O DeepSeek atualizou seu site.
Nas primeiras horas da véspera de Ano Novo, a DeepSeek anunciou repentinamente no GitHub que o espaço do projeto Janus havia aberto a fonte do modelo Janus-Pro e do relatório técnico.
Primeiro, vamos destacar alguns pontos-chave:
- O Modelo Janus-Pro lançado desta vez é um modelo multimodal que pode executar simultaneamente tarefas de compreensão multimodal e geração de imagens. Ele tem um total de duas versões de parâmetros, Janus-Pro-1B e Janus-Pro-7B.
- A principal inovação do Janus-Pro é desacoplar compreensão e geração multimodal, duas tarefas diferentes. Isso permite que essas duas tarefas sejam concluídas com eficiência no mesmo modelo.
- O Janus-Pro é consistente com a arquitetura do modelo Janus lançado pela DeepSeek em outubro passado, mas naquela época o Janus não tinha muito volume. O Dr. Charles, um especialista em algoritmos no campo da visão, nos disse que o Janus anterior era "mediano" e "não tão bom quanto o modelo de linguagem do DeepSeek".

Seu objetivo é resolver o difícil problema do setor: equilibrar a compreensão multimodal e a geração de imagens
De acordo com a introdução oficial do DeepSeek, Janus-Pro pode não apenas entender imagens, extrair e entender o texto nas imagens, mas também gerar imagens ao mesmo tempo.
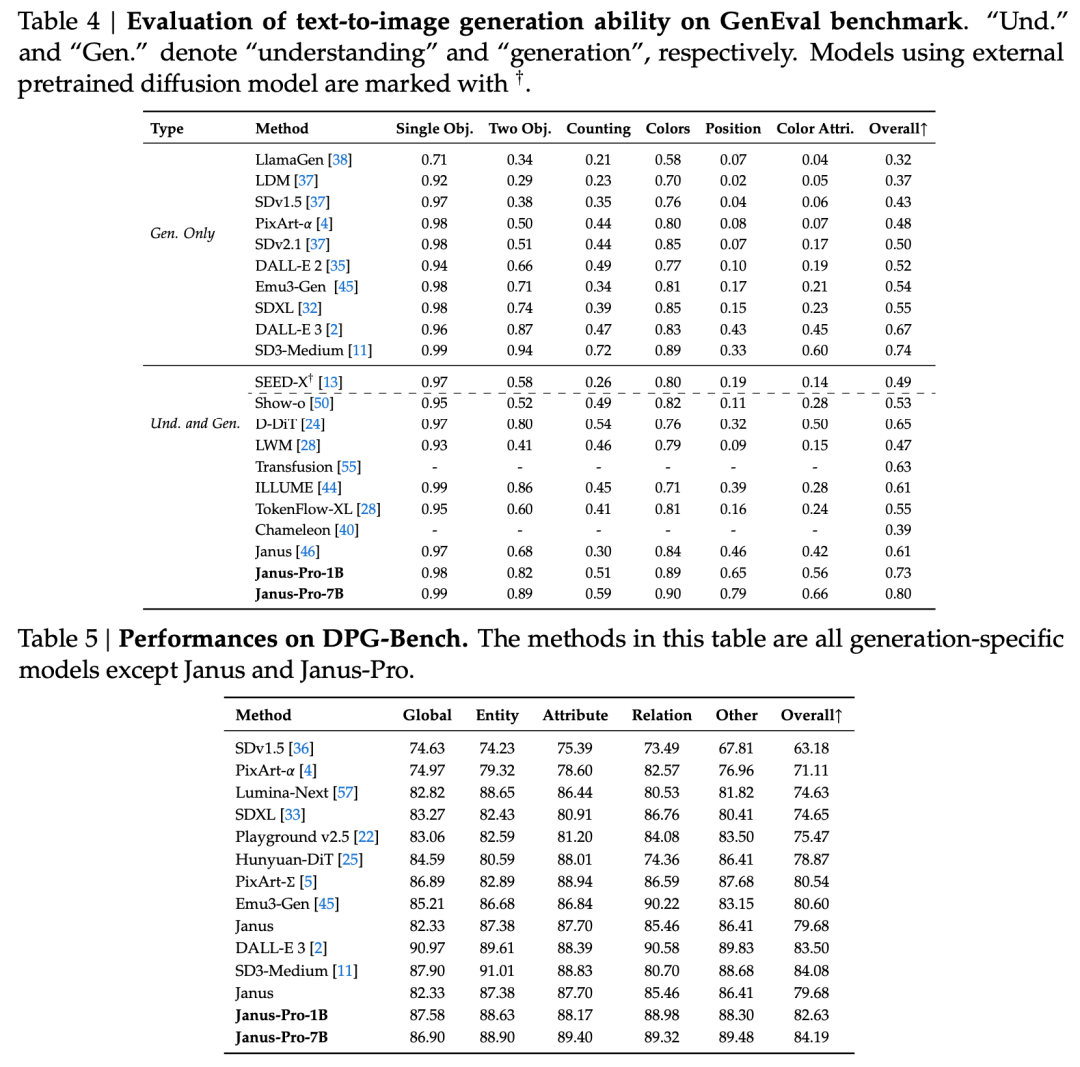
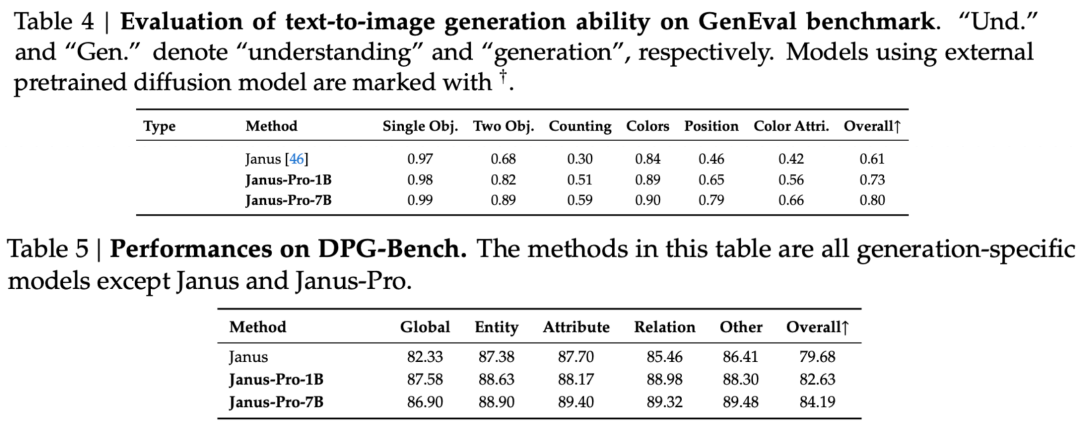
O relatório técnico menciona que, em comparação com outros modelos do mesmo tipo e ordem de magnitude, as pontuações do Janus-Pro-7B nos conjuntos de testes GenEval e DPG-Bench superam as de outros modelos, como o SD3-Medium e o DALL-E 3.
O funcionário também dá exemplos 👇:
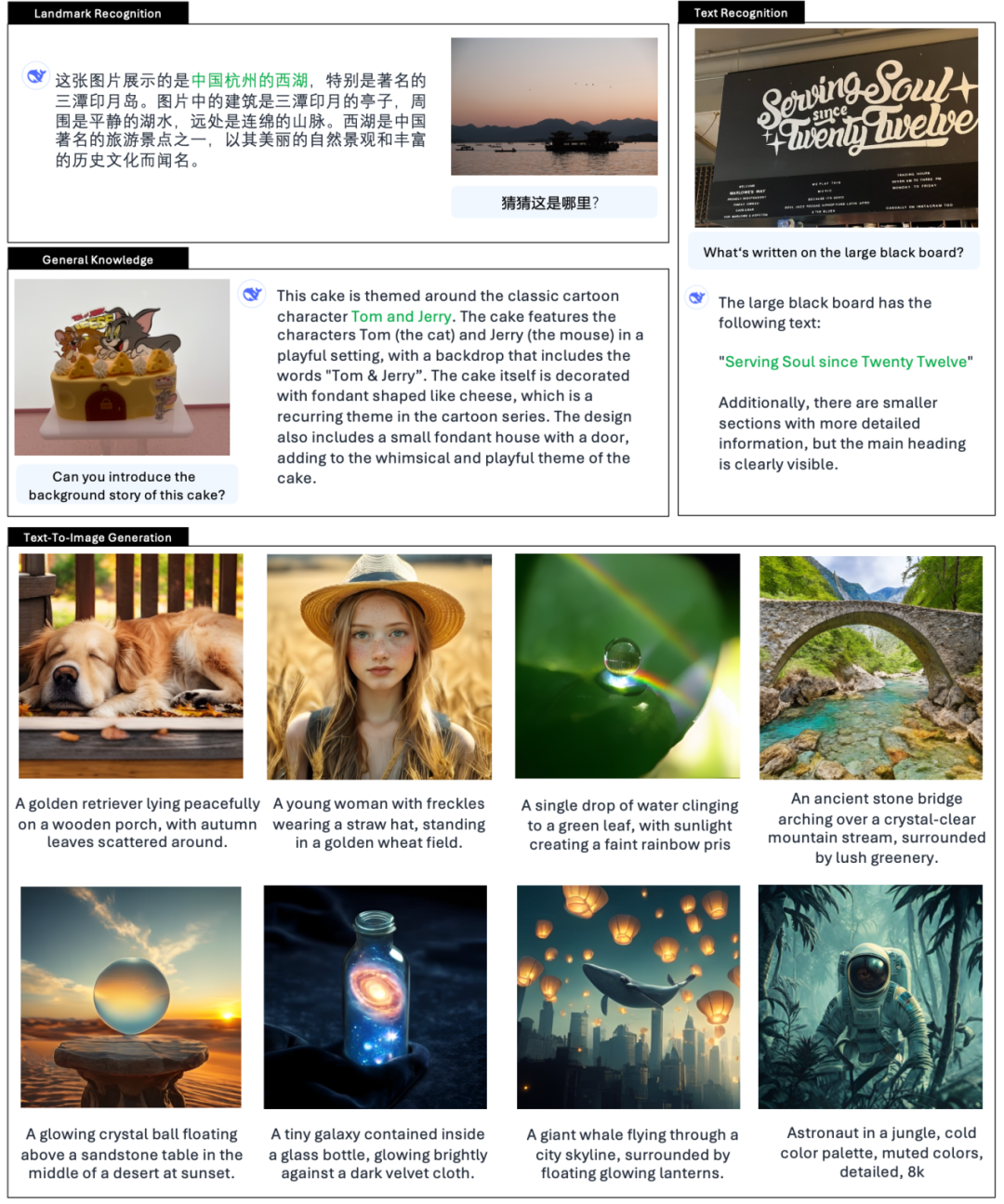
Também há muitos internautas no X testando os novos recursos.

Mas também há falhas ocasionais.
Ao consultar os documentos técnicos sobre DeepSeekEm uma pesquisa de mercado, descobrimos que o Janus Pro é uma otimização baseada no Janus, que foi lançado há três meses.
A principal inovação dessa série de modelos é dissociar as tarefas de compreensão visual das tarefas de geração visual, de modo que os efeitos das duas tarefas possam ser equilibrados.
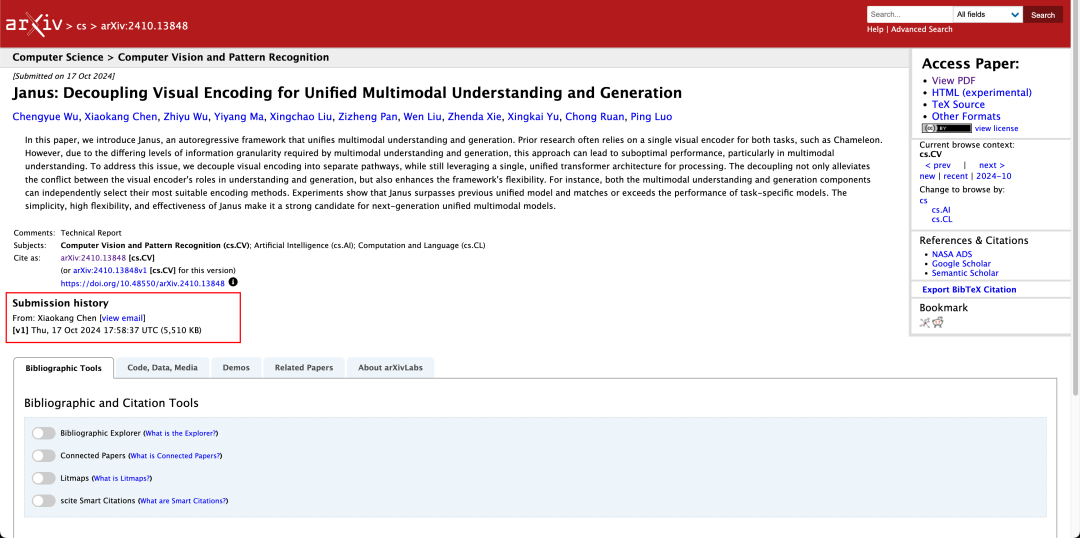
Não é incomum que um modelo realize a compreensão e a geração multimodais ao mesmo tempo. O D-DiT e o TokenFlow-XL nesse conjunto de testes têm essa capacidade.
Entretanto, o que é característico da Janus é que Ao desacoplar o processamento, um modelo que pode realizar a compreensão e a geração multimodais equilibra a eficácia das duas tarefas.
Equilibrar a eficácia das duas tarefas é um problema difícil no setor. Anteriormente, a ideia era usar o mesmo codificador para implementar a compreensão e a geração multimodais o máximo possível.
As vantagens dessa abordagem são uma arquitetura simples, nenhuma implementação redundante e um alinhamento com os modelos de texto (que também usam os mesmos métodos para gerar e entender o texto). Outro argumento é que essa fusão de várias habilidades pode levar a um certo grau de emergência.
No entanto, de fato, após a fusão da geração e da compreensão, as duas tarefas entrarão em conflito - a compreensão da imagem exige que o modelo abstraia em altas dimensões e extraia a semântica central da imagem, que é tendenciosa para o macroscópico. A geração de imagens, por outro lado, concentra-se na expressão e na geração de detalhes locais no nível do pixel.
A prática usual do setor é priorizar os recursos de geração de imagens. Isso resulta em modelos multimodais que podem gerar imagens de alta qualidade, mas os resultados da compreensão da imagem geralmente são medíocres.
A arquitetura desacoplada do Janus e a estratégia de treinamento otimizada do Janus-Pro
A arquitetura desacoplada do Janus permite que o modelo equilibre as tarefas de compreensão e geração por conta própria.
De acordo com os resultados do relatório técnico oficial, seja na compreensão multimodal ou na geração de imagens, o Janus-Pro-7B tem um bom desempenho em vários conjuntos de testes.

Para compreensão multimodal, O Janus-Pro-7B alcançou o primeiro lugar em quatro dos sete conjuntos de dados de avaliação e o segundo lugar nos três restantes, um pouco atrás do modelo mais bem classificado.
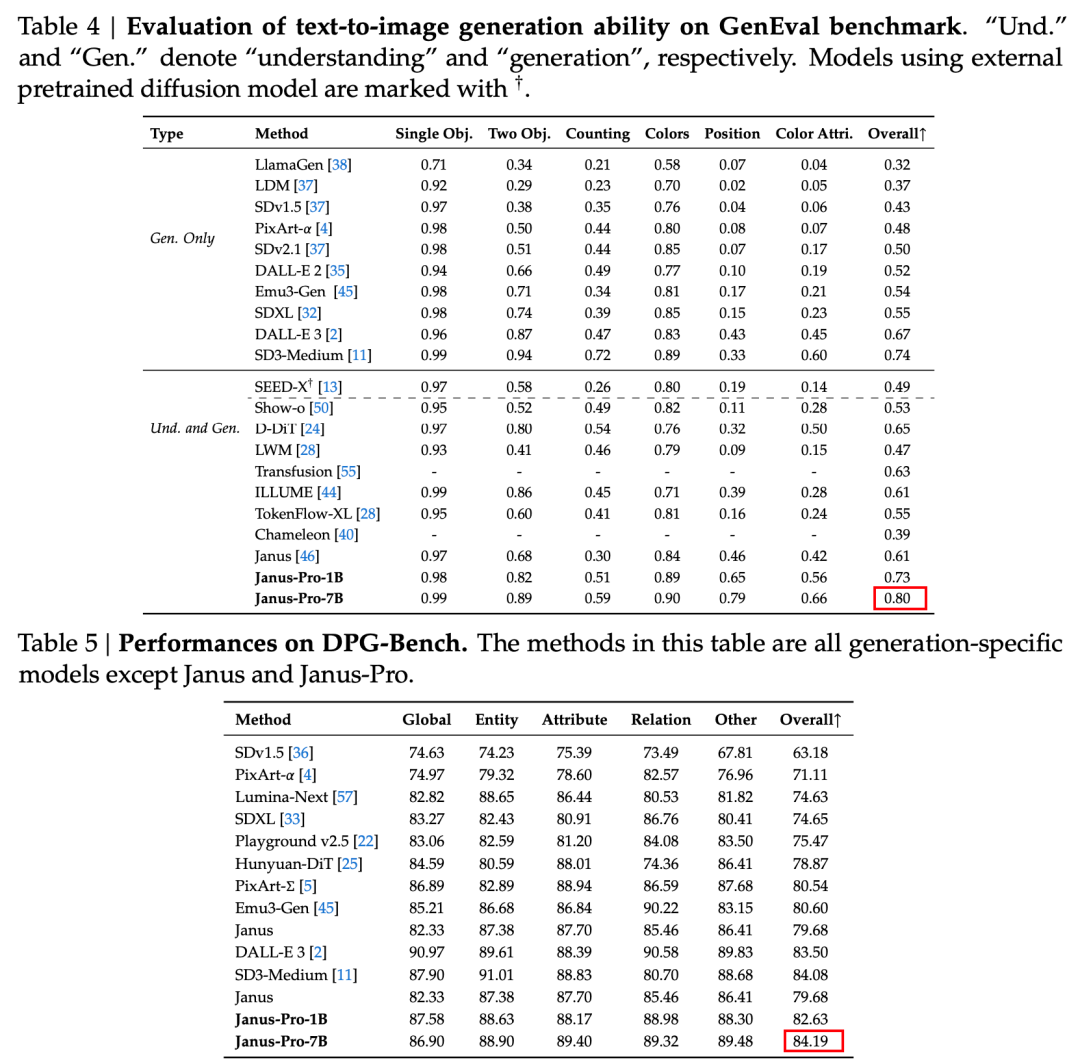
Para geração de imagens, O Janus-Pro-7B obteve o primeiro lugar na pontuação geral nos conjuntos de dados de avaliação GenEval e DPG-Bench.
Esse efeito multitarefa se deve principalmente ao fato de a série Janus usar dois codificadores visuais para tarefas diferentes:
- Compreensão do codificador: usado para extrair recursos semânticos em imagens para tarefas de compreensão de imagens (como perguntas e respostas sobre imagens, classificação visual etc.).
- Codificador generativo: converte imagens em uma representação discreta (por exemplo, usando um codificador VQ) para tarefas de geração de texto para imagem.
Com essa arquitetura, o modelo pode otimizar de forma independente o desempenho de cada codificador, de modo que as tarefas de compreensão e geração multimodais possam atingir seu melhor desempenho.
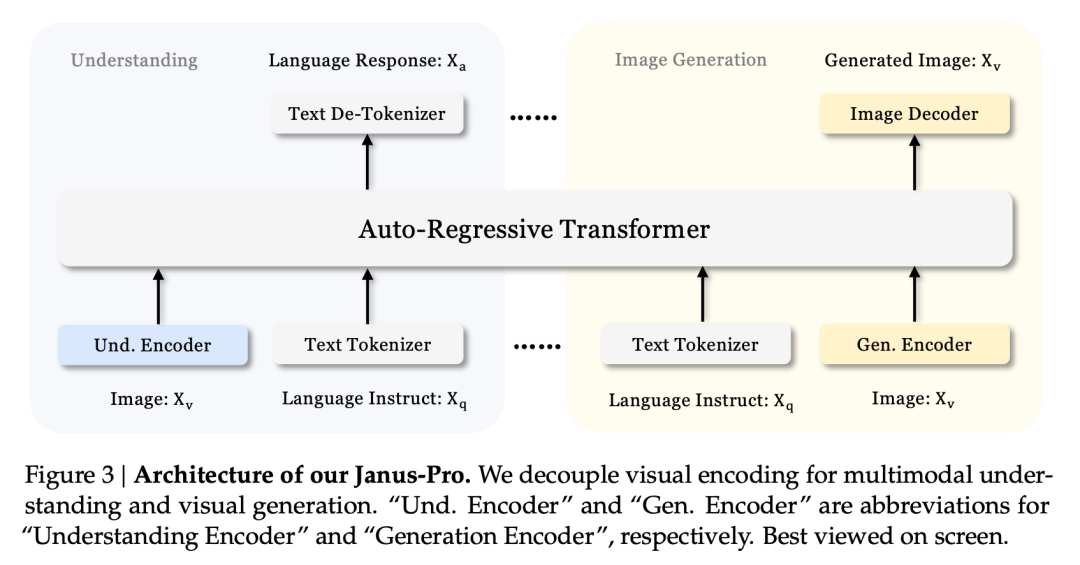
Essa arquitetura desacoplada é comum ao Janus-Pro e ao Janus. Então, quais iterações o Janus-Pro teve nos últimos meses?
Como pode ser visto nos resultados do conjunto de avaliação, a versão atual do Janus-Pro-1B tem uma melhoria de cerca de 10% a 20% nas pontuações de diferentes conjuntos de avaliação em comparação com o Janus anterior. O Janus-Pro-7B tem a maior melhoria de cerca de 45% em comparação com o Janus depois de expandir o número de parâmetros.

Em termos de detalhes de treinamento, o relatório técnico afirma que a versão atual do Janus-Pro, em comparação com o modelo Janus anterior, mantém o design da arquitetura principal desacoplada e, além disso, itera sobre tamanho do parâmetro, estratégia de treinamento e dados de treinamento.
Primeiro, vamos dar uma olhada nos parâmetros.
A primeira versão do Janus tinha apenas 1,3B parâmetros, e a versão atual do Pro inclui modelos com 1B e 7B parâmetros.
Esses dois tamanhos refletem a escalabilidade da arquitetura Janus. O modelo 1B, que é o mais leve, já foi usado por usuários externos para execução no navegador usando WebGPU.
Há também o estratégia de treinamento.
De acordo com a divisão da fase de treinamento do Janus, o Janus Pro tem um total de três fases de treinamento, e o documento as divide diretamente em Estágio I, Estágio II e Estágio III.
Embora tenha mantido as ideias e os objetivos básicos de treinamento de cada fase, o Janus-Pro aprimorou a duração e os dados de treinamento nas três fases. Veja a seguir os aprimoramentos específicos nas três fases:
Estágio I - Tempo de treinamento mais longo
Em comparação com o Janus, o Janus-Pro estendeu o tempo de treinamento no Estágio I, especialmente no treinamento de adaptadores e cabeças de imagem na parte visual. Isso significa que o aprendizado de recursos visuais recebeu mais tempo de treinamento, e espera-se que o modelo possa compreender totalmente os recursos detalhados das imagens (como o mapeamento de pixel para semântica).
Esse treinamento estendido ajuda a garantir que o treinamento da parte visual não seja prejudicado por outros módulos.
Estágio II - Remoção dos dados do ImageNet e adição de dados multimodais
No Estágio II, Janus fez referência prévia ao PixArt e treinou em duas partes. A primeira parte foi treinada usando o conjunto de dados ImageNet para a tarefa de classificação de imagens, e a segunda parte foi treinada usando dados regulares de texto para imagem. Cerca de dois terços do tempo no Estágio II foram gastos no treinamento da primeira parte.
O Janus-Pro remove o treinamento do ImageNet no Estágio II. Esse design permite que o modelo se concentre nos dados de texto para imagem durante o treinamento do Estágio II. De acordo com os resultados experimentais, isso pode melhorar significativamente a utilização de dados de texto para imagem.
Além do ajuste do design do método de treinamento, o conjunto de dados de treinamento usado no Estágio II não está mais limitado a uma única tarefa de classificação de imagem, mas também inclui mais outros tipos de dados multimodais, como descrição de imagem e diálogo, para treinamento conjunto.
Estágio III - Otimização da relação de dados
No treinamento do Estágio III, o Janus-Pro ajusta a proporção de diferentes tipos de dados de treinamento.
Anteriormente, a proporção de dados de compreensão multimodal, dados de texto simples e dados de texto para imagem nos dados de treinamento usados pelo Janus no Estágio III era de 7:3:10. O Janus-Pro reduz a proporção dos dois últimos tipos de dados e ajusta a proporção dos três tipos de dados para 5:1:4, ou seja, dando mais atenção à tarefa de compreensão multimodal.
Vamos dar uma olhada nos dados de treinamento.
Em comparação com o Janus, o Janus-Pro dessa vez aumenta significativamente a quantidade de produtos de alta qualidade. dados sintéticos.
Ele amplia a quantidade e a variedade de dados de treinamento para compreensão multimodal e geração de imagens.
Expansão dos dados de compreensão multimodal:
O Janus-Pro refere-se ao conjunto de dados DeepSeek-VL2 durante o treinamento e acrescenta cerca de 90 milhões de pontos de dados adicionais, incluindo não apenas conjuntos de dados de descrição de imagens, mas também conjuntos de dados de cenas complexas, como tabelas, gráficos e documentos.
Durante o estágio de ajuste fino supervisionado (Estágio III), ele continua a adicionar conjuntos de dados relacionados à compreensão do MEME e ao aprimoramento da experiência de diálogo (incluindo o diálogo em chinês).
Expansão dos dados de geração visual:
Os dados originais do mundo real tinham baixa qualidade e altos níveis de ruído, o que fazia com que o modelo produzisse resultados instáveis e imagens de qualidade estética insuficiente em tarefas de texto para imagem.
O Janus-Pro adicionou cerca de 72 milhões de novos dados sintéticos altamente estéticos à fase de treinamento, elevando a proporção de dados reais para dados sintéticos na fase de pré-treinamento para 1:1.
Os prompts para os dados sintéticos foram todos retirados de recursos públicos. Os experimentos mostraram que a adição desses dados faz o modelo convergir mais rapidamente, e as imagens geradas apresentam melhorias óbvias em termos de estabilidade e beleza visual.
A continuação de uma revolução de eficiência?
Em geral, com esse lançamento, o DeepSeek trouxe a revolução da eficiência para os modelos visuais.
Diferentemente dos modelos visuais que se concentram em uma única função ou dos modelos multimodais que favorecem uma tarefa específica, o Janus-Pro equilibra os efeitos das duas principais tarefas de geração de imagens e compreensão multimodal no mesmo modelo.
Além disso, apesar de seus parâmetros pequenos, ele superou o OpenAI DALL-E 3 e o SD3-Medium na avaliação.
Estendida ao solo, a empresa só precisa implantar um modelo para implementar diretamente as duas funções de geração e compreensão de imagens. Juntamente com um tamanho de apenas 7B, a dificuldade e o custo da implementação são muito menores.
Em conexão com os lançamentos anteriores de R1 e V3, a DeepSeek está desafiando as regras existentes do jogo com "inovação arquitetônica compacta, modelos leves, modelos de código aberto e custos de treinamento ultrabaixos". Esse é o motivo do pânico entre os gigantes ocidentais da tecnologia e até mesmo em Wall Street.
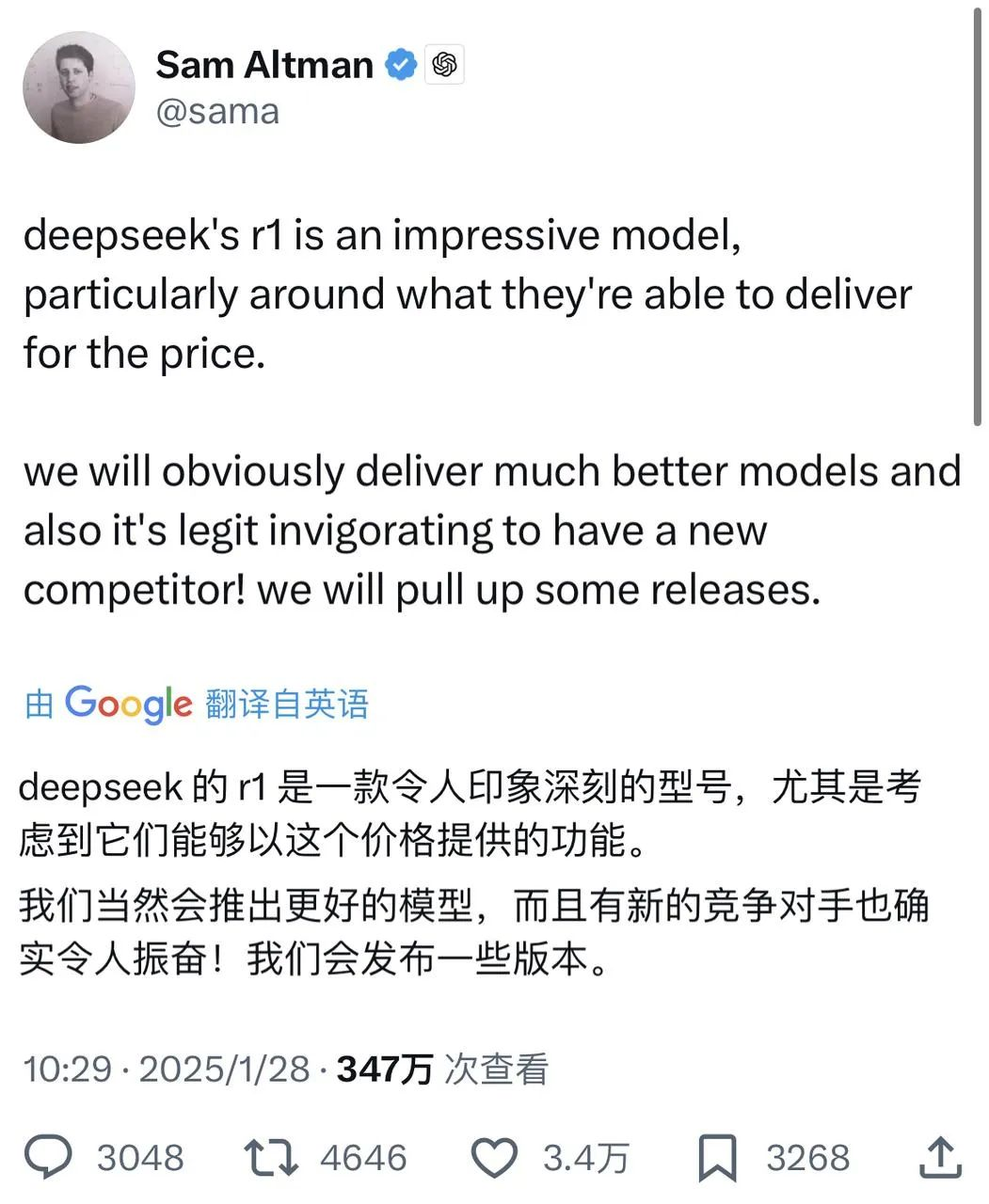
Agora mesmo, Sam Altman, que vem sendo arrastado pela opinião pública há vários dias, finalmente respondeu positivamente às informações sobre o DeepSeek on X - ao elogiar o R1, ele disse que a OpenAI fará alguns anúncios.