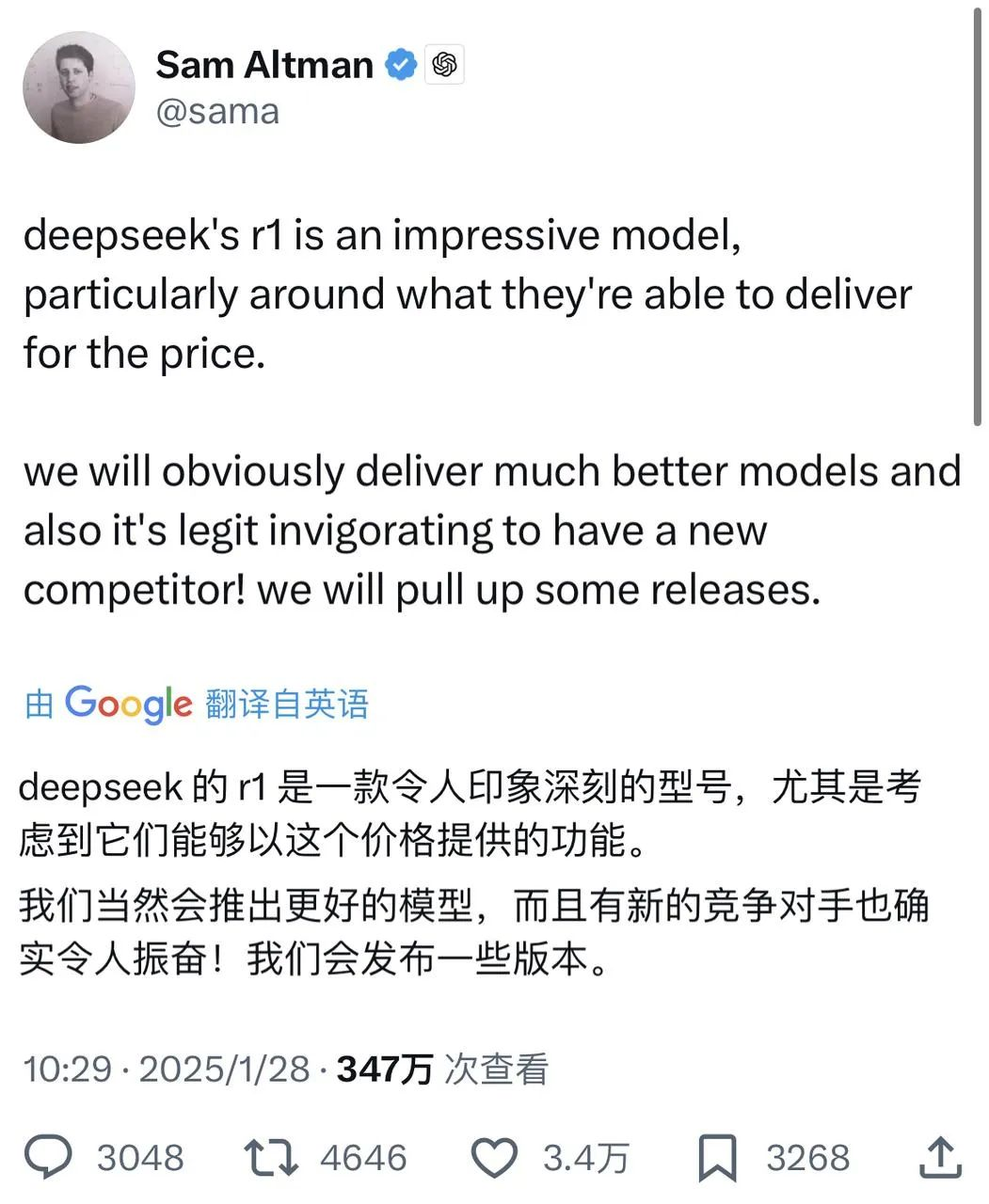
Éppen most Sam Altman, akit napok óta sodort a közvélemény, végre pozitívan reagált az X-en a DeepSeekről szóló információkra - miközben dicsérte az R1-et, azt mondta, hogy az OpenAI fog néhány bejelentést tenni.