DeepSeek on päivittänyt verkkosivustonsa.
Uudenvuodenaattona DeepSeek ilmoitti yllättäen GitHubissa, että Janus-projektitila oli avannut lähdekoodin Janus-Pro-mallin ja teknisen raportin.
Korostetaan ensin muutamia keskeisiä kohtia:
- The Janus-Pro-malli on tällä kertaa julkaistu multimodaalinen malli, jossa voi suorittaa samanaikaisesti multimodaalisia ymmärtämis- ja kuvantuotantotehtäviä. Sillä on yhteensä kaksi parametriversiota, Janus-Pro-1B ja Janus-Pro-7B.
- Janus-Pro:n keskeisenä innovaationa on erottaa toisistaan multimodaalinen ymmärtäminen ja tuottaminen, kaksi eri tehtävää. Näin nämä kaksi tehtävää voidaan suorittaa tehokkaasti samassa mallissa..
- Janus-Pro on yhdenmukainen DeepSeekin viime lokakuussa julkaiseman Janus-malliarkkitehtuurin kanssa, mutta tuolloin Janusin volyymi ei ollut vielä kovin suuri. Tohtori Charles, joka on algoritmien asiantuntija, kertoi meille, että edellinen Janus oli "keskinkertainen" eikä "yhtä hyvä kuin DeepSeekin kielimalli".

Sen tarkoituksena on ratkaista alan vaikea ongelma: tasapainoilu multimodaalisen ymmärtämisen ja kuvien tuottamisen välillä.
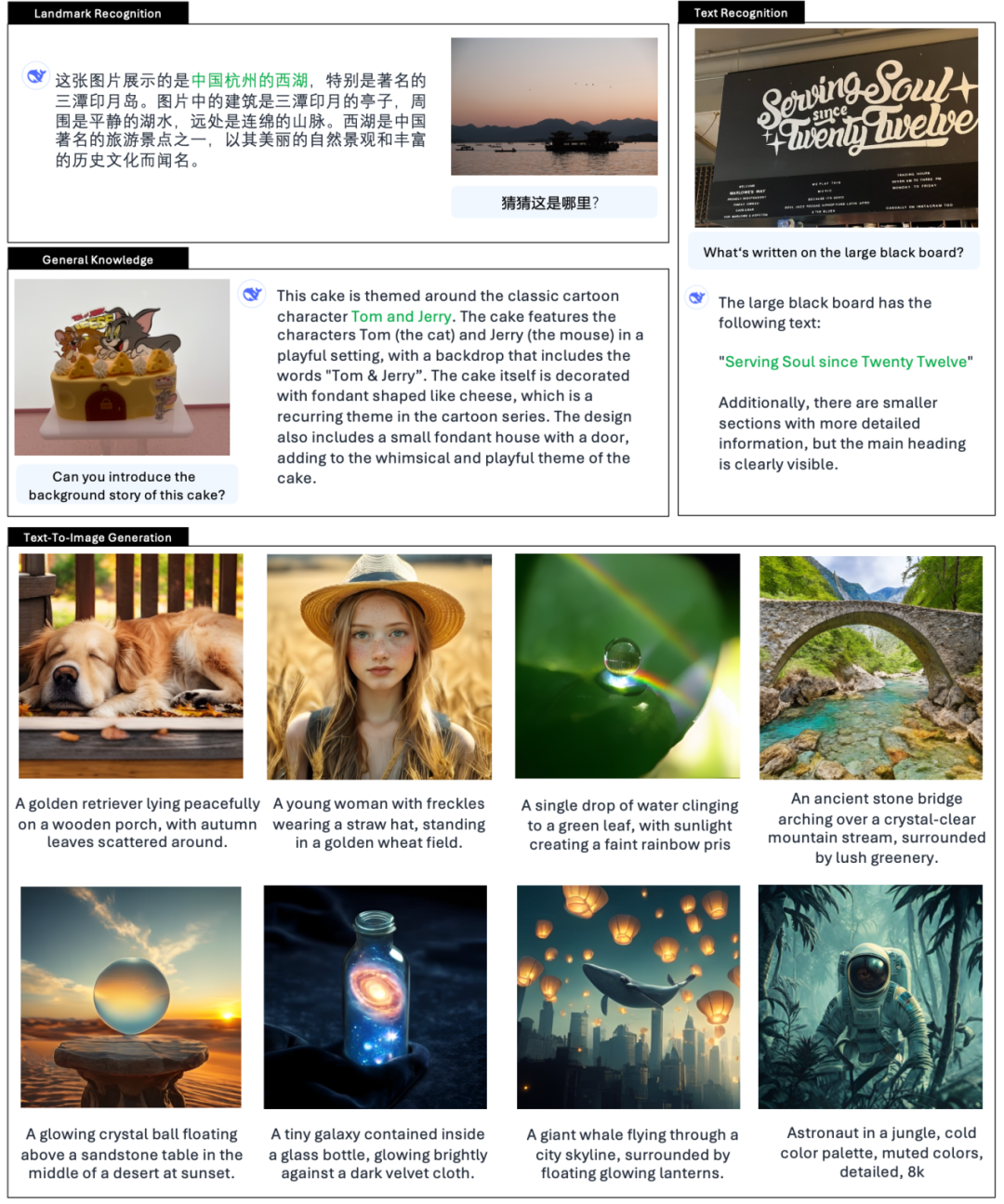
DeepSeekin virallisen esittelyn mukaan, Janus-Pro voi paitsi ymmärtää kuvia, poimia ja ymmärtää kuvien tekstiä, myös luoda kuvia samanaikaisesti.
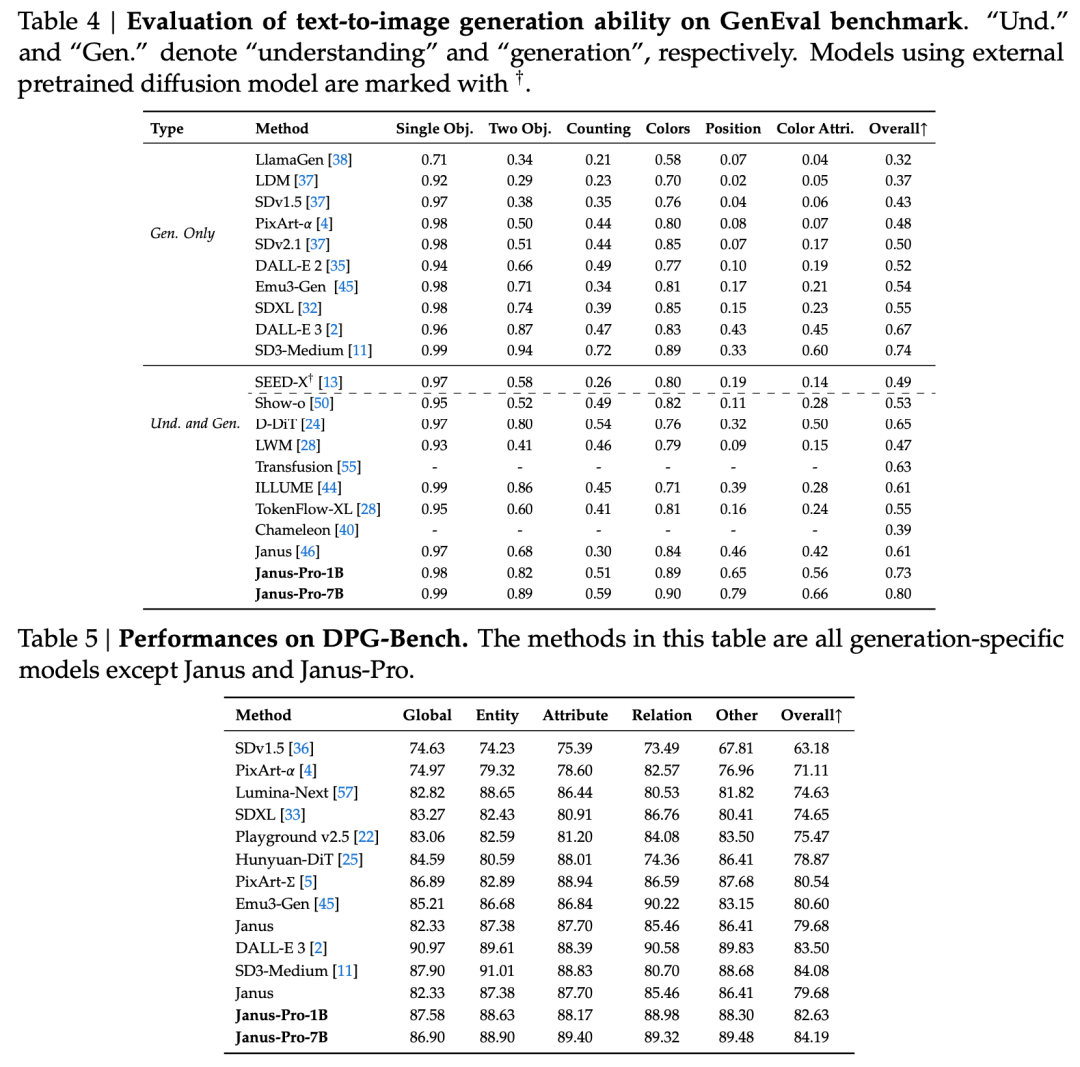
Teknisessä raportissa mainitaan, että verrattuna muihin samantyyppisiin ja samaa suuruusluokkaa oleviin malleihin Janus-Pro-7B:n tulokset GenEval- ja DPG-Bench-testisarjoissa ovat seuraavat ylittävät muiden mallien, kuten SD3-Medium ja DALL-E 3, ominaisuudet.
Virkamies antaa myös esimerkkejä 👇:
Myös monet X:n nettikansalaiset kokeilevat uusia ominaisuuksia.

Mutta satunnaisia kaatumisia esiintyy myös.
Tutustumalla seuraaviin teknisiin asiakirjoihin DeepSeek, huomasimme, että Janus Pro on Janukseen perustuva optimointi, joka julkaistiin kolme kuukautta sitten.
Tämän mallisarjan keskeisenä innovaationa on se, että irrottaa visuaalisen ymmärtämisen tehtävät visuaalisen tuottamisen tehtävistä, jotta näiden kahden tehtävän vaikutukset voidaan tasapainottaa.
Ei ole harvinaista, että malli ymmärtää ja tuottaa multimodaalisia tietoja samanaikaisesti. Tässä testisarjassa D-DiT ja TokenFlow-XL kykenevät molemmat tähän.
Janukselle on kuitenkin ominaista, että erottamalla prosessointi toisistaan, malli, joka pystyy multimodaaliseen ymmärtämiseen ja tuottamiseen, tasapainottaa näiden kahden tehtävän tehokkuuden.
Näiden kahden tehtävän tehokkuuden tasapainottaminen on vaikea ongelma alalla. Aikaisemmin ajateltiin käyttää samaa kooderia, jotta multimodaalinen ymmärtäminen ja tuottaminen voitaisiin toteuttaa mahdollisimman laajasti.
Tämän lähestymistavan etuja ovat yksinkertainen arkkitehtuuri, tarpeettoman käyttöönoton välttäminen ja yhdenmukaistaminen tekstimallien kanssa (jotka myös käyttävät samoja menetelmiä tekstin tuottamiseen ja ymmärtämiseen). Toinen argumentti on se, että tämä useiden kykyjen yhdistäminen voi johtaa tietynasteiseen emergenssiin.
Itse asiassa, kun sukupolven ja ymmärtämisen yhdistämisen jälkeen nämä kaksi tehtävää ovat ristiriidassa keskenään - kuvan ymmärtäminen edellyttää, että malli abstrahoi korkeissa ulottuvuuksissa ja poimii kuvan keskeisen semantiikan, joka on yksipuolisesti makroskooppinen. Kuvan generointi puolestaan keskittyy paikallisten yksityiskohtien ilmaisemiseen ja tuottamiseen pikselitasolla.
Alan tavanomainen käytäntö on asettaa kuvantuotantokyky etusijalle. Tämä johtaa multimodaalisiin malleihin, jotka voidaan tuottaa laadukkaampia kuvia, mutta kuvan ymmärtämisen tulokset ovat usein keskinkertaisia.
Januksen irrotettu arkkitehtuuri ja Janus-Pro:n optimoitu koulutusstrategia.
Janusin erillisen arkkitehtuurin ansiosta malli pystyy tasapainottamaan ymmärtämisen ja tuottamisen tehtävät itsenäisesti.
Virallisessa teknisessä raportissa esitettyjen tulosten mukaan Janus-Pro-7B suoriutuu hyvin useista testikokonaisuuksista riippumatta siitä, onko kyse multimodaalisesta ymmärtämisestä vai kuvien luomisesta.

Multimodaalista ymmärtämistä varten, Janus-Pro-7B saavutti ensimmäisen sijan neljässä seitsemästä arviointitietokannasta ja toisen sijan kolmessa muussa arvioinnissa, hieman jäljessä parhaiten sijoittuneesta mallista.
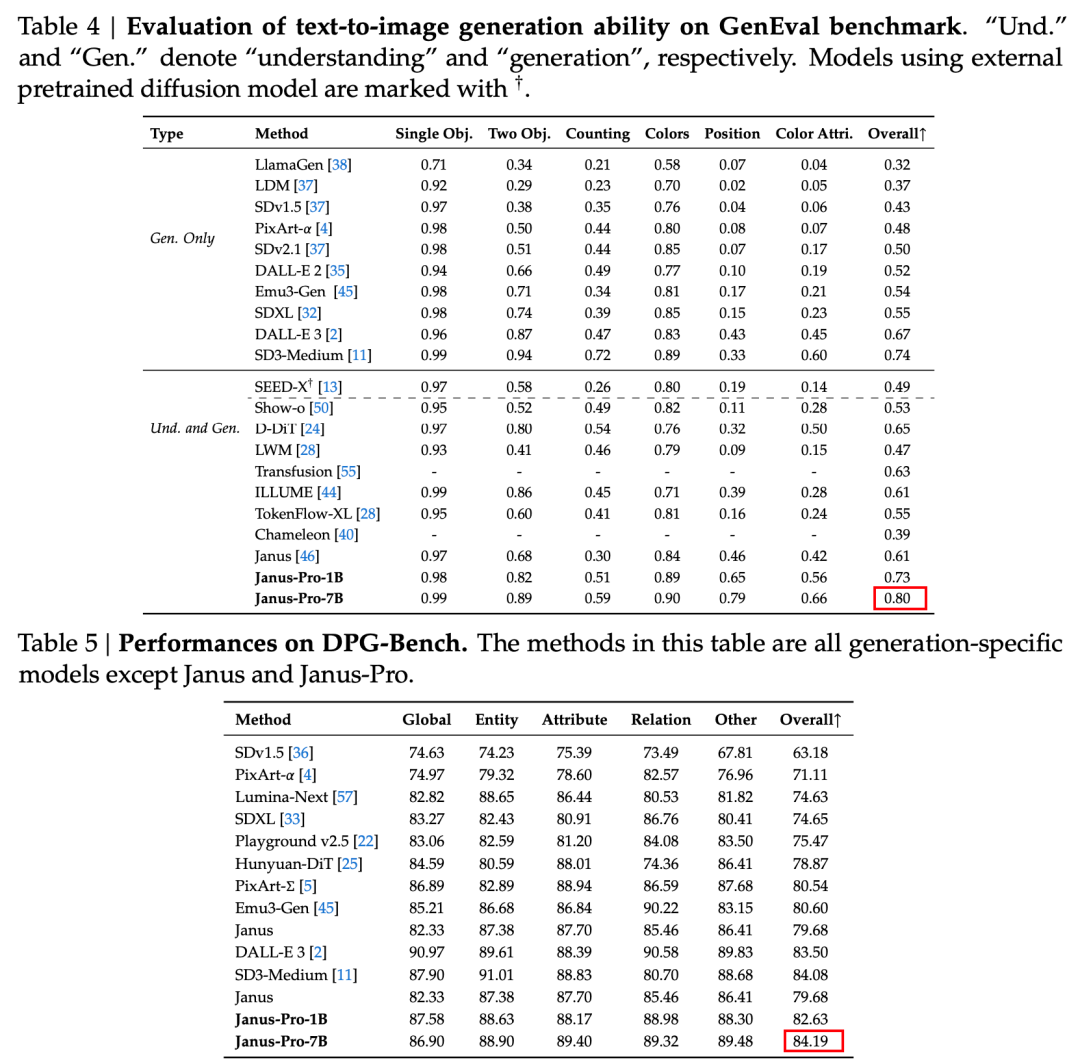
Kuvien luomista varten, Janus-Pro-7B saavutti ensimmäisen sijan kokonaispisteissä sekä GenEval- että DPG-Bench-arviointitietokannoissa.
Tämä monitehtävävaikutus johtuu pääasiassa siitä, että Janus-sarjassa käytetään kahta visuaalista kooderia eri tehtäviin:
- Kooderin ymmärtäminen: käytetään erottamaan kuvien semanttisia piirteitä kuvien ymmärtämistehtäviä varten (kuten kuvakysymykset ja -vastaukset, visuaalinen luokittelu jne.).
- Generatiivinen koodaaja: muuntaa kuvat diskreetiksi esitykseksi (esim. VQ-kooderin avulla) tekstin ja kuvan välisiä generointitehtäviä varten.
Tällä arkkitehtuurilla, malli voi optimoida itsenäisesti kunkin koodaimen suorituskyvyn, jotta multimodaalinen ymmärtäminen ja tuottaminen voivat saavuttaa parhaan mahdollisen suorituskyvyn.
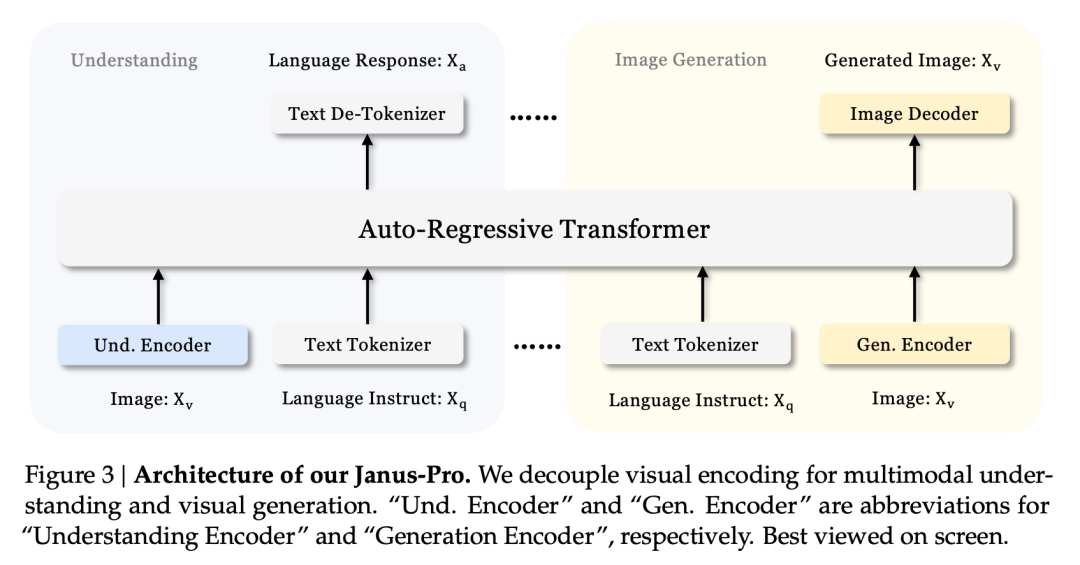
Tämä erotettu arkkitehtuuri on yhteinen Janus-Pro:lle ja Janukselle. Millaisia iteraatioita Janus-Pro:llä on ollut viime kuukausina?
Kuten arviointijoukkojen tuloksista käy ilmi, nykyinen Janus-Pro-1B-versio on parantanut eri arviointijoukkojen pistemääriä noin 10%-20% edelliseen Janus-versioon verrattuna. Janus-Pro-7B:llä on suurin parannus, noin 45%, Janukseen verrattuna sen jälkeen, kun parametrien määrää on laajennettu.

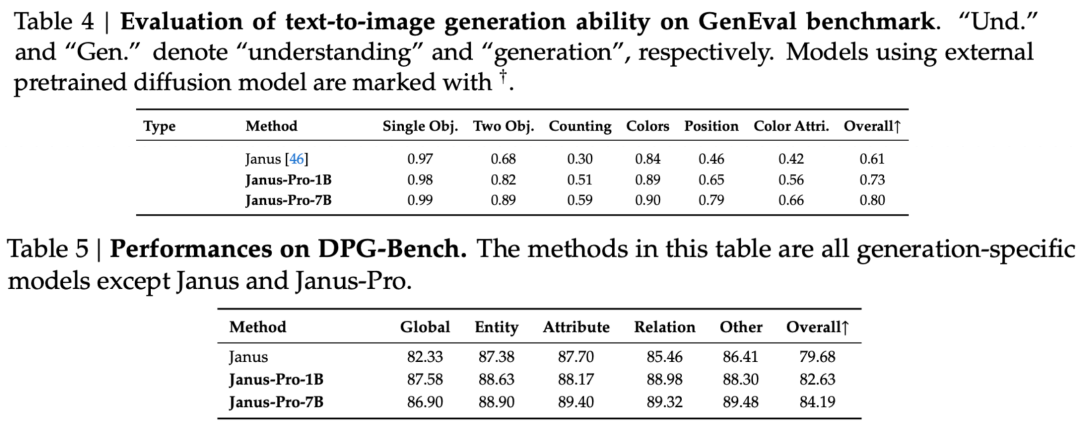
Koulutuksen yksityiskohtien osalta teknisessä raportissa todetaan, että Janus-Pro:n nykyisessä versiossa säilytetään aiempaan Janus-malliin verrattuna ydinarkkitehtuurin irrotettu rakenne ja lisäksi iteroidaan seuraavia asioita. parametrien koko, harjoitusstrategia ja harjoitusaineisto.
Tarkastellaan ensin parametreja.
Januksen ensimmäisessä versiossa oli vain 1,3B parametria, ja nykyinen Pro-versio sisältää malleja, joissa on 1B ja 7B parametria.
Nämä kaksi kokoa kuvastavat Janus-arkkitehtuurin skaalautuvuutta. Ulkopuoliset käyttäjät ovat jo käyttäneet 1B-mallia, joka on kevyin, selaimessa WebGPU:n avulla.
On myös ... koulutusstrategia.
Janus-ohjelman koulutusvaiheiden jaottelun mukaisesti Janus Pro:ssä on yhteensä kolme koulutusvaihetta, jotka jaetaan tässä asiakirjassa suoraan vaiheeseen I, vaiheeseen II ja vaiheeseen III.
Vaikka Janus-Pro on säilyttänyt kunkin vaiheen peruskoulutusideat ja koulutustavoitteet, se on tehnyt parannuksia koulutuksen kestoon ja koulutustietoihin kolmessa vaiheessa. Seuraavassa on lueteltu kolmen vaiheen erityiset parannukset:
Vaihe I - Pidempi harjoitteluaika
Janukseen verrattuna Janus-Pro on pidentänyt koulutusaikaa vaiheessa I, erityisesti sovittimien ja kuvapäiden koulutuksessa visuaalisessa osassa. Tämä tarkoittaa, että visuaalisten piirteiden oppimiseen on annettu enemmän harjoitusaikaa, ja mallin toivotaan ymmärtävän täysin kuvien yksityiskohtaiset piirteet (kuten pikselin ja semanttisen kartoituksen).
Tämä laajennettu harjoittelu auttaa varmistamaan, että muut moduulit eivät häiritse visuaalisen osan harjoittelua.
Vaihe II - ImageNet-tietojen poistaminen ja multimodaalisten tietojen lisääminen.
Vaiheessa II Janus viittasi aiemmin PixArtiin ja harjoitteli kahdessa osassa. Ensimmäinen osa koulutettiin ImageNet-tietokannan avulla kuvien luokittelutehtävää varten, ja toinen osa koulutettiin tavallisella tekstin ja kuvan välisellä datalla. Noin kaksi kolmasosaa vaiheen II ajasta käytettiin ensimmäisen osan harjoitteluun.
Janus-Pro poistaa ImageNet-koulutuksen vaiheessa II. Tämän rakenteen ansiosta malli voi keskittyä tekstistä kuvaan -tietoihin vaiheen II harjoittelussa. Kokeellisten tulosten mukaan tämä voi parantaa merkittävästi tekstistä kuviin -tietojen hyödyntämistä.
Harjoittelumenetelmän suunnittelun mukauttamisen lisäksi vaiheessa II käytetty harjoitteluaineisto ei enää rajoitu vain yhteen kuvien luokittelutehtävään, vaan se sisältää myös enemmän muun tyyppistä multimodaalista dataa, kuten kuvien kuvausta ja vuoropuhelua, yhteistä harjoittelua varten.
Vaihe III - Tietosuhteen optimointi
Koulutusvaiheessa III Janus-Pro säätää erityyppisten harjoitustietojen suhdetta.
Aiemmin Januksen käyttämässä harjoitusaineistossa vaiheessa III multimodaalisen ymmärtämisen datan, pelkän tekstin datan ja tekstin ja kuvan datan suhde oli 7:3:10. Janus-Pro vähentää kahden jälkimmäisen datatyypin suhdetta ja säätää kolmen datatyypin suhdeluvun 5:1:4:ään eli kiinnittää enemmän huomiota multimodaaliseen ymmärtämistehtävään.
Tarkastellaan harjoitusaineistoa.
Janukseen verrattuna Janus-Pro lisää tällä kertaa merkittävästi korkealaatuisen ja korkealaatuisen synteettiset tiedot.
Se laajentaa multimodaalisen ymmärtämisen ja kuvien tuottamisen harjoitusdatan määrää ja monipuolisuutta.
Multimodaalisen ymmärtämistiedon laajentaminen:
Janus-Pro viittaa DeepSeek-VL2-tietokantaan harjoittelun aikana ja lisää siihen noin 90 miljoonaa ylimääräistä datapistettä, mukaan lukien kuvien kuvaustietokantojen lisäksi myös monimutkaisten kohtausten, kuten taulukoiden, kaavioiden ja asiakirjojen, tietokannat.
Valvotussa hienosäätövaiheessa (vaihe III) se jatkaa MEME:n ymmärtämiseen ja vuoropuhelun (myös kiinalaisen vuoropuhelun) kokemusten parantamiseen liittyvien tietokokonaisuuksien lisäämistä.
Visuaalisen sukupolven tietojen laajentaminen:
Alkuperäisen reaalimaailman datan laatu oli heikko ja kohinataso korkea, minkä vuoksi malli tuotti epävakaita tuloksia ja esteettisesti riittämättömiä kuvia tekstistä kuvaan -tehtävissä.
Janus-Pro lisäsi harjoitusvaiheeseen noin 72 miljoonaa uutta, erittäin esteettistä synteettistä dataa, jolloin todellisen datan ja synteettisen datan suhde esiharjoitteluvaiheessa oli 1:1.
Synteettisten tietojen kehotukset on kaikki otettu julkisista lähteistä. Kokeet ovat osoittaneet, että näiden tietojen lisääminen nopeuttaa mallin konvergoitumista, ja luotujen kuvien vakaus ja visuaalinen kauneus ovat parantuneet selvästi.
Tehokkuusvallankumouksen jatkuminen?
Kaiken kaikkiaan DeepSeek on tuonut tämän julkaisun myötä tehokkuuden vallankumouksen visuaalisiin malleihin.
Toisin kuin visuaaliset mallit, jotka keskittyvät yhteen tehtävään, tai multimodaaliset mallit, jotka suosivat tiettyä tehtävää, Janus-Pro tasapainottaa kahden tärkeimmän tehtävän, kuvan tuottamisen ja multimodaalisen ymmärtämisen, vaikutuksia samassa mallissa.
Lisäksi se päihitti pienistä parametreistaan huolimatta OpenAI DALL-E 3:n ja SD3-Mediumin arvioinnissa.
Maahan asti laajennettuna yrityksen tarvitsee vain ottaa käyttöön malli, jolla voidaan suoraan toteuttaa kaksi toimintoa: kuvien tuottaminen ja ymmärtäminen. Kun malli on kooltaan vain 7B, käyttöönoton vaikeus ja kustannukset ovat paljon pienemmät.
Aiempien R1- ja V3-julkaisujen yhteydessä DeepSeek haastaa nykyiset pelisäännöt "kompakti arkkitehtuuri-innovaatio, kevyet mallit, avoimen lähdekoodin mallit ja erittäin alhaiset koulutuskustannukset". Tämä on syy länsimaisten teknologiajättien ja jopa Wall Streetin paniikkiin.
Juuri nyt Sam Altman, jota yleinen mielipide on vienyt mukanaan jo useiden päivien ajan, vastasi vihdoin myönteisesti DeepSeek on X:ää koskeviin tietoihin - samalla kun hän kehui R1:ää, hän sanoi, että OpenAI tekee joitakin ilmoituksia.