DeepSeek și-a actualizat site-ul web.
În primele ore ale nopții de Anul Nou, DeepSeek a anunțat brusc pe GitHub că spațiul proiectului Janus a deschis sursa modelului Janus-Pro și a raportului tehnic.
Mai întâi, să subliniem câteva puncte cheie:
- The Model Janus-Pro lansat de această dată este un model multimodal care poate efectua simultan sarcini de înțelegere multimodală și de generare a imaginilor. Acesta are un total de două versiuni de parametri, Janus-Pro-1B și Janus-Pro-7B.
- Inovația de bază a Janus-Pro este decuplarea înțelegerea și generarea multimodală, două sarcini diferite. Acest lucru permite ca aceste două sarcini să fie îndeplinite eficient în același model.
- Janus-Pro este în concordanță cu arhitectura modelului Janus lansat de DeepSeek în octombrie anul trecut, dar la acel moment Janus nu avea mult volum. Dr. Charles, un expert în algoritmi în domeniul vederii, ne-a spus că Janus anterior era "mediu" și "nu la fel de bun ca modelul lingvistic al DeepSeek".

Acesta este destinat să rezolve problema dificilă a industriei: echilibrarea înțelegerii multimodale și generarea de imagini
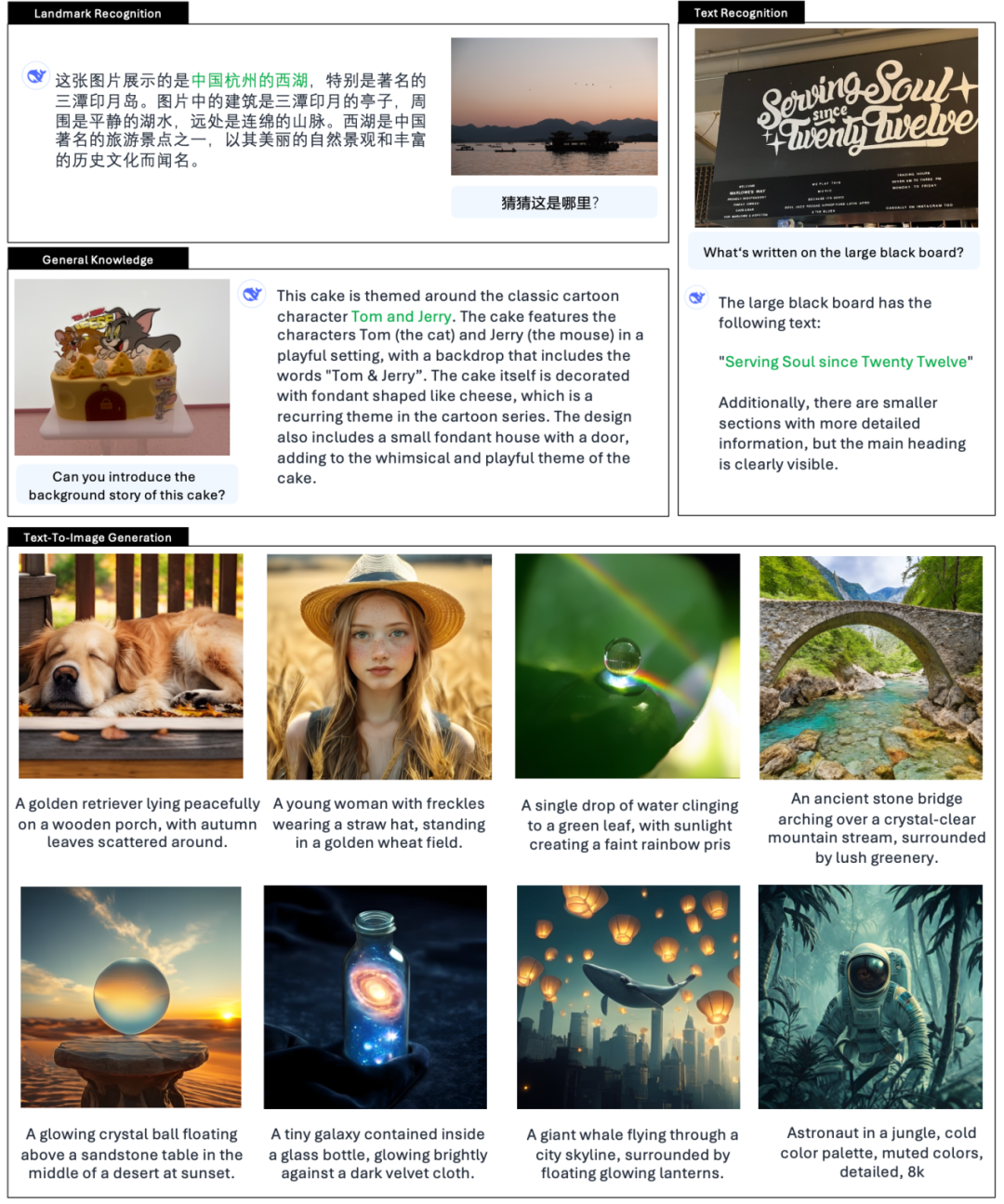
Conform introducerii oficiale a DeepSeek, Janus-Pro poate nu numai să înțeleagă imagini, să extragă și să înțeleagă textul din imagini, ci și să genereze imagini în același timp.
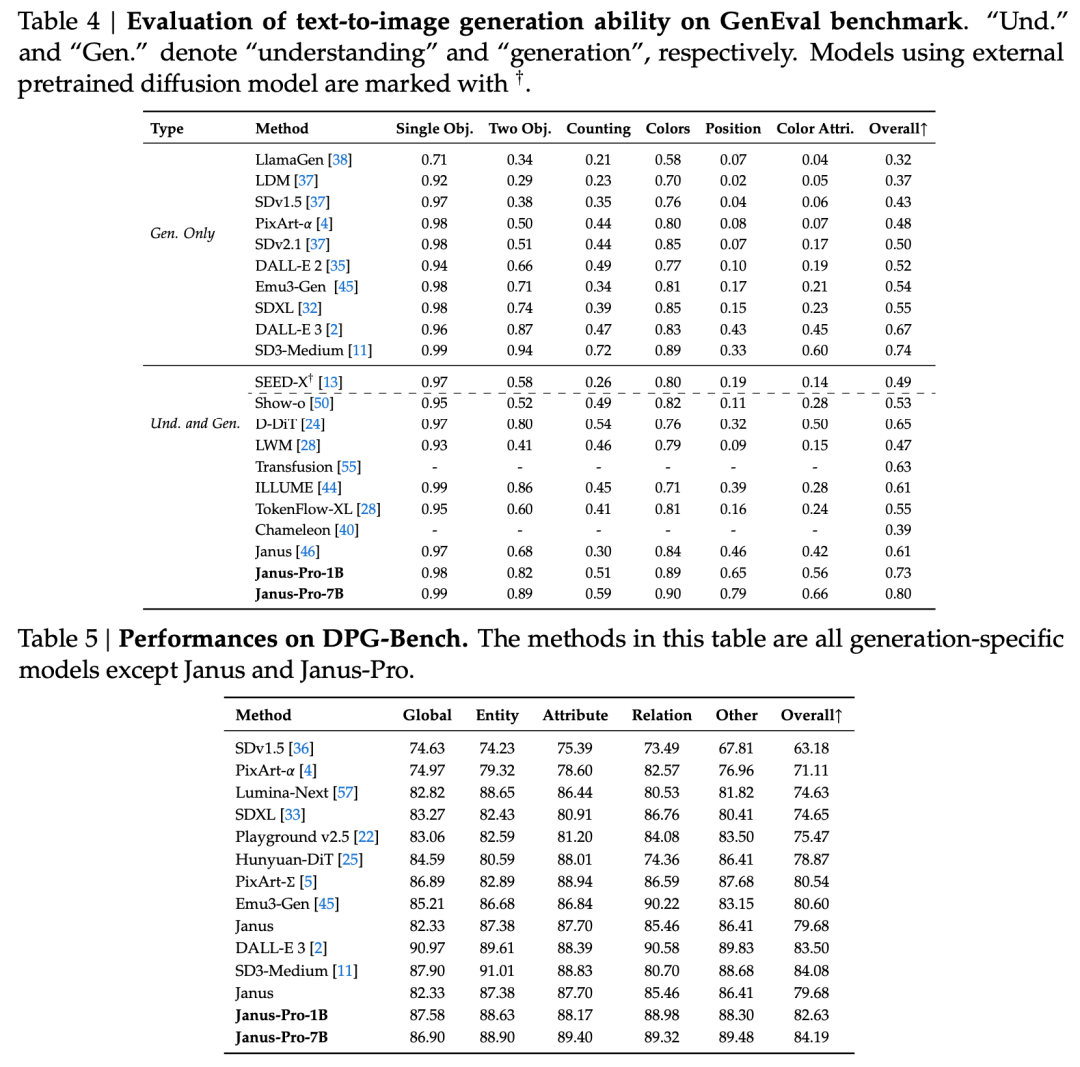
Raportul tehnic menționează că, în comparație cu alte modele de același tip și ordin de mărime, scorurile Janus-Pro-7B la seturile de teste GenEval și DPG-Bench le depășesc pe cele ale altor modele precum SD3-Medium și DALL-E 3.
Oficialul dă și exemple 👇:
Există, de asemenea, mulți internauți pe X care încearcă noile caracteristici.

Dar există și blocaje ocazionale.
Prin consultarea documentelor tehnice privind DeepSeek, am constatat că Janus Pro este o optimizare bazată pe Janus, care a fost lansat acum trei luni.
Inovația principală a acestei serii de modele este decuplarea sarcinilor de înțelegere vizuală de sarcinile de generare vizuală, astfel încât efectele celor două sarcini să poată fi echilibrate.
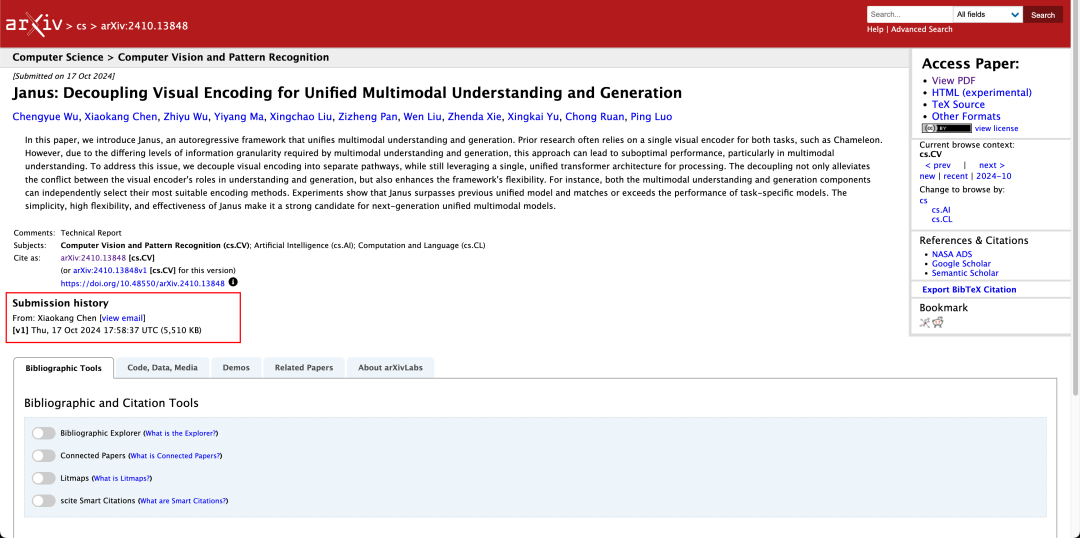
Nu este neobișnuit ca un model să realizeze înțelegerea și generarea multimodală în același timp. D-DiT și TokenFlow-XL din acest set de testare au ambele această capacitate.
Cu toate acestea, ceea ce este caracteristic lui Janus este că prin decuplarea procesării, un model care poate efectua înțelegerea și generarea multimodală echilibrează eficiența celor două sarcini.
Echilibrarea eficienței celor două sarcini este o problemă dificilă în industrie. Anterior, ideea era de a utiliza același codificator pentru a implementa cât mai mult posibil înțelegerea și generarea multimodală.
Avantajele acestei abordări sunt o arhitectură simplă, lipsa unei desfășurări redundante și o aliniere la modelele de text (care utilizează, de asemenea, aceleași metode pentru a realiza generarea și înțelegerea textului). Un alt argument este că această fuziune a mai multor abilități poate conduce la un anumit grad de emergență.
Cu toate acestea, de fapt, după fuzionarea generării și înțelegerii, cele două sarcini vor intra în conflict - înțelegerea imaginilor necesită ca modelul să facă abstracție în dimensiuni mari și să extragă semantica centrală a imaginii, care este orientată spre macroscopic. Generarea imaginilor, pe de altă parte, se concentrează pe exprimarea și generarea detaliilor locale la nivel de pixel.
Practica obișnuită a industriei este de a prioritiza capacitățile de generare a imaginilor. Acest lucru duce la modele multimodale care pot genera imagini de calitate superioară, dar rezultatele înțelegerii imaginilor sunt adesea mediocre.
Arhitectura decuplată a Janus și strategia de formare optimizată a Janus-Pro
Arhitectura decuplată a lui Janus permite modelului să echilibreze singur sarcinile de înțelegere și generare.
Conform rezultatelor din raportul tehnic oficial, fie că este vorba de înțelegerea multimodală sau de generarea de imagini, Janus-Pro-7B are performanțe bune pe mai multe seturi de testare.

Pentru înțelegerea multimodală, Janus-Pro-7B a obținut primul loc în patru din cele șapte seturi de date de evaluare și locul al doilea în celelalte trei, ușor în urma modelului clasat pe primul loc.
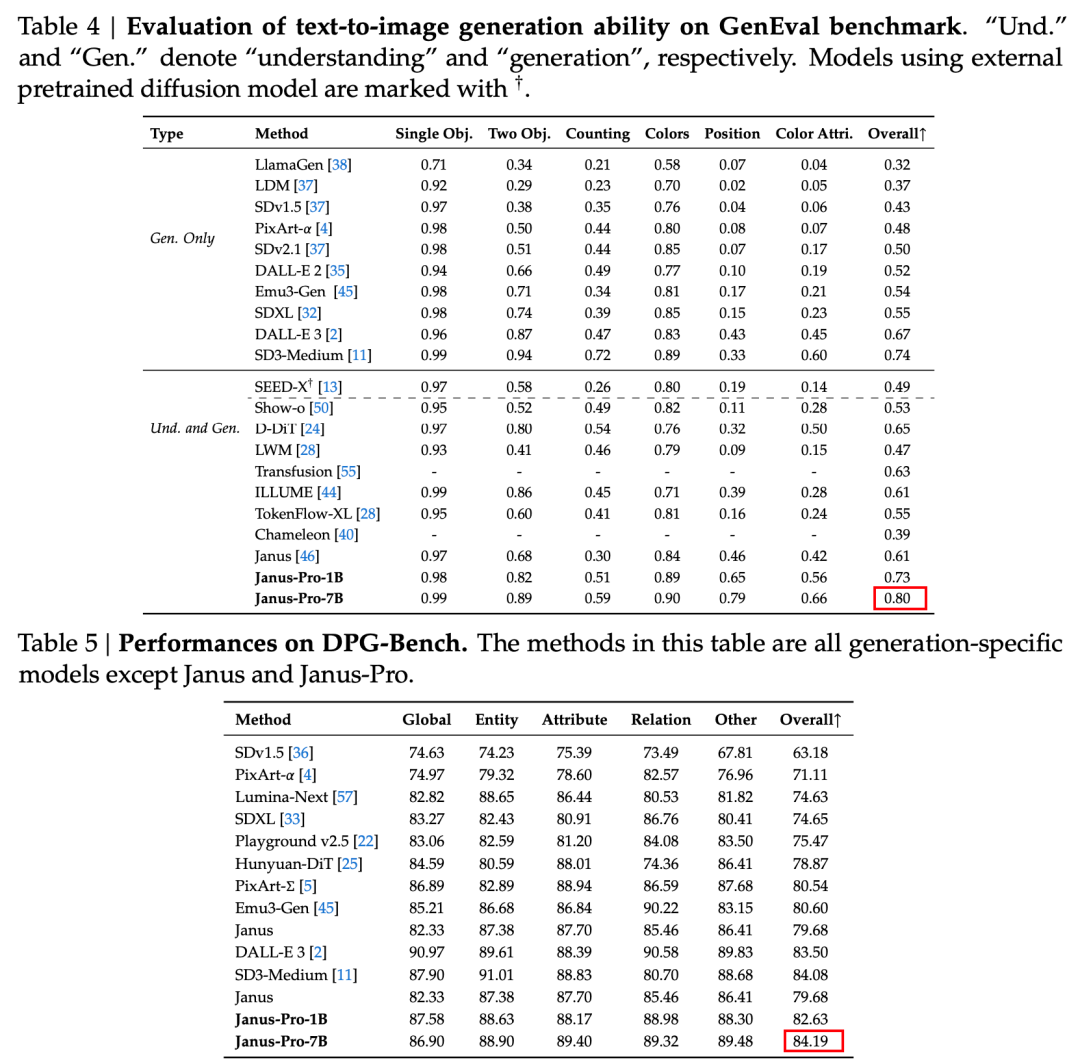
Pentru generarea de imagini, Janus-Pro-7B a obținut primul loc în scorul general atât pentru seturile de date de evaluare GenEval, cât și DPG-Bench.
Acest efect multitasking se datorează în principal utilizării de către seria Janus a doi codificatori vizuali pentru sarcini diferite:
- Înțelegerea codificatorului: utilizate pentru a extrage caracteristici semantice din imagini pentru sarcini de înțelegere a imaginilor (cum ar fi întrebări și răspunsuri la imagini, clasificare vizuală etc.).
- Codificator generativ: convertește imaginile într-o reprezentare discretă (de exemplu, utilizând un codificator VQ) pentru sarcini de generare text-imagine.
Cu această arhitectură, modelul poate optimiza în mod independent performanța fiecărui codificator, astfel încât sarcinile de înțelegere și generare multimodală să poată obține fiecare cea mai bună performanță.
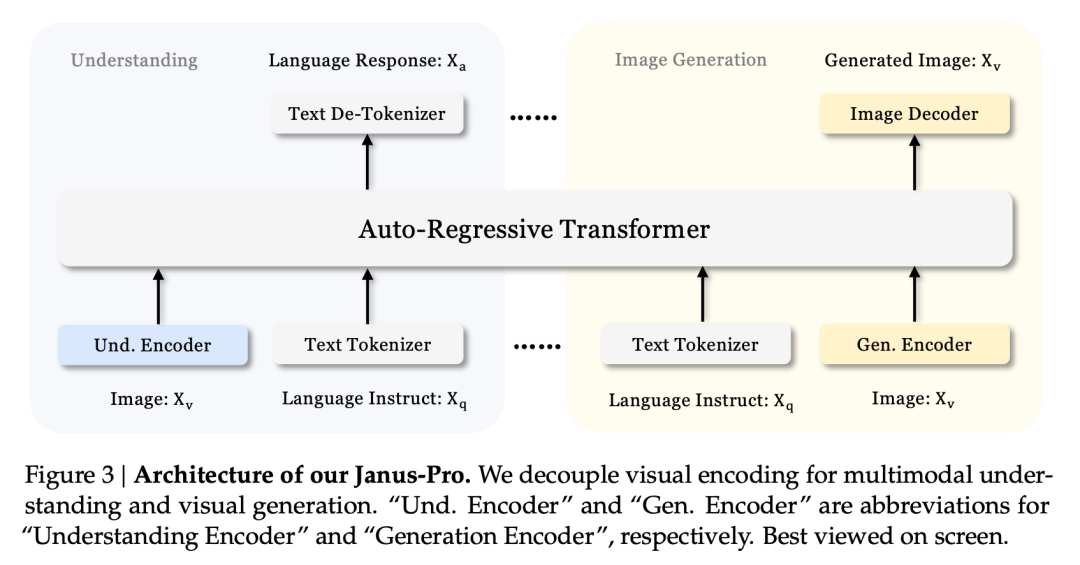
Această arhitectură decuplată este comună pentru Janus-Pro și Janus. Deci, ce iterații a avut Janus-Pro în ultimele câteva luni?
După cum se poate observa din rezultatele setului de evaluare, versiunea actuală a Janus-Pro-1B are o îmbunătățire de aproximativ 10% până la 20% în scorurile diferitelor seturi de evaluare în comparație cu versiunea anterioară Janus. Janus-Pro-7B are cea mai mare îmbunătățire de aproximativ 45% comparativ cu Janus după extinderea numărului de parametri.

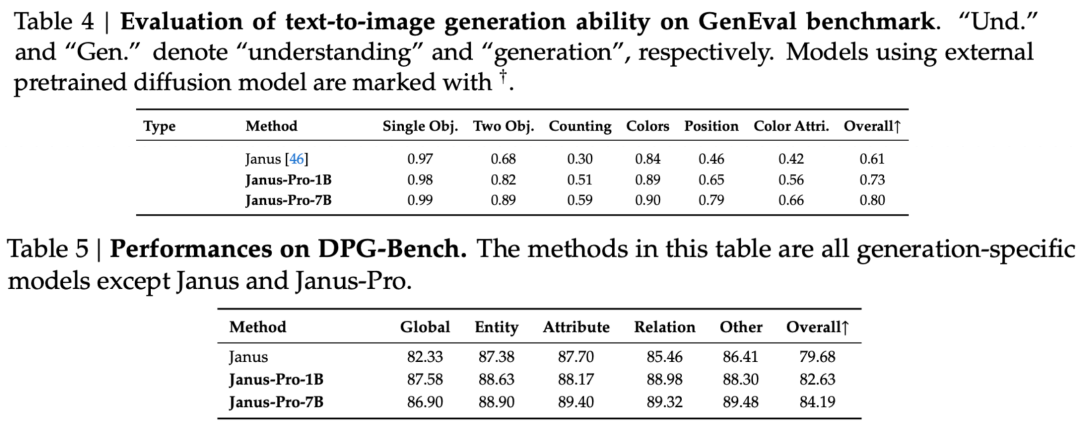
În ceea ce privește detaliile de formare, raportul tehnic afirmă că versiunea actuală a Janus-Pro, în comparație cu modelul Janus anterior, păstrează designul arhitecturii de bază decuplate și, în plus, itera pe dimensiunea parametrilor, strategia de formare și datele de formare.
În primul rând, să ne uităm la parametri.
Prima versiune a Janus avea doar 1,3B parametri, iar versiunea actuală a Pro include modele cu 1B și 7B parametri.
Aceste două dimensiuni reflectă scalabilitatea arhitecturii Janus. Modelul 1B, care este cel mai ușor, a fost deja utilizat de utilizatori externi pentru a rula în browser utilizând WebGPU.
Există, de asemenea a strategia de formare.
În conformitate cu diviziunea fazei de formare a Janus, Janus Pro are un total de trei faze de formare, iar lucrarea le împarte direct în Etapa I, Etapa II și Etapa III.
Păstrând ideile de bază și obiectivele de formare ale fiecărei etape, Janus-Pro a adus îmbunătățiri duratei și datelor de formare în cele trei etape. Următoarele sunt îmbunătățirile specifice celor trei etape:
Etapa I - Timp de formare mai lung
În comparație cu Janus, Janus-Pro a prelungit timpul de formare în etapa I, în special în formarea adaptoarelor și a capetelor de imagine în partea vizuală. Aceasta înseamnă că învățarea caracteristicilor vizuale a beneficiat de mai mult timp de formare și se speră că modelul poate înțelege pe deplin caracteristicile detaliate ale imaginilor (cum ar fi cartografierea pixel-semantică).
Această formare extinsă contribuie la asigurarea faptului că formarea părții vizuale nu este perturbată de alte module.
Etapa II - Eliminarea datelor ImageNet și adăugarea de date multimodale
În etapa II, Janus s-a referit anterior la PixArt și s-a antrenat în două părți. Prima parte a fost antrenată utilizând setul de date ImageNet pentru sarcina de clasificare a imaginilor, iar a doua parte a fost antrenată utilizând date obișnuite text-imagine. Aproximativ două treimi din timpul petrecut în etapa II a fost alocat antrenamentului în prima parte.
Janus-Pro elimină instruirea ImageNet în etapa II. Acest design permite modelului să se concentreze asupra datelor text-imagine în timpul etapei II de formare. Conform rezultatelor experimentale, acest lucru poate îmbunătăți semnificativ utilizarea datelor text-imagine.
În plus față de ajustarea concepției metodei de formare, setul de date de formare utilizat în etapa II nu se mai limitează la o singură sarcină de clasificare a imaginilor, ci include și alte tipuri de date multimodale, cum ar fi descrierea imaginilor și dialogul, pentru formarea comună.
Etapa III - Optimizarea raportului de date
În etapa III de formare, Janus-Pro ajustează raportul dintre diferitele tipuri de date de formare.
Anterior, raportul dintre datele de înțelegere multimodală, datele de text simplu și datele text-imagine în datele de instruire utilizate de Janus în etapa III a fost de 7:3:10. Janus-Pro reduce raportul dintre ultimele două tipuri de date și ajustează raportul dintre cele trei tipuri de date la 5:1:4, adică acordă mai multă atenție sarcinii de înțelegere multimodală.
Să ne uităm la datele de antrenament.
În comparație cu Janus, Janus-Pro crește în mod semnificativ de această dată cantitatea de date sintetice.
Aceasta extinde cantitatea și varietatea de date de instruire pentru înțelegerea multimodală și generarea de imagini.
Extinderea datelor de înțelegere multimodală:
Janus-Pro se referă la setul de date DeepSeek-VL2 în timpul antrenamentului și adaugă aproximativ 90 de milioane de puncte de date suplimentare, inclusiv nu numai seturi de date de descriere a imaginilor, ci și seturi de date de scene complexe, cum ar fi tabele, grafice și documente.
În timpul etapei de reglaj fin supervizat (etapa III), se continuă adăugarea de seturi de date legate de îmbunătățirea experienței de înțelegere și dialog (inclusiv dialogul chinezesc) a MEME.
Extinderea datelor de generare vizuală:
Datele originale din lumea reală aveau o calitate slabă și niveluri ridicate de zgomot, ceea ce făcea ca modelul să producă rezultate instabile și imagini de calitate estetică insuficientă în sarcinile de transformare a textului în imagine.
Janus-Pro a adăugat aproximativ 72 de milioane de noi date sintetice de înaltă estetică la faza de formare, aducând raportul dintre datele reale și datele sintetice în faza de preformare la 1:1.
Solicitările pentru datele sintetice au fost toate preluate din resurse publice. Experimentele au arătat că adăugarea acestor date face ca modelul să converge mai rapid, iar imaginile generate au îmbunătățiri evidente în ceea ce privește stabilitatea și frumusețea vizuală.
Continuarea unei revoluții a eficienței?
În general, cu această versiune, DeepSeek a adus revoluția eficienței în modelele vizuale.
Spre deosebire de modelele vizuale care se concentrează pe o singură funcție sau de modelele multimodale care favorizează o sarcină specifică, Janus-Pro echilibrează efectele celor două sarcini majore de generare a imaginilor și de înțelegere multimodală în același model.
În plus, în ciuda parametrilor săi mici, acesta a depășitOpenAI DALL-E 3 și SD3-Medium în evaluare.
Extinsă la sol, întreprinderea trebuie doar să implementeze un model pentru a implementa direct cele două funcții de generare și înțelegere a imaginilor. Cuplat cu o dimensiune de numai 7B, dificultatea și costul de implementare sunt mult mai mici.
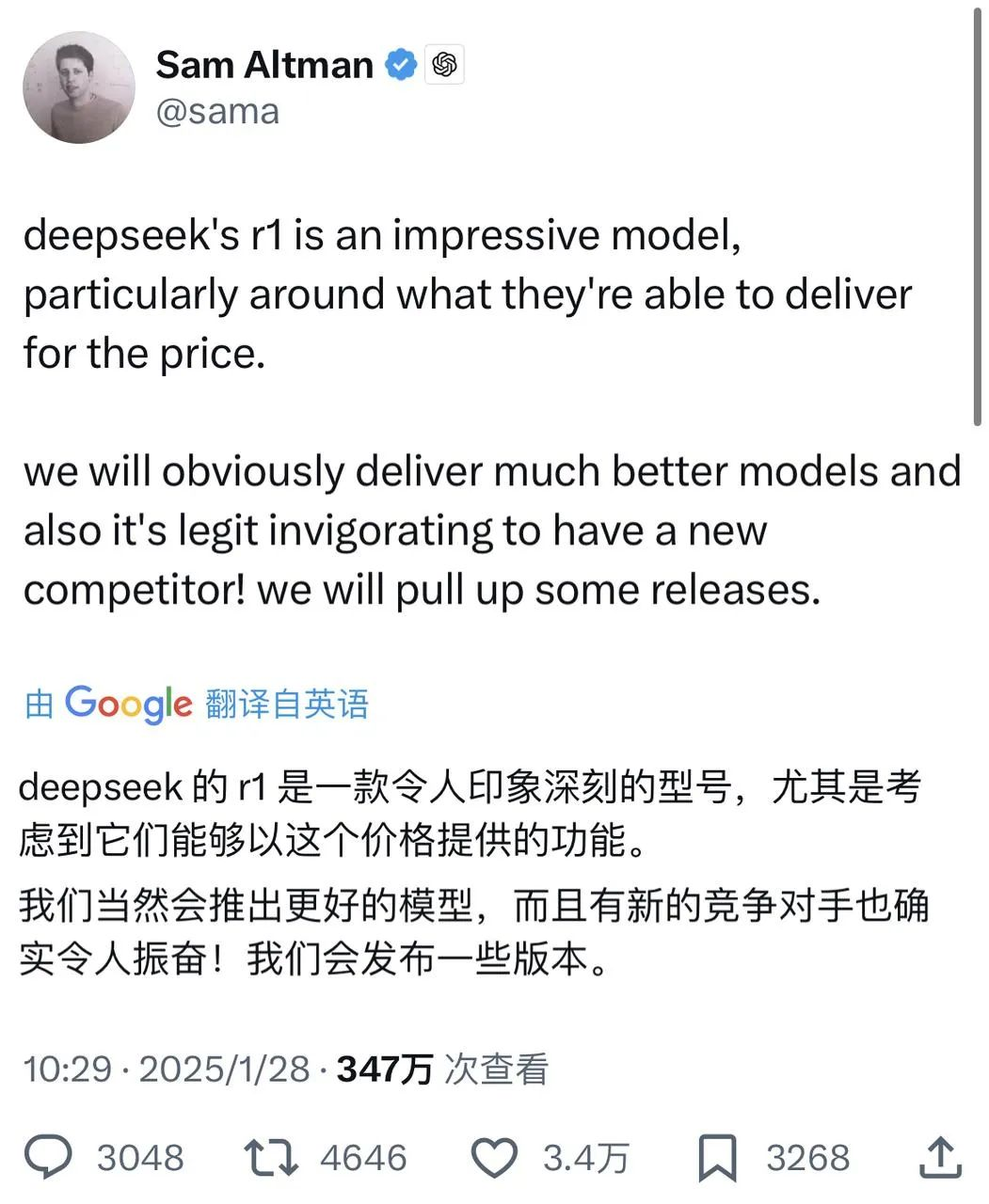
În legătură cu lansările anterioare ale R1 și V3, DeepSeek sfidează regulile existente ale jocului cu "inovație arhitecturală compactă, modele ușoare, modele open source și costuri de formare foarte scăzute". Acesta este motivul panicii în rândul giganților tehnologici occidentali și chiar pe Wall Street.
Chiar acum, Sam Altman, care a fost măturat de opinia publică timp de câteva zile, a răspuns în cele din urmă pozitiv la informațiile despre DeepSeek pe X - în timp ce lăuda R1, a spus că OpenAI va face unele anunțuri.