عشية مهرجان الربيع، تم إصدار طراز DeepSeek-R1. بفضل بنية RL الخالصة، فقد استفاد من ابتكارات CoT العظيمة، وتفوق في أدائه على دردشةGPT في الرياضيات والرموز والاستدلال المنطقي.
بالإضافة إلى ذلك، فإن أوزان نماذجها مفتوحة المصدر، وتكاليف التدريب المنخفضة، وأسعار واجهة برمجة التطبيقات الرخيصة جعلت من DeepSeek نجاحًا كبيرًا عبر الإنترنت، حتى أنها تسببت في انخفاض أسعار أسهم NVIDIA وASML لبعض الوقت.
في الوقت الذي تتزايد فيه شعبية DeepSeek، أصدرت أيضًا نسخة محدثة من النموذج الكبير متعدد الوسائط Janus (Janus)، Janus-Pro، الذي يرث البنية الموحدة للجيل السابق من الفهم والتوليد متعدد الوسائط، ويحسن استراتيجية التدريب، ويزيد من حجم بيانات التدريب وحجم النموذج، مما يحقق أداءً أقوى.

Janus-Pro
Janus-Pro هو نموذج لغوي موحد متعدد الوسائط (MLLM) يمكنه معالجة مهام الفهم متعدد الوسائط ومهام التوليد في آنٍ واحد، أي يمكنه فهم محتوى الصورة وتوليد النص أيضًا.
يفصل بين المشفرات البصرية للفهم والتوليد متعدد الوسائط (أي يتم استخدام رموز مختلفة لمدخلات فهم الصور ومدخلات ومخرجات توليد الصور)، ويعالجها باستخدام محول انحداري ذاتي موحد.
وباعتباره نموذجاً متقدماً متعدد الوسائط للفهم والتوليد فهو نسخة مطورة من نموذج جانوس السابق.
في الميثولوجيا الرومانية، جانوس (جانوس) هو إله حارس ذو وجهين يرمز إلى التناقض والانتقال. له وجهان، وهو ما يشير أيضًا إلى أن نموذج يانوس يمكنه فهم وتوليد الصور، وهو أمر مناسب جدًا. إذن ما الذي قام بترقية برو بالضبط؟
Janus، كنموذج صغير من 1.3B، هو أشبه بنسخة معاينة أكثر من كونه نسخة رسمية. إنه يستكشف الفهم والتوليد الموحد متعدد الوسائط، ولكن لديه العديد من المشاكل، مثل تأثيرات توليد الصور غير المستقرة، والانحرافات الكبيرة عن تعليمات المستخدم، وعدم كفاية التفاصيل.
يعمل الإصدار Pro على تحسين استراتيجية التدريب، وزيادة مجموعة بيانات التدريب، وتوفير نموذج أكبر (7B) للاختيار من بينها مع توفير نموذج 1B.
نموذج الهندسة المعمارية
جوس-برو وجانوس متطابقة من حيث بنية النموذج. (فقط 1.3 ب! يوحد جانوس الفهم والتوليد متعدد الوسائط)
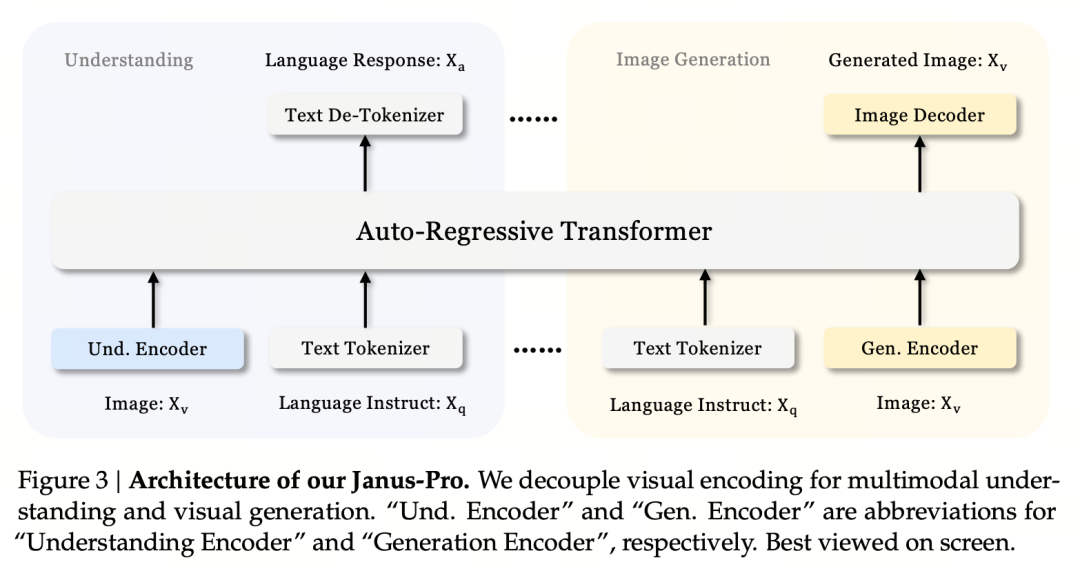
مبدأ التصميم الأساسي هو فصل الترميز البصري لدعم الفهم والتوليد متعدد الوسائط. يقوم Janus-Pro بترميز مدخلات الصورة/النص الأصلي بشكل منفصل، ويستخرج السمات عالية الأبعاد، ويعالجها من خلال محول انحداري ذاتي موحد.
يستخدم فهم الصور متعدد الوسائط SigLIP لترميز ميزات الصورة (المشفر الأزرق في الشكل أعلاه)، وتستخدم مهمة التوليد أداة ترميز VQ لترميز الصورة (المشفر الأصفر في الشكل أعلاه). أخيرًا، يتم إدخال جميع تسلسلات الميزات إلى LLM للمعالجة
استراتيجية التدريب
من حيث استراتيجية التدريب، أدخلت Janus-Pro المزيد من التحسينات. استخدم الإصدار القديم من Janus استراتيجية تدريب من ثلاث مراحل، حيث تقوم المرحلة الأولى بتدريب محول الإدخال ورأس توليد الصورة لفهم الصورة وتوليد الصورة، وتقوم المرحلة الثانية بإجراء تدريب مسبق موحد، وتقوم المرحلة الثالثة بضبط مشفر الفهم على هذا الأساس. (تظهر استراتيجية تدريب جانوس في الشكل أدناه).
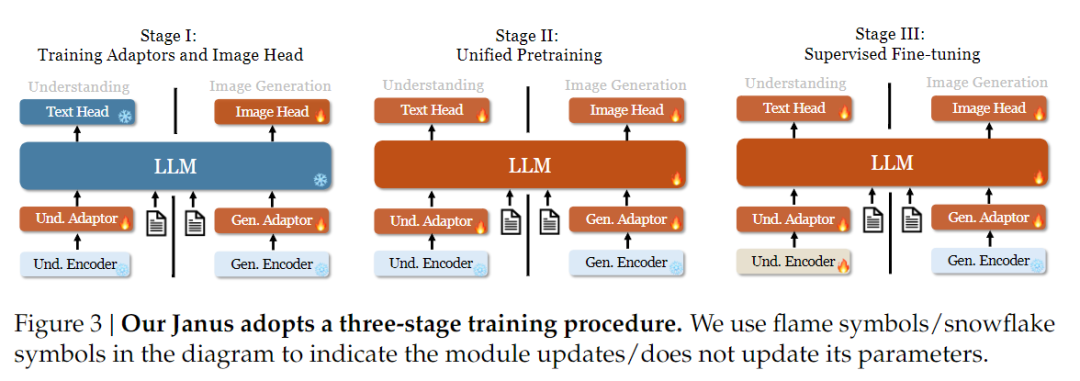
ومع ذلك، تستخدم هذه الاستراتيجية طريقة PixArt لتقسيم تدريب توليد النص إلى صورة في المرحلة الثانية، مما يؤدي إلى انخفاض الكفاءة الحسابية.
تحقيقًا لهذه الغاية، قمنا بتمديد وقت التدريب في المرحلة الأولى وأضفنا التدريب باستخدام بيانات ImageNet، بحيث يمكن للنموذج أن يصمم بفعالية تبعيات البكسل مع معلمات LLM ثابتة. في المرحلة الثانية، تخلصنا من بيانات ImageNet واستخدمنا بيانات زوج النصوص والصور مباشرةً للتدريب، مما يحسن من كفاءة التدريب. بالإضافة إلى ذلك، قمنا بتعديل نسبة البيانات في المرحلة الثالثة (بيانات الرسم البياني متعدد الوسائط: النصية فقط: بيانات الرسم البياني المرئي الدلالي من 7:3:10 إلى 5:1:4)، مما أدى إلى تحسين الفهم متعدد الوسائط مع الحفاظ على قدرات التوليد المرئي.
تحجيم بيانات التدريب
Janus-Pro أيضًا قياس بيانات التدريب الخاصة بـ Janus من حيث الفهم متعدد الوسائط والتوليد البصري.
الفهم متعدد الوسائط: تعتمد بيانات المرحلة الثانية من التدريب المسبق على بيانات المرحلة الثانية من التدريب المسبق على DeepSeek-VL2 وتتضمن حوالي 90 مليون عينة جديدة، بما في ذلك بيانات شرح الصور (مثل YFCC) وبيانات فهم الجداول والرسوم البيانية والمستندات (مثل Docmatix).
تُدخل مرحلة الضبط الدقيق الخاضع للإشراف في المرحلة الثالثة مزيدًا من الفهم الدقيق لمفهوم MEME وبيانات الحوار الصيني وما إلى ذلك، لتحسين أداء النموذج في المعالجة متعددة المهام وقدرات الحوار.
التوليد المرئي: استخدمت الإصدارات السابقة بيانات حقيقية ذات جودة منخفضة وضوضاء عالية، مما أثر على ثبات وجماليات الصور التي تم إنشاؤها بالنص.
Janus-Pro يقدم حوالي 72 مليون بيانات جمالية تركيبية، مما يجعل نسبة البيانات الحقيقية إلى البيانات التركيبية تصل إلى 1:1. وقد أظهرت التجارب أن البيانات الاصطناعية تسرّع من تقارب النماذج وتحسّن بشكل كبير من ثبات الصور المولّدة وجودتها الجمالية.
تحجيم النموذج
Janus Pro يوسع حجم النموذج إلى 7B، بينما استخدم الإصدار السابق من Janus 1.5B DeepSeek-LLM للتحقق من فعالية فصل الترميز البصري. تُظهر التجارب أن حجم LLM الأكبر يُسرّع بشكل كبير من تقارب الفهم متعدد الوسائط والتوليد البصري، مما يؤكد بشكل أكبر قابلية التوسع القوية للطريقة.

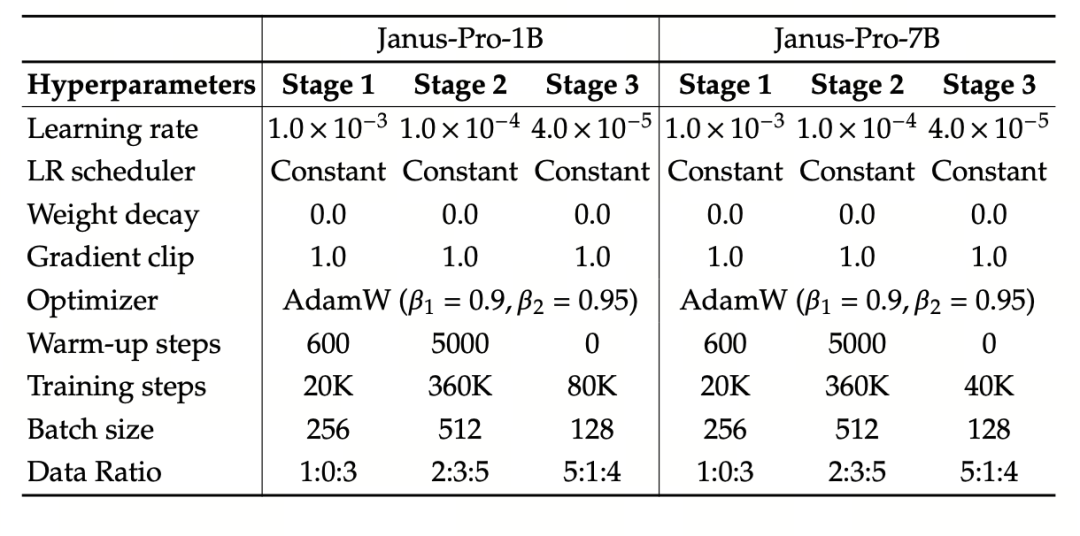
تستخدم التجربة نموذج DeepSeek-LLM (1.5B و7B، يدعم تسلسلًا بحد أقصى 4096) كنموذج لغوي أساسي. بالنسبة لمهمة الفهم متعدد الوسائط، يتم استخدام SigLIP-Large-Patch16-384 كنموذج تشفير مرئي، وحجم قاموس المشفر 16384، ومضاعف تخفيض عينات الصورة 16، وكل من محولات الفهم والتوليد عبارة عن محولات متعددة الطبقات.
يستخدم التدريب في المرحلة الثانية استراتيجية التوقف المبكر 270K، ويتم ضبط جميع الصور بشكل موحد على دقة 384×384، ويتم استخدام تغليف التسلسل لتحسين كفاءة التدريب . تم تدريب Janus-Pro وتقييمه باستخدام HAI-LLM. تم تدريب الإصدارين 1.5B/7B على 16/32 عقدة (8×Nvidia A100 40GB لكل عقدة) لمدة 9/14 يومًا على التوالي.
تقييم النموذج
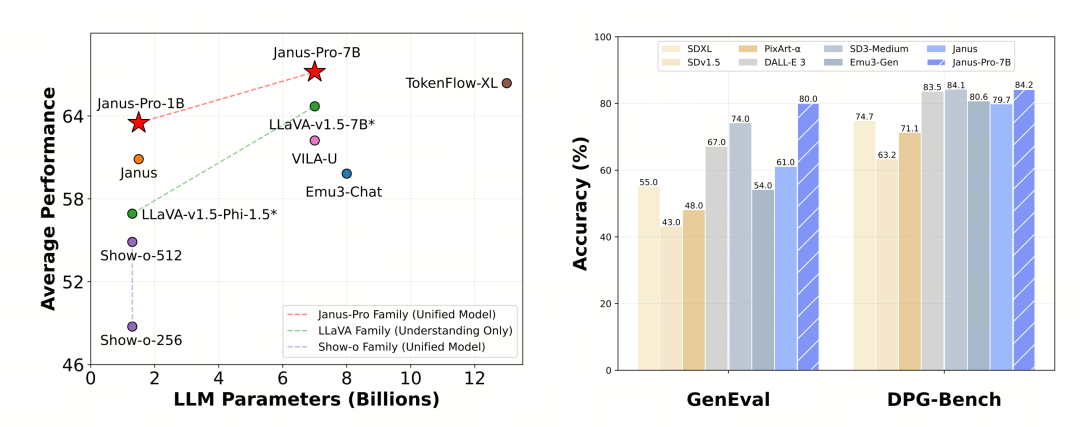
تم تقييم Janus-Pro بشكل منفصل في الفهم والتوليد متعدد الوسائط. بشكل عام، قد يكون الفهم ضعيفًا بعض الشيء، لكنه يعتبر ممتازًا بين النماذج مفتوحة المصدر من نفس الحجم (أعتقد أنه محدود إلى حد كبير بسبب دقة الإدخال الثابتة وقدرات التعرف الضوئي على الحروف).
سجل Janus-Pro-7B 79.2 نقطة في اختبار MMBench القياسي، وهو قريب من مستوى النماذج مفتوحة المصدر من الدرجة الأولى (نفس حجم InternVL2.5 وQwen2-VL حوالي 82 نقطة). ومع ذلك، فهو تحسن جيد عن الجيل السابق من Janus.
أما فيما يتعلق بتوليد الصور، فإن التحسن مقارنة بالجيل السابق أكثر أهمية، ويعتبر مستوى ممتازًا بين النماذج مفتوحة المصدر. كما تتفوق درجة Janus-Pro في اختبار GenEval المعياري (0.80) على نماذج مثل DALL-E 3 (0.67) و Stable Diffusion 3 Medium (0.74).