DeepSeek has updated its website.
In the early hours of New Year’s Eve, DeepSeek suddenly announced on GitHub that the Janus project space had opened source the Janus-Pro model and technical report.
First, let’s highlight a few key points:
- The Janus-Pro model released this time is a multimodal model that can simultaneously perform multimodal understanding and image generation tasks. It has a total of two parameter versions, Janus-Pro-1B and Janus-Pro-7B.
- The core innovation of Janus-Pro is to decouple multimodal understanding and generation, two different tasks. This allows these two tasks to be efficiently completed in the same model.
- Janus-Pro is consistent with the Janus model architecture released by DeepSeek last October, but at that time Janus did not have much volume. Dr. Charles, an algorithm expert in the field of vision, told us that the previous Janus was “average” and “not as good as DeepSeek’s language model”.

It is intended to solve the industry’s difficult problem: balancing multimodal understanding and image generation
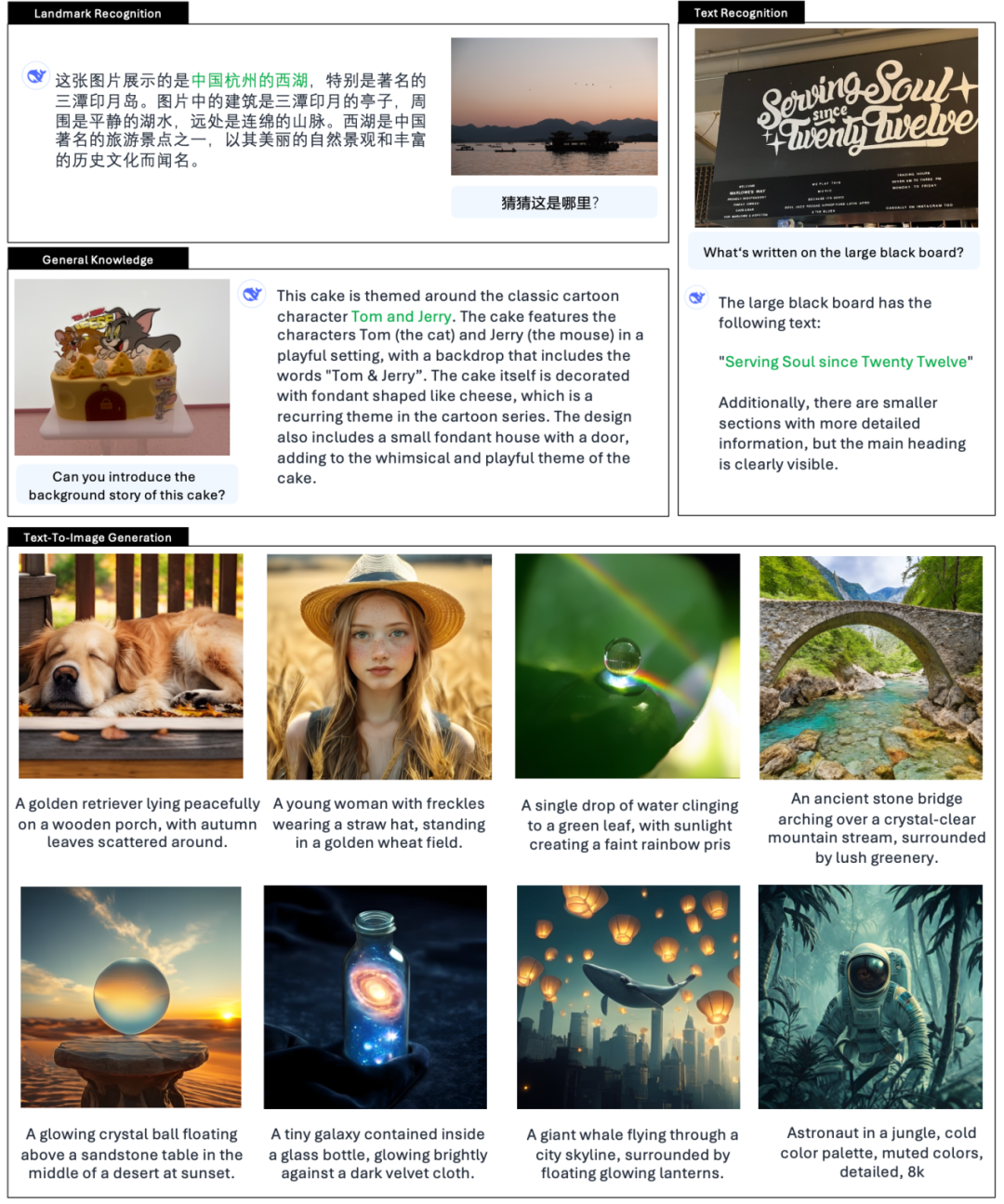
According to the official introduction of DeepSeek, Janus-Pro can not only understand pictures, extract and understand the text in the pictures, but also generate pictures at the same time.
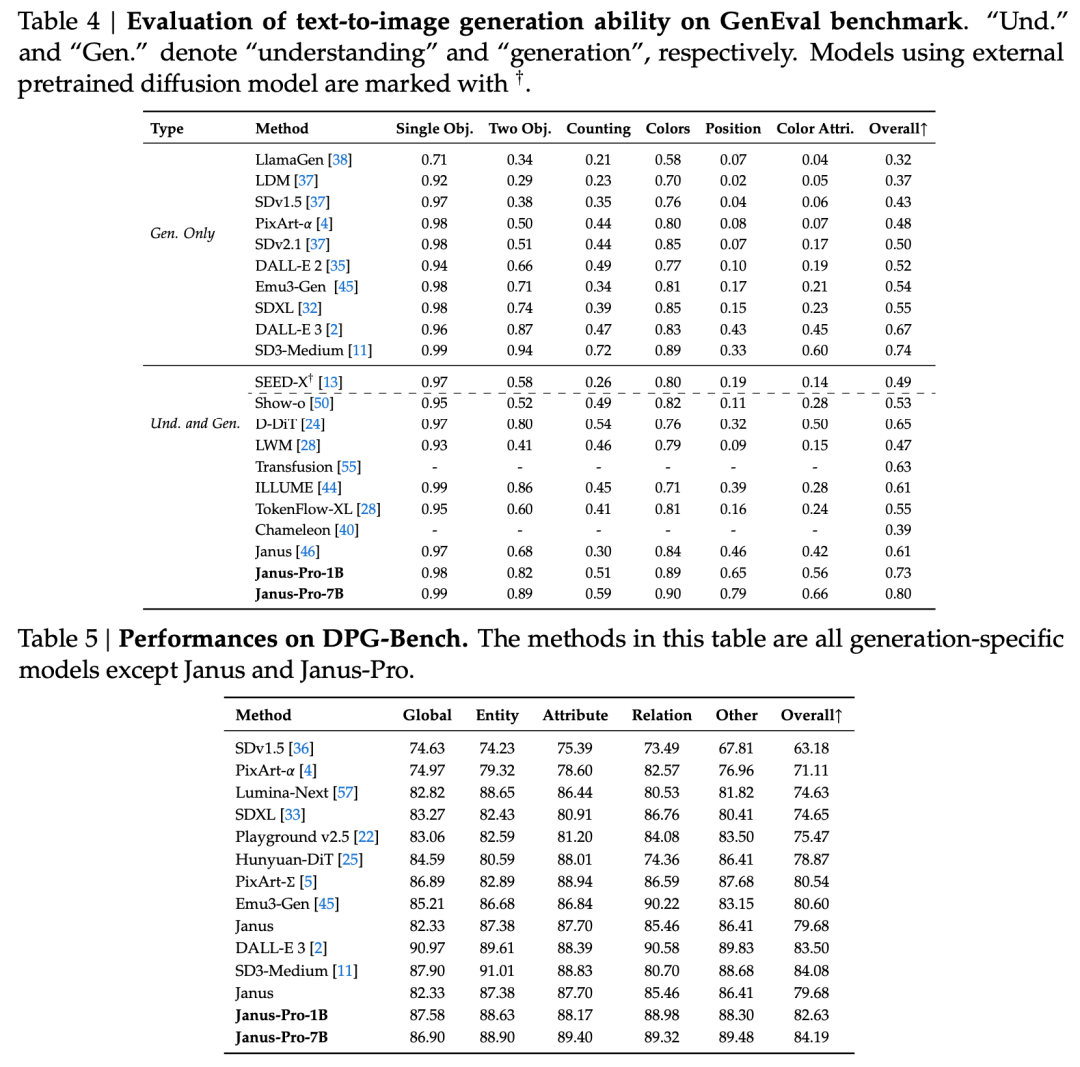
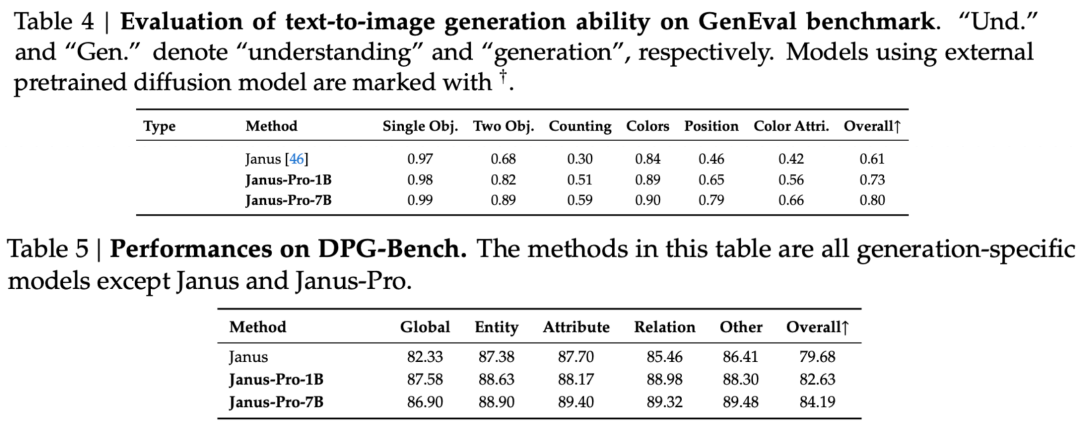
The technical report mentions that compared with other models of the same type and order of magnitude, Janus-Pro-7B’s scores on the GenEval and DPG-Bench test sets exceed those of other models such as SD3-Medium and DALL-E 3.
The official also gives examples 👇:
There are also many netizens on X trying out the new features.

But there are also occasional crashes.
By consulting the technical papers on DeepSeek, we found that Janus Pro is an optimization based on Janus, which was released three months ago.
The core innovation of this series of models is to decouple visual understanding tasks from visual generation tasks, so that the effects of the two tasks can be balanced.
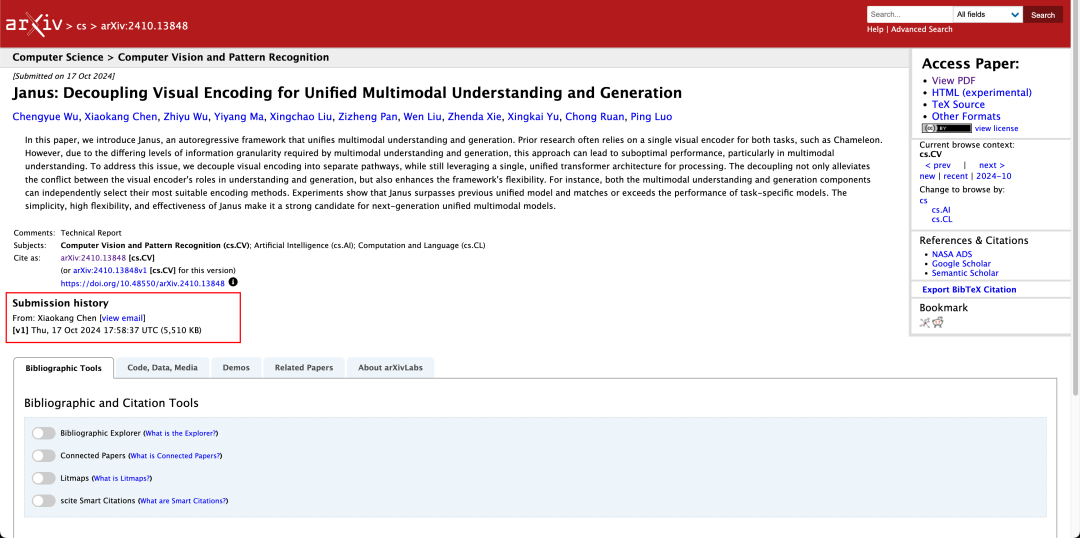
It is not uncommon for a model to perform multimodal understanding and generation at the same time. D-DiT and TokenFlow-XL in this test set both have this ability.
However, what is characteristic of Janus is that by decoupling processing, a model that can perform multimodal understanding and generation balances the effectiveness of the two tasks.
Balancing the effectiveness of the two tasks is a difficult problem in the industry. Previously, the thinking was to use the same encoder to implement multimodal understanding and generation as much as possible.
The advantages of this approach are a simple architecture, no redundant deployment, and an alignment with text models (which also use the same methods to achieve text generation and text understanding). Another argument is that this fusion of multiple abilities can lead to a certain degree of emergence.
However, in fact, after fusing generation and understanding, the two tasks will conflict – image understanding requires the model to abstract in high dimensions and extract the core semantics of the picture, which is biased towards the macroscopic. Image generation, on the other hand, focuses on the expression and generation of local details at the pixel level.
The industry’s usual practice is to prioritize image generation capabilities. This results in multimodal models that can generate higher-quality images, but the results of image understanding are often mediocre.
Janus’s decoupled architecture and Janus-Pro’s optimized training strategy
Janus’s decoupled architecture allows the model to balance the tasks of understanding and generating on its own.
According to the results in the official technical report, whether it is multimodal understanding or image generation, Janus-Pro-7B performs well on multiple test sets.

For multimodal understanding, Janus-Pro-7B achieved first place in four of the seven evaluation datasets, and second place in the remaining three, slightly behind the top-ranked model.
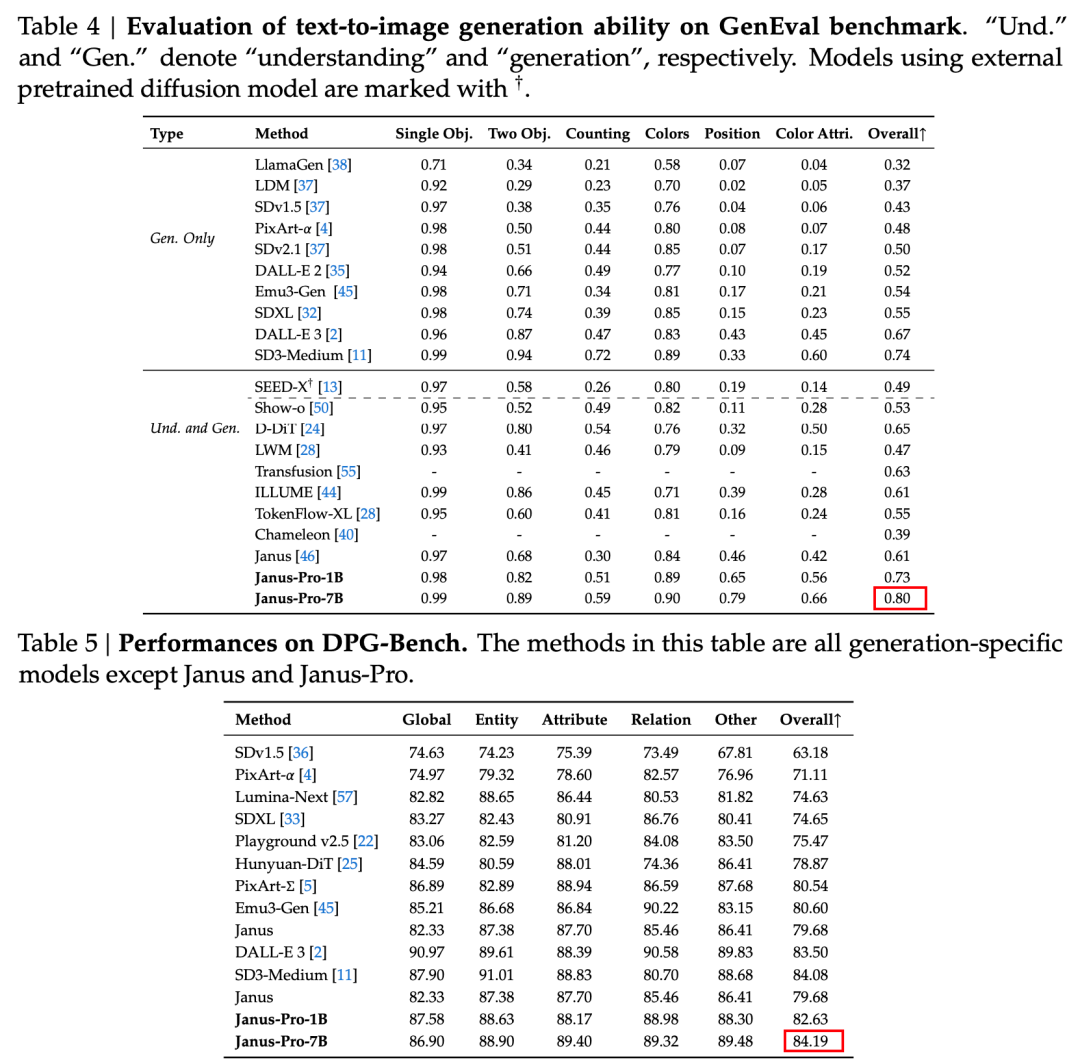
For image generation, Janus-Pro-7B achieved first place in the overall score on both the GenEval and DPG-Bench evaluation datasets.
This multi-tasking effect is mainly due to the Janus series’ use of two visual encoders for different tasks:
- Understanding encoder: used to extract semantic features in images for image understanding tasks (such as image questions and answers, visual classification, etc.).
- Generative encoder: converts images into a discrete representation (e.g., using a VQ encoder) for text-to-image generation tasks.
With this architecture, the model can independently optimize the performance of each encoder, so that multimodal understanding and generation tasks can each achieve their best performance.
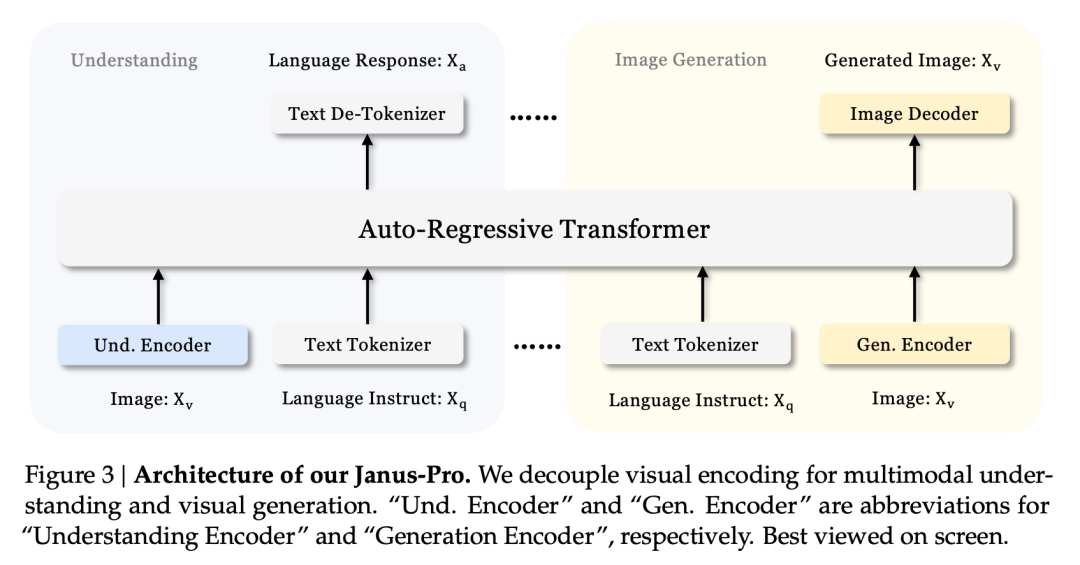
This decoupled architecture is common to Janus-Pro and Janus. So, what iterations has Janus-Pro had in the past few months?
As can be seen from the results of the evaluation set, the current release of Janus-Pro-1B has an improvement of about 10% to 20% in the scores of different evaluation sets compared to the previous Janus. Janus-Pro-7B has the highest improvement of about 45% compared to Janus after expanding the number of parameters.

In terms of training details, the technical report states that the current release of Janus-Pro, compared to the previous Janus model, retains the core decoupled architecture design, and additionally iterates on parameter size, training strategy, and training data.
First, let’s look at the parameters.
The first version of Janus had only 1.3B parameters, and the current release of Pro includes models with 1B and 7B parameters.
These two sizes reflect the scalability of the Janus architecture. The 1B model, which is the lightest, has already been used by external users to run in the browser using WebGPU.
There is also the training strategy.
In line with the training phase division of Janus, Janus Pro has a total of three training phases, and the paper directly divides them into Stage I, Stage II and Stage III.
While retaining the basic training ideas and training objectives of each phase, Janus-Pro has made improvements to the training duration and training data in the three phases. The following are the specific improvements in the three stages:
Stage I – Longer training time
Compared with Janus, Janus-Pro has extended the training time in Stage I, especially in the training of adapters and image heads in the visual part. This means that the learning of visual features has been given more training time, and it is hoped that the model can fully understand the detailed features of images (such as pixel-to-semantic mapping).
This extended training helps ensure that the training of the visual part is not disturbed by other modules.
Stage II – Removing ImageNet data and adding multi-modal data
In Stage II, Janus previously referenced PixArt and trained in two parts. The first part was trained using the ImageNet dataset for the image classification task, and the second part was trained using regular text-to-image data. About two-thirds of the time in Stage II was spent training in the first part.
Janus-Pro removes the ImageNet training in Stage II. This design allows the model to focus on text-to-image data during Stage II training. According to experimental results, this can significantly improve the utilization of text-to-image data.
In addition to the adjustment of the training method design, the training data set used in Stage II is no longer limited to a single image classification task, but also includes more other types of multimodal data, such as image description and dialogue, for joint training.
Stage III – Optimizing the data ratio
In Stage III training, Janus-Pro adjusts the ratio of different types of training data.
Previously, the ratio of multimodal understanding data, plain text data, and text-to-image data in the training data used by Janus in Stage III was 7:3:10. Janus-Pro reduces the ratio of the latter two types of data and adjusts the ratio of the three types of data to 5:1:4, that is, paying more attention to the multimodal understanding task.
Let’s look at the training data.
Compared to Janus, Janus-Pro this time significantly increases the amount of high-quality synthetic data.
It expands the quantity and variety of training data for multimodal understanding and image generation.
Expansion of multimodal understanding data:
Janus-Pro refers to the DeepSeek-VL2 dataset during training and adds about 90 million additional data points, including not only image description datasets, but also datasets of complex scenes such as tables, charts, and documents.
During the supervised fine-tuning stage (Stage III), it continues to add datasets related to MEME understanding and dialogue (including Chinese dialogue) experience improvement.
Expansion of visual generation data:
The original real-world data had poor quality and high noise levels, which caused the model to produce unstable outputs and images of insufficient aesthetic quality in text-to-image tasks.
Janus-Pro added about 72 million new high-aesthetic synthetic data to the training phase, bringing the ratio of real data to synthetic data in the pre-training phase to 1:1.
The prompts for the synthetic data were all taken from public resources. Experiments have shown that the addition of this data makes the model converge faster, and the generated images have obvious improvements in stability and visual beauty.
The continuation of an efficiency revolution?
Overall, with this release, DeepSeek has brought the efficiency revolution to visual models.
Unlike visual models that focus on a single function or multimodal models that favor a specific task, Janus-Pro balances the effects of the two major tasks of image generation and multimodal understanding in the same model.
Moreover, despite its small parameters, it beatOpenAI DALL-E 3 and SD3-Medium in the evaluation.
Extended to the ground, the enterprise only needs to deploy a model to directly implement the two functions of image generation and understanding. Coupled with a size of only 7B, the difficulty and cost of deployment are much lower.
In connection with the previous releases of R1 and V3, DeepSeek is challenging the existing rules of the game with “compact architectural innovation, lightweight models, open source models, and ultra-low training costs”. This is the reason for the panic among Western technology giants and even Wall Street.
Just now, Sam Altman, who has been swept along by public opinion for several days, finally responded positively to information about DeepSeek on X—while praising R1, he said that OpenAI will make some announcements.