Компания DeepSeek обновила свой веб-сайт.
Ранним утром в канун Нового года компания DeepSeek неожиданно объявила на GitHub, что в пространстве проекта Janus открыты исходные данные модели Janus-Pro и технический отчет.
Прежде всего, давайте выделим несколько ключевых моментов:
- Сайт Модель Janus-Pro На этот раз выпущена мультимодальная модель, которая может одновременно выполнять задачи мультимодального понимания и генерации изображений. Он имеет две версии параметров, Janus-Pro-1B и Janus-Pro-7B.
- Основная инновация Janus-Pro заключается в развязке Мультимодальное понимание и генерация - две разные задачи. Это позволяет эффективно решать эти две задачи в одной модели.
- Janus-Pro соответствует архитектуре модели Janus, выпущенной DeepSeek в октябре прошлого года, но на тот момент Janus не имел большого объема. Доктор Чарльз, эксперт по алгоритмам в области зрения, сказал нам, что предыдущая модель Janus была "средней" и "не такой хорошей, как языковая модель DeepSeek".

Он призван решить сложную для отрасли задачу: сбалансировать мультимодальное понимание и создание изображений.
Согласно официальному представлению DeepSeek, Janus-Pro может не только понимать картинки, извлекать и понимать текст на картинках, но и одновременно генерировать картинки.
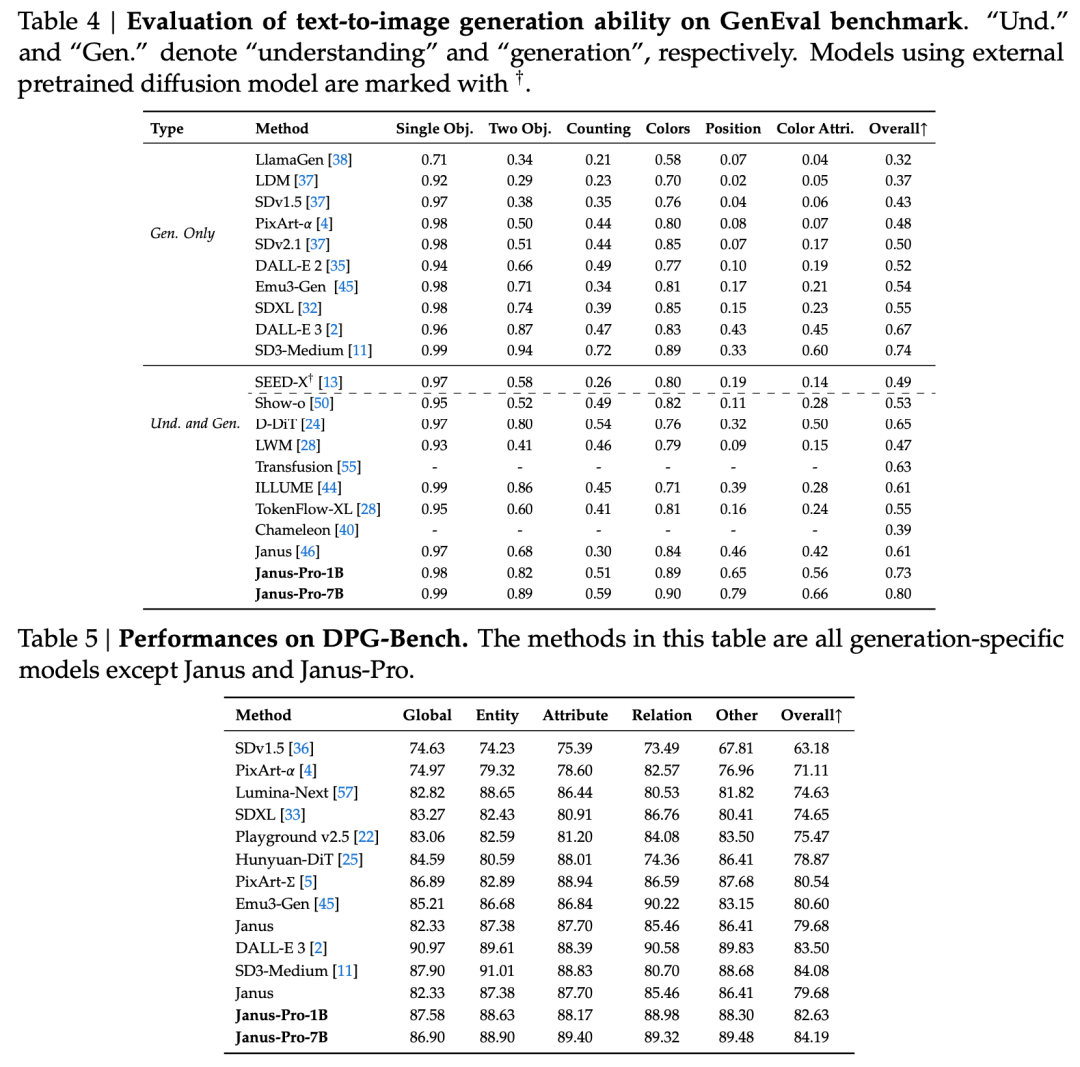
В техническом отчете отмечается, что по сравнению с другими моделями того же типа и порядка, результаты Janus-Pro-7B в тестовых наборах GenEval и DPG-Bench превышают показатели других моделей, таких как SD3-Medium и DALL-E 3.
Чиновник также приводит примеры 👇:
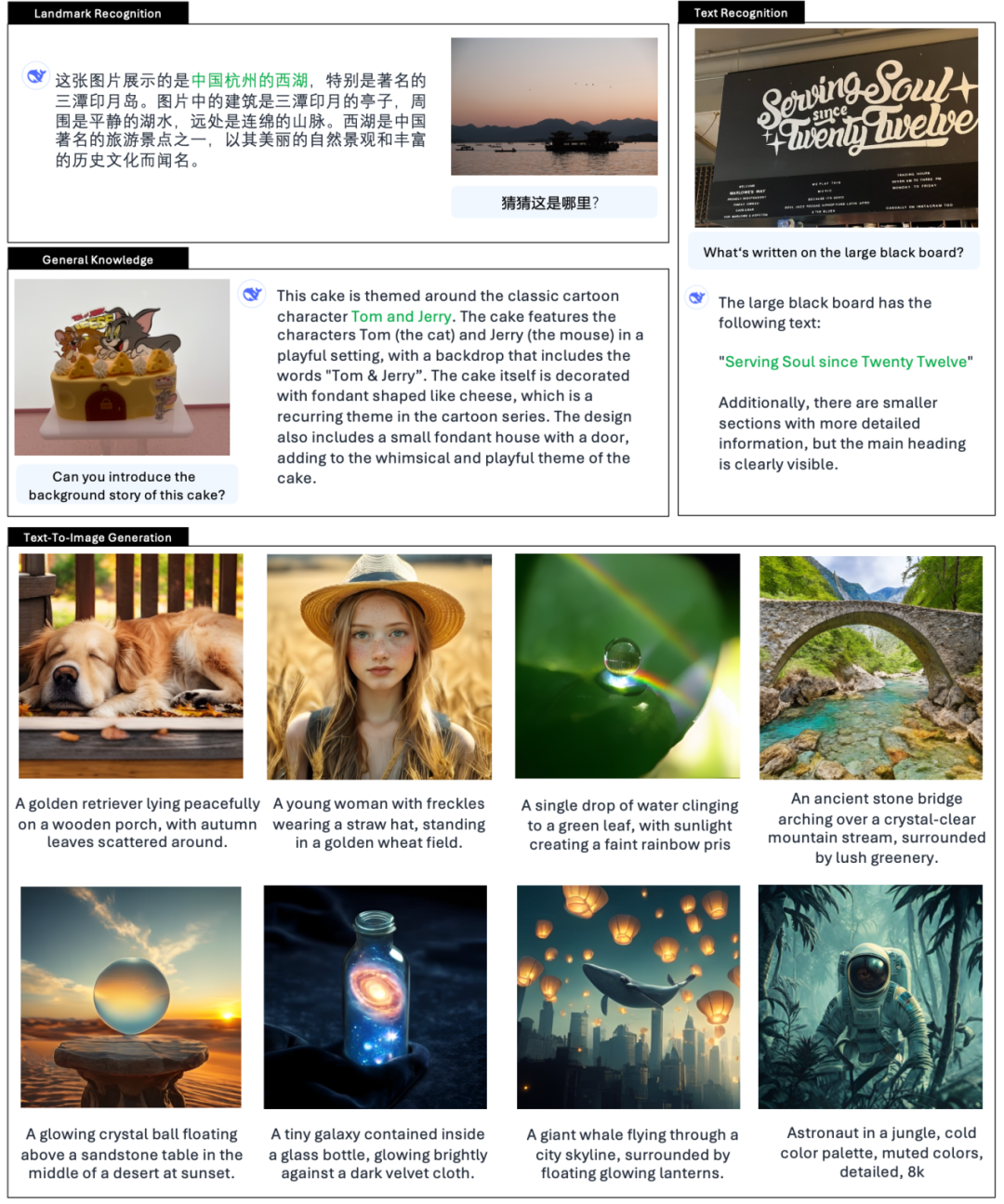
Многие нетизены на X также пробуют новые функции.

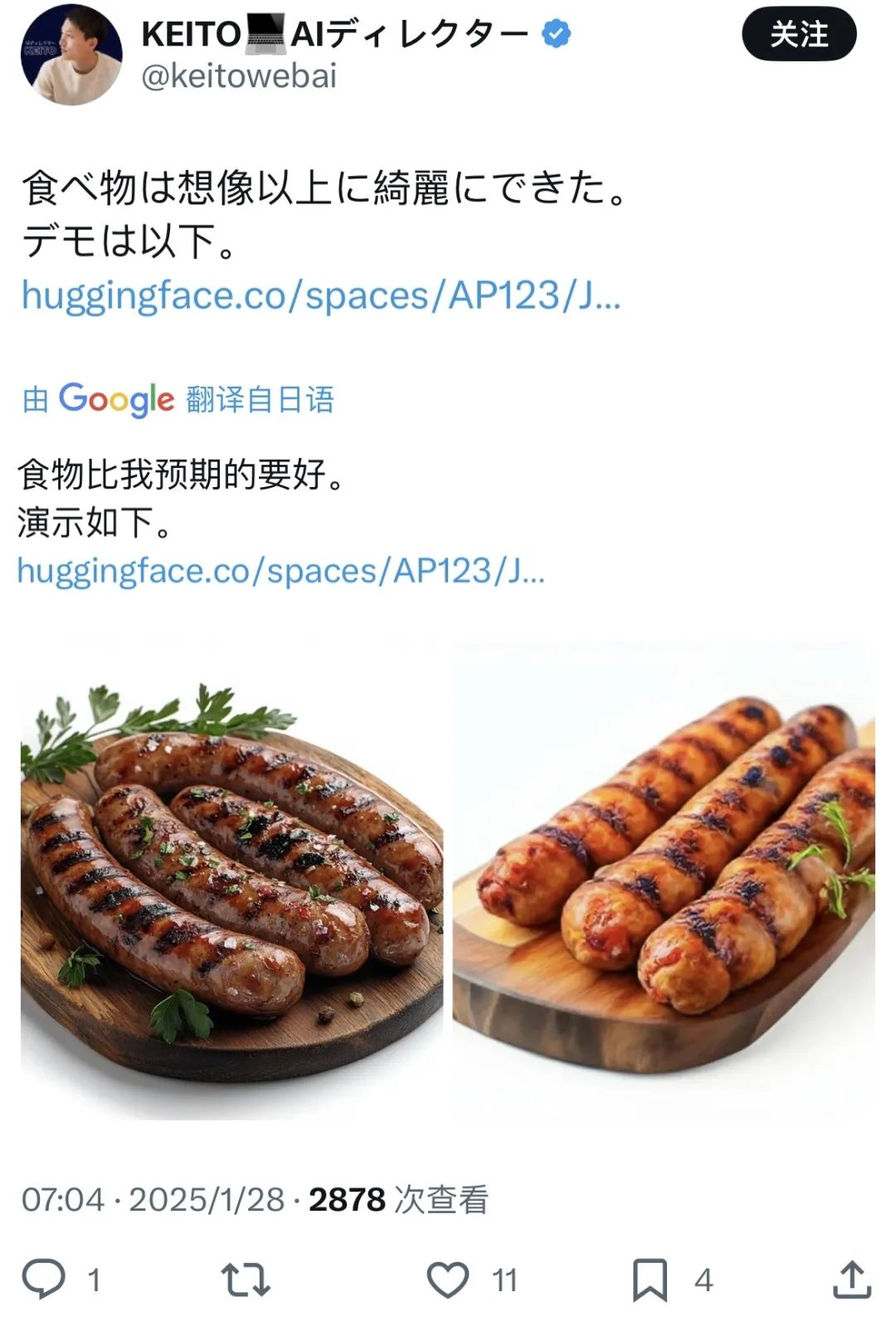
Но иногда случаются и сбои.
Обратившись к техническим документам по DeepSeekМы обнаружили, что Janus Pro - это оптимизация, основанная на Janus, который был выпущен три месяца назад.
Основная инновация этой серии моделей заключается в следующем разделить задачи на визуальное понимание и визуальное порождение, чтобы сбалансировать влияние этих двух задач.
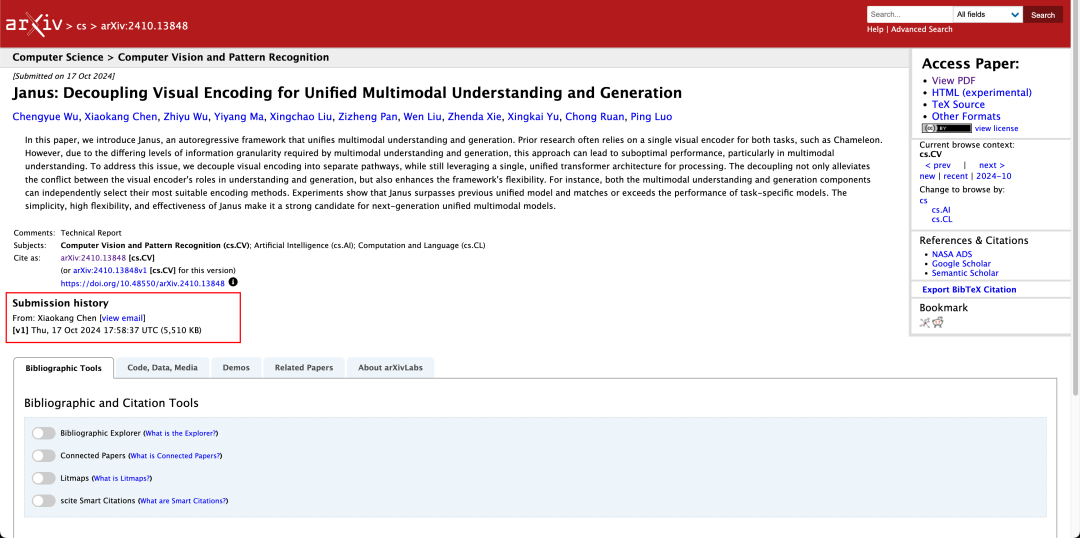
Нередко модель может одновременно выполнять мультимодальное понимание и генерацию. D-DiT и TokenFlow-XL в данном тестовом наборе обладают такой способностью.
Однако для Януса характерно то, что Разделяя обработку, модель, способная выполнять мультимодальное понимание и генерацию, уравновешивает эффективность двух задач.
Баланс между эффективностью этих двух задач - сложная проблема в индустрии. Ранее предполагалось использовать один и тот же кодировщик для реализации мультимодального понимания и генерации, насколько это возможно.
Преимущества такого подхода - простая архитектура, отсутствие избыточного развертывания и согласованность с текстовыми моделями (которые также используют те же методы для генерации и понимания текста). Еще один аргумент заключается в том, что такое слияние нескольких способностей может привести к определенной степени эмерджентности.
Однако на самом деле при объединении генерации и понимания эти две задачи будут противоречить друг другу: понимание изображения требует от модели абстрагирования в высоких измерениях и извлечения основной семантики изображения, что смещено в сторону макроскопичности. Генерация изображений, с другой стороны, сосредоточена на выражении и создании локальных деталей на уровне пикселей.
Обычная практика отрасли - отдавать предпочтение возможностям генерации изображений. Это приводит к появлению мультимодальных моделей, которые могут генерировать изображения более высокого качества, но результаты понимания изображений часто оказываются посредственными.
Развязанная архитектура Janus и оптимизированная стратегия обучения Janus-Pro
Раздельная архитектура Janus позволяет модели самостоятельно справляться с задачами понимания и генерации.
Согласно результатам, приведенным в официальном техническом отчете, независимо от того, идет ли речь о мультимодальном понимании или создании изображений, Janus-Pro-7B демонстрирует отличные результаты на нескольких тестовых наборах.

Для мультимодального понимания, Janus-Pro-7B заняла первое место в четырех из семи оценочных наборов данных и второе место в оставшихся трех, немного уступив модели, занявшей первое место.
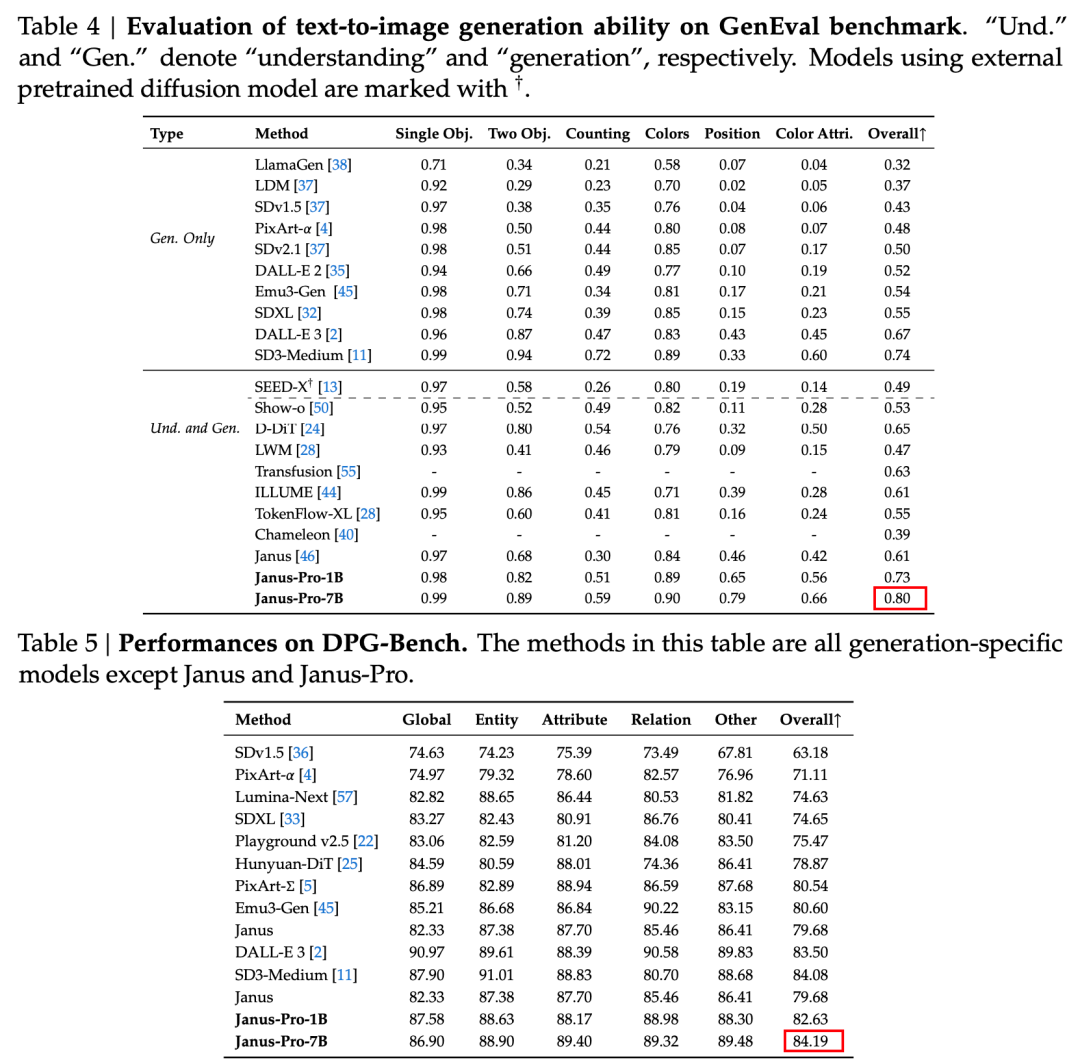
Для создания изображений, Janus-Pro-7B занял первое место в общем зачете как в наборе данных GenEval, так и в DPG-Bench.
Этот эффект многозадачности в основном связан с тем, что в серии Janus используются два визуальных кодировщика для разных задач:
- Понимание кодировщика: используется для извлечения семантических признаков из изображений для задач понимания изображений (таких как вопросы и ответы на изображения, визуальная классификация и т.д.).
- Генеративный кодировщик: преобразует изображения в дискретное представление (например, с помощью VQ-кодера) для задач преобразования текста в изображение.
С такой архитектурой, модель может независимо оптимизировать работу каждого кодера, чтобы мультимодальные задачи понимания и генерации достигали наилучшей производительности.
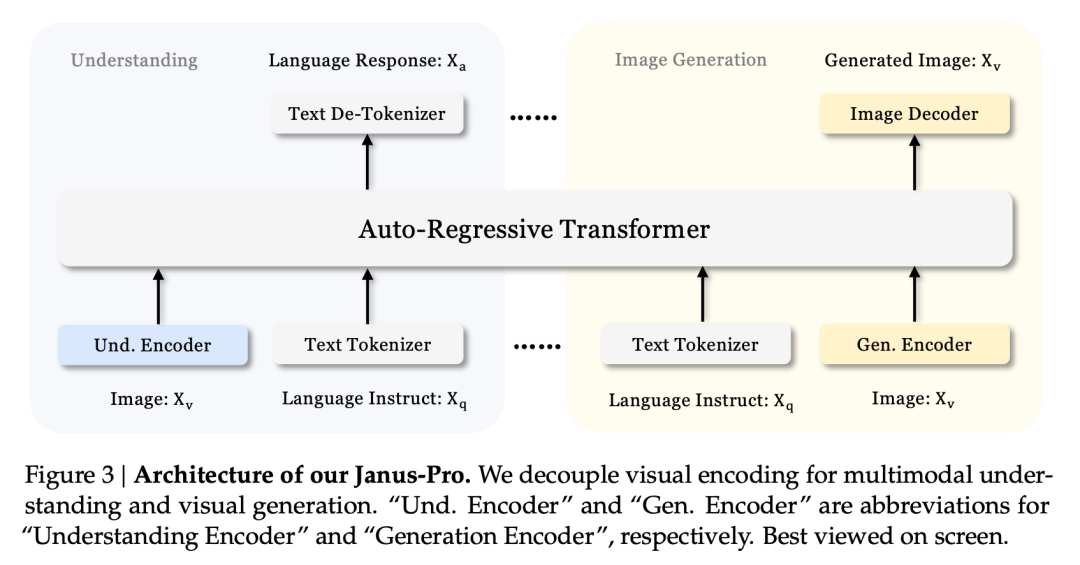
Такая раздельная архитектура характерна для Janus-Pro и Janus. Итак, какие итерации Janus-Pro прошли за последние несколько месяцев?
Как видно из результатов набора оценок, текущий выпуск Janus-Pro-1B имеет улучшение примерно от 10% до 20% в баллах различных наборов оценок по сравнению с предыдущим Janus. Janus-Pro-7B имеет наибольшее улучшение примерно на 45% по сравнению с Janus после расширения числа параметров.

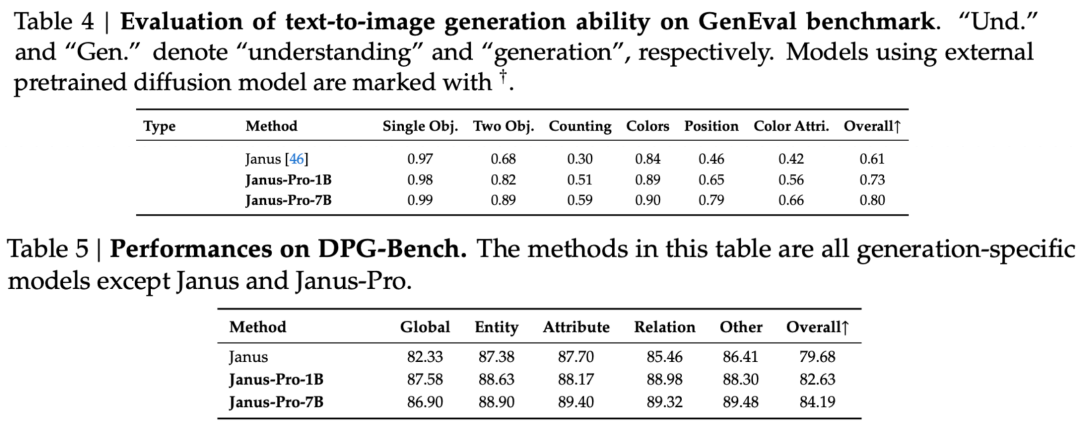
Что касается деталей обучения, то в техническом отчете говорится, что текущий выпуск Janus-Pro, по сравнению с предыдущей моделью Janus, сохраняет основной дизайн архитектуры с развязкой и дополнительно итерирует размер параметра, стратегия обучения и обучающие данные.
Сначала рассмотрим параметры.
Первая версия Janus имела всего 1,3B параметров, а текущий выпуск Pro включает модели с 1B и 7B параметрами.
Эти два размера отражают масштабируемость архитектуры Janus. Модель 1B, которая является самой легкой, уже использовалась внешними пользователями для запуска в браузере с помощью WebGPU.
Также есть сайт стратегия обучения.
В соответствии с разделением фаз обучения в Janus, Janus Pro имеет в общей сложности три фазы обучения, и в документе они непосредственно делятся на I, II и III стадии.
Сохранив основные идеи и цели обучения на каждом этапе, Janus-Pro внесла улучшения в продолжительность обучения и учебные данные на трех этапах. Ниже перечислены конкретные улучшения на трех этапах:
Этап I - более длительное время обучения
По сравнению с Janus, в Janus-Pro увеличено время обучения на первом этапе, особенно при обучении адаптеров и головок изображений в визуальной части. Это означает, что на обучение визуальным особенностям было выделено больше времени, и есть надежда, что модель сможет полностью понять детальные особенности изображений (например, семантическое сопоставление пикселей).
Такое расширенное обучение помогает гарантировать, что обучение визуальной части не будет нарушено другими модулями.
Этап II - удаление данных ImageNet и добавление мультимодальных данных
На втором этапе Janus предварительно обратился к PixArt и прошел обучение в двух частях. Первая часть обучалась на наборе данных ImageNet для задачи классификации изображений, а вторая часть - на обычных данных "текст-изображение". Примерно две трети времени на втором этапе было потрачено на обучение первой части.
Janus-Pro удаляет обучение ImageNet на втором этапе. Такая конструкция позволяет модели сфокусироваться на текстово-изобразительных данных во время II этапа обучения. Согласно экспериментальным результатам, это позволяет значительно улучшить использование текстово-изобразительных данных.
Помимо корректировки дизайна метода обучения, набор обучающих данных, используемый на втором этапе, больше не ограничивается задачей классификации одного изображения, а включает в себя больше других типов мультимодальных данных, таких как описание изображения и диалог, для совместного обучения.
Этап III - оптимизация соотношения данных
На третьем этапе обучения Janus-Pro регулирует соотношение различных типов обучающих данных.
Ранее соотношение данных мультимодального понимания, обычных текстовых данных и данных "текст-изображение" в обучающих данных, используемых Janus на III этапе, составляло 7:3:10. Janus-Pro уменьшает соотношение двух последних типов данных и корректирует соотношение трех типов данных до 5:1:4, то есть уделяет больше внимания задаче мультимодального понимания.
Давайте посмотрим на учебные данные.
По сравнению с Janus, Janus-Pro на этот раз значительно увеличивает количество высококачественных синтетические данные.
Это расширяет количество и разнообразие обучающих данных для мультимодального понимания и создания изображений.
Расширение мультимодальных данных о понимании:
Janus-Pro обращается к набору данных DeepSeek-VL2 во время обучения и добавляет около 90 миллионов дополнительных точек данных, включая не только наборы данных описания изображений, но и наборы данных сложных сцен, таких как таблицы, диаграммы и документы.
На этапе тонкой настройки под наблюдением (этап III) продолжается добавление наборов данных, связанных с пониманием MEME и улучшением опыта ведения диалога (включая китайский диалог).
Расширение данных визуальной генерации:
Исходные данные реального мира имели низкое качество и высокий уровень шума, из-за чего модель выдавала нестабильные результаты и изображения недостаточного эстетического качества в задачах преобразования текста в изображение.
Janus-Pro добавила около 72 миллионов новых высокоэстетичных синтетических данных в фазу обучения, доведя соотношение реальных и синтетических данных в фазе предварительного обучения до 1:1.
Все подсказки для синтетических данных были взяты из открытых источников. Эксперименты показали, что добавление этих данных ускоряет сходимость модели, а сгенерированные изображения имеют очевидные улучшения в стабильности и визуальной красоте.
Продолжение революции эффективности?
В целом, благодаря этому выпуску DeepSeek совершила революцию в эффективности визуальных моделей.
В отличие от визуальных моделей, которые фокусируются на одной функции, или мультимодальных моделей, которые отдают предпочтение конкретной задаче, Janus-Pro балансирует эффекты двух основных задач генерации изображений и мультимодального понимания в одной модели.
Более того, несмотря на небольшие параметры, он обошел в оценке OpenAI DALL-E 3 и SD3-Medium.
Если развернуть модель на земле, то предприятию достаточно развернуть ее для непосредственной реализации двух функций - формирования и понимания изображений. В сочетании с размером всего 7 ББ сложность и стоимость развертывания значительно ниже.
В связи с предыдущими релизами R1 и V3 компания DeepSeek бросает вызов существующим правилам игры, предлагая "компактные архитектурные инновации, легкие модели, модели с открытым исходным кодом и сверхнизкая стоимость обучения".. Именно это стало причиной паники среди западных технологических гигантов и даже на Уолл-стрит.
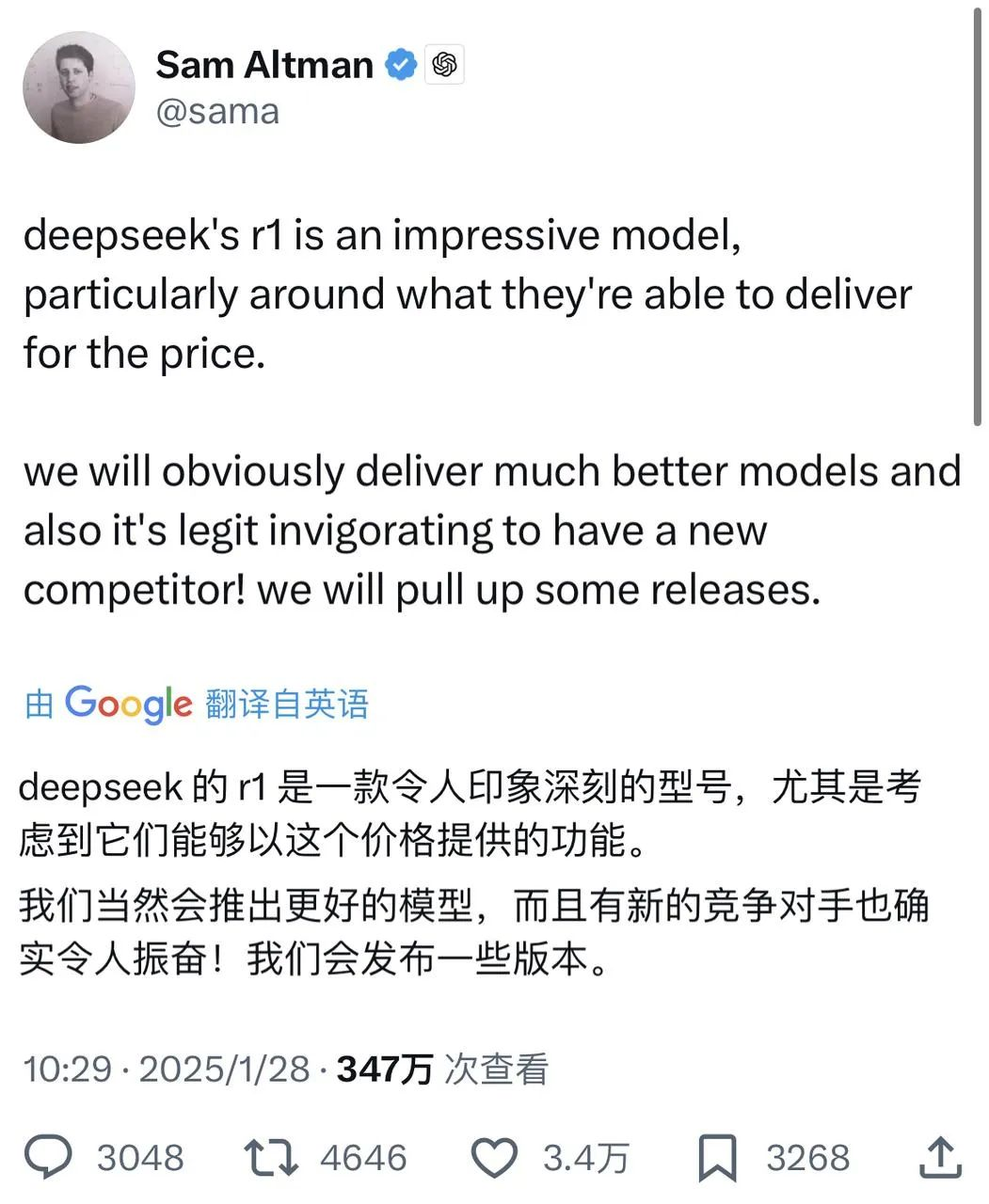
Только что Сэм Альтман, которого общественное мнение подхлестывало в течение нескольких дней, наконец-то положительно отреагировал на информацию о DeepSeek на X - похвалив R1, он сказал, что OpenAI сделает несколько анонсов.