DeepSeek에서 웹사이트를 업데이트했습니다.
새해 전야 새벽, DeepSeek는 갑자기 야누스 프로젝트 공간에서 Janus-Pro 모델과 기술 보고서를 오픈소스로 공개한다고 GitHub에 발표했습니다.
먼저 몇 가지 핵심 사항을 강조해 보겠습니다:
- 그리고 Janus-Pro 모델 이번에 출시된 멀티모달 모델은 는 멀티모달 이해와 이미지 생성 작업을 동시에 수행할 수 있습니다. 총 두 가지 파라미터 버전이 있습니다, Janus-Pro-1B 및 Janus-Pro-7B.
- Janus-Pro의 핵심 혁신은 디커플링입니다. 멀티모달 이해와 생성, 서로 다른 두 가지 작업을 수행합니다. 이를 통해 이 두 가지 작업을 동일한 모델에서 효율적으로 완료할 수 있습니다..
- Janus-Pro는 지난해 10월 DeepSeek에서 발표한 야누스 모델 아키텍처와 일치하지만 당시 야누스는 볼륨이 많지 않았습니다. 시각 분야의 알고리즘 전문가인 찰스 박사는 이전 야누스가 "평균 수준"이었으며 "딥시크의 언어 모델만큼 좋지 않았다"고 말했습니다.

멀티모달 이해와 이미지 생성의 균형이라는 업계의 어려운 문제를 해결하기 위한 것입니다.
딥시크의 공식 소개에 따르면, Janus-Pro 는 사진을 이해하고, 사진 속 텍스트를 추출하여 이해할 수 있을 뿐만 아니라 동시에 사진을 생성할 수도 있습니다.
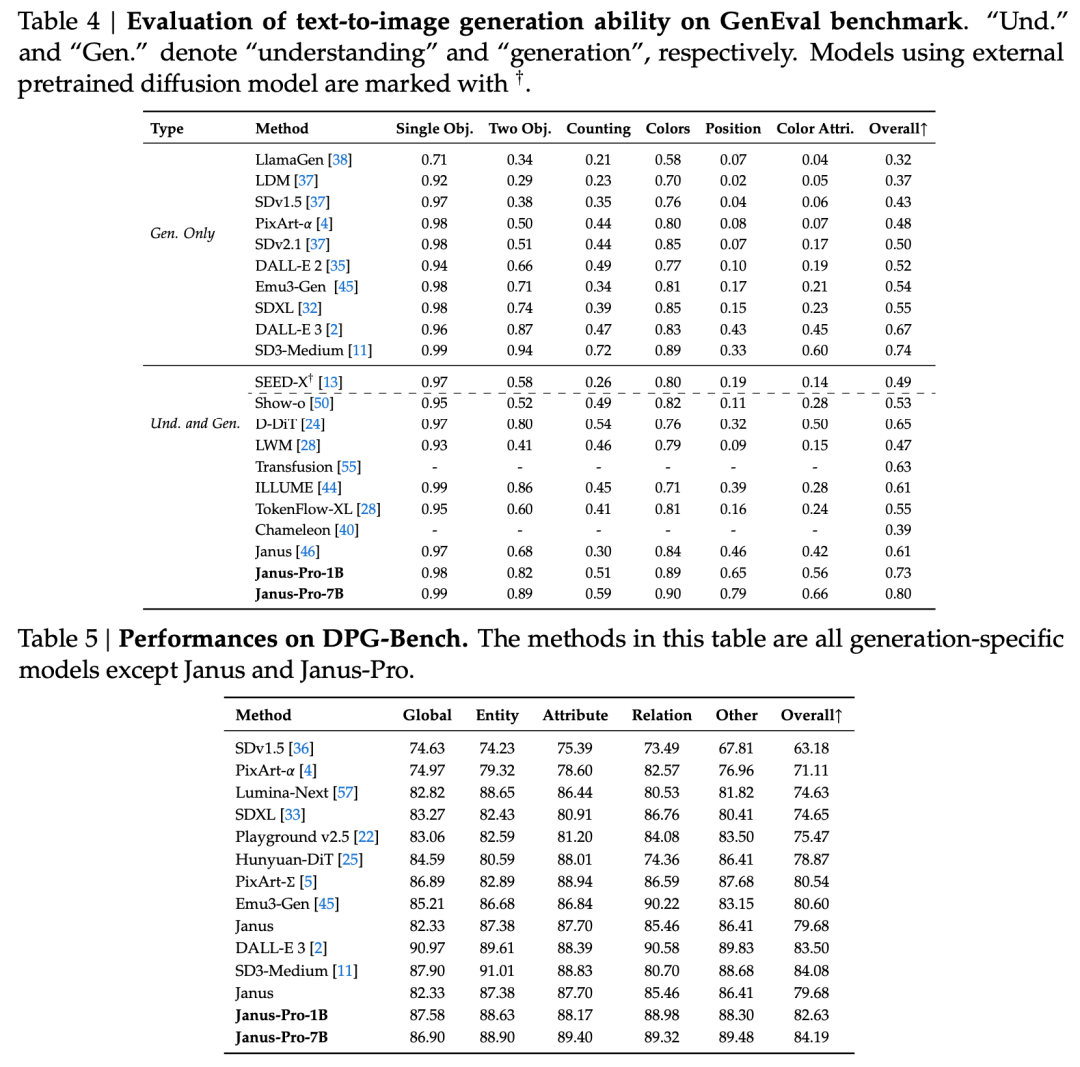
기술 보고서에는 동일한 유형 및 규모의 다른 모델과 비교했을 때 Janus-Pro-7B의 GenEval 및 DPG-Bench 테스트 세트 점수가 다음과 같이 언급되어 있습니다. SD3-Medium 및 DALL-E 3과 같은 다른 모델의 성능을 능가합니다.
관계자는 또한 예를 들어 👇:
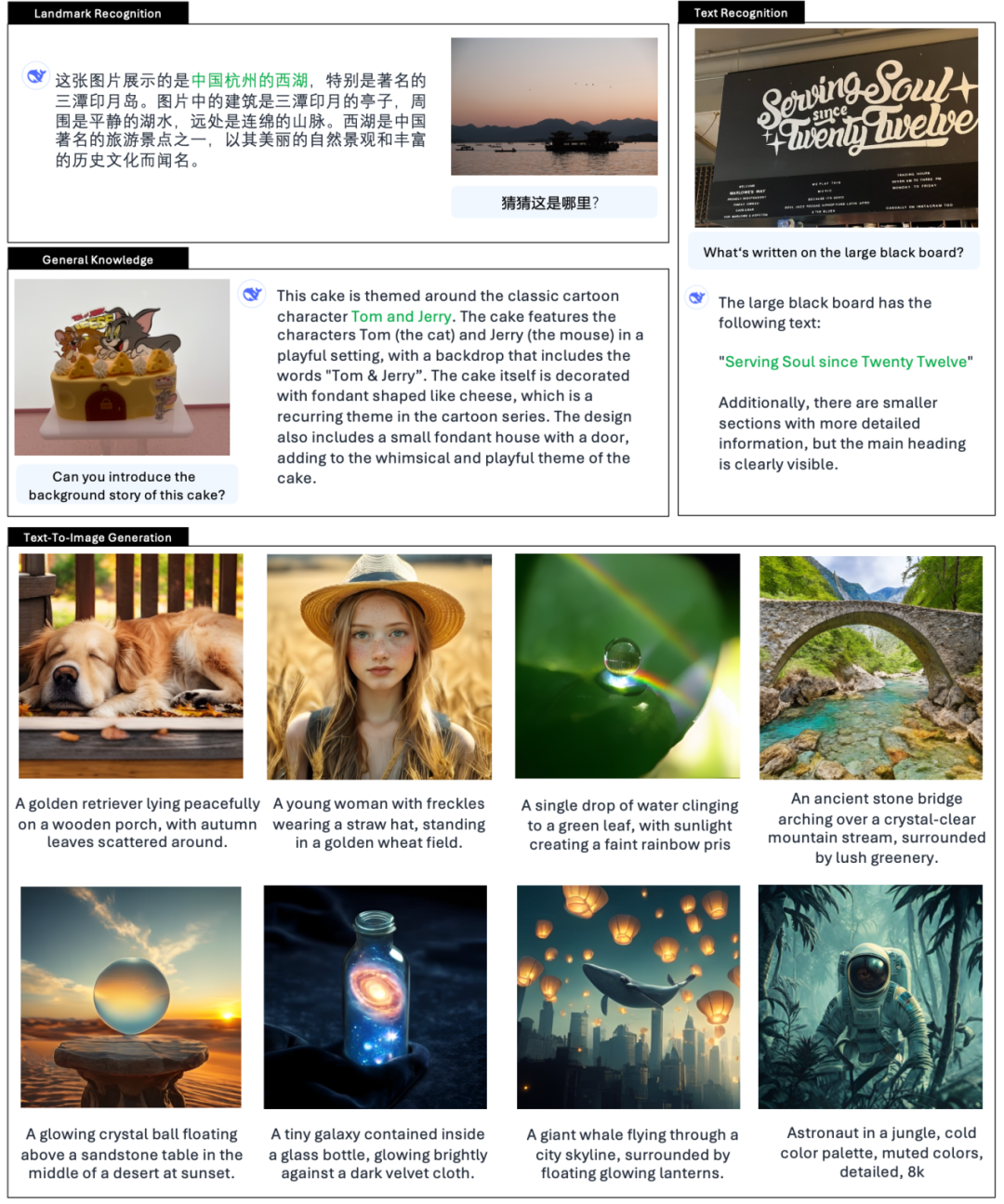
X에서 많은 네티즌이 새로운 기능을 사용해보고 있습니다.

하지만 가끔 충돌이 발생하기도 합니다.
다음에 대한 기술 문서를 참조하여 DeepSeekJanus Pro는 3개월 전에 출시된 야누스를 기반으로 한 최적화라는 것을 알게 되었습니다.
이 모델 시리즈의 핵심 혁신은 다음과 같습니다. 시각적 이해 작업과 시각적 생성 작업을 분리하여 두 작업의 효과를 균형 있게 조정할 수 있습니다.
모델이 멀티모달 이해와 생성을 동시에 수행하는 것은 드문 일이 아닙니다. 이 테스트 세트의 D-DiT와 TokenFlow-XL은 모두 이러한 기능을 갖추고 있습니다.
하지만 야누스의 특징은 다음과 같습니다. 프로세싱을 분리하여 멀티모달 이해와 생성을 수행할 수 있는 모델로 두 작업의 효율성을 균형 있게 조정합니다.
업계에서 두 가지 작업의 효율성의 균형을 맞추는 것은 어려운 문제입니다. 이전에는 가능한 한 동일한 인코더를 사용하여 멀티모달 이해와 생성을 구현하는 것이 목표였습니다.
이 접근 방식의 장점은 아키텍처가 간단하고, 중복 배포가 없으며, 텍스트 모델(텍스트 생성 및 텍스트 이해를 위해 동일한 방법을 사용)과 일치한다는 점입니다. 또 다른 장점은 이러한 여러 기능의 융합으로 어느 정도 새로운 기능을 구현할 수 있다는 것입니다.
그러나 사실 이미지 이해는 고차원적으로 추상화하고 거시적인 것에 편향된 그림의 핵심 의미를 추출해야 하기 때문에 생성 및 이해가 융합된 후에는 두 가지 작업이 충돌하게 됩니다. 반면 이미지 생성은 픽셀 수준에서 로컬 디테일의 표현과 생성에 중점을 둡니다.
업계의 일반적인 관행은 이미지 생성 기능에 우선순위를 두는 것입니다. 그 결과 다음과 같은 멀티모달 모델이 탄생합니다. 는 더 높은 품질의 이미지를 생성할 수 있지만 이미지 이해 결과는 평범한 경우가 많습니다.
야누스의 분리형 아키텍처와 Janus-Pro의 최적화된 교육 전략
야누스의 분리형 아키텍처는 모델이 자체적으로 이해와 생성 작업의 균형을 맞출 수 있게 해줍니다.
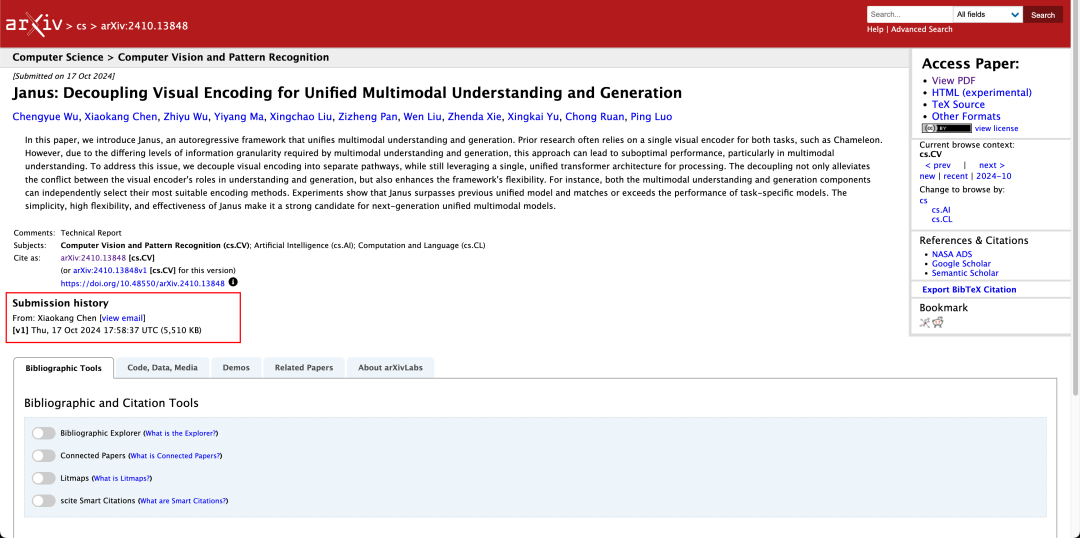
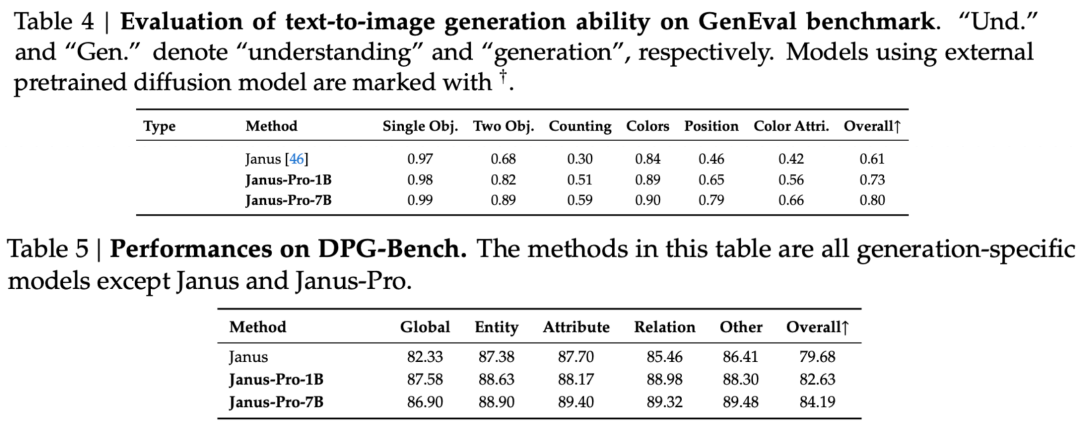
공식 기술 보고서의 결과에 따르면, 멀티모달 이해이든 이미지 생성이든 Janus-Pro-7B는 여러 테스트 세트에서 우수한 성능을 발휘합니다.

멀티모달 이해를 위해, Janus-Pro-7B는 7개의 평가 데이터 세트 중 4개에서 1위를, 나머지 3개에서는 1위 모델에 약간 뒤진 2위를 차지했습니다.
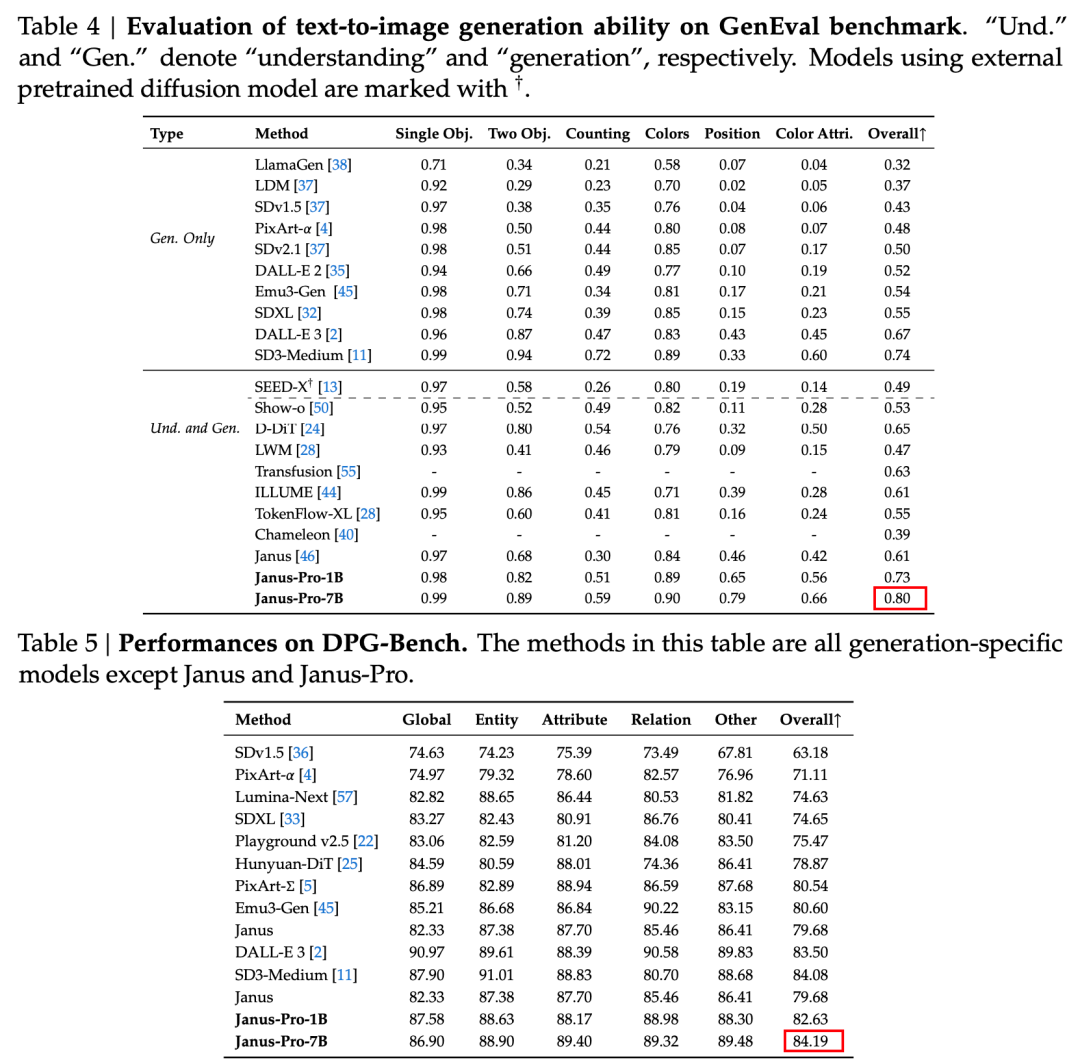
이미지 생성용, Janus-Pro-7B는 GenEval과 DPG-Bench 평가 데이터 세트 모두에서 종합 점수 1위를 달성했습니다.
이러한 멀티태스킹 효과는 주로 야누스 시리즈가 서로 다른 작업을 위해 두 개의 비주얼 인코더를 사용하기 때문입니다:
- 인코더 이해: 이미지 이해 작업(예: 이미지 질문과 답변, 시각적 분류 등)을 위해 이미지에서 의미론적 특징을 추출하는 데 사용됩니다.
- 제너레이티브 인코더: 는 텍스트-이미지 생성 작업을 위해 이미지를 개별 표현(예: VQ 인코더 사용)으로 변환합니다.
이 아키텍처를 사용합니다, 모델은 각 인코더의 성능을 독립적으로 최적화할 수 있으므로 멀티모달 이해 및 생성 작업이 각각 최상의 성능을 달성할 수 있습니다.
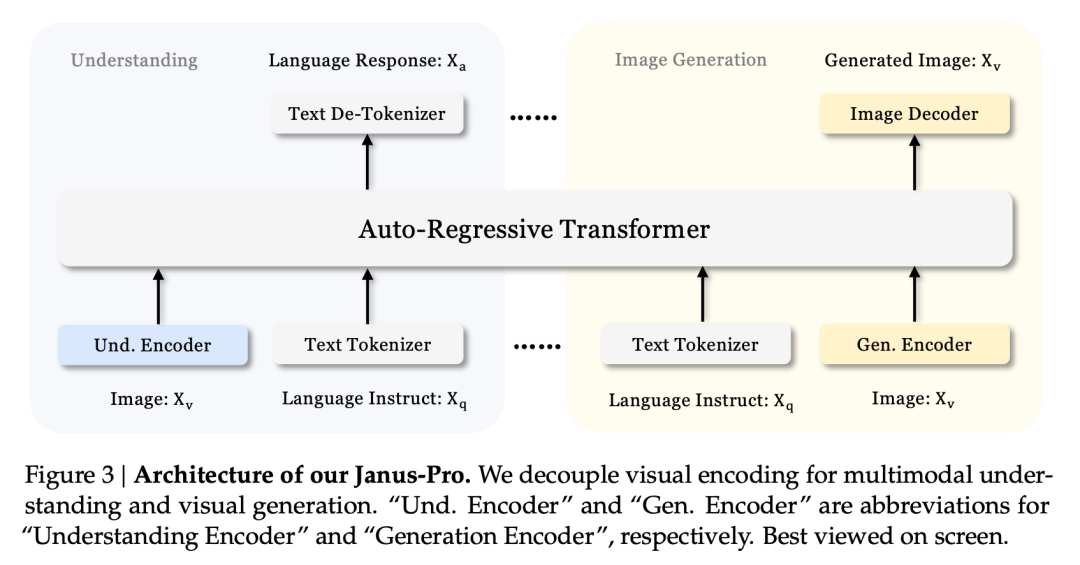
이 분리형 아키텍처는 Janus-Pro와 야누스에 공통적으로 적용됩니다. 그렇다면 지난 몇 달 동안 Janus-Pro는 어떤 반복을 거쳤을까요?
평가 세트의 결과에서 알 수 있듯이, 현재 출시된 Janus-Pro-1B는 이전 야누스와 비교하여 다양한 평가 세트의 점수에서 약 10%에서 20%까지 개선되었습니다. Janus-Pro-7B는 매개변수 수를 확장한 후 야누스 대비 약 45%로 가장 높은 향상을 보였습니다.

교육 세부 사항 측면에서 기술 보고서에 따르면 현재 릴리스된 Janus-Pro는 이전 야누스 모델에 비해 핵심 디커플링 아키텍처 설계를 유지하며, 추가로 다음을 반복합니다. 매개변수 크기, 학습 전략 및 학습 데이터에 따라 달라집니다.
먼저 매개 변수를 살펴보겠습니다..
야누스의 첫 번째 버전에는 13억 개의 매개변수만 있었지만, 현재 출시된 프로 버전에는 10억 개와 7억 개의 매개변수를 가진 모델이 포함되어 있습니다.
이 두 가지 크기는 야누스 아키텍처의 확장성을 반영합니다. 가장 가벼운 1B 모델은 이미 외부 사용자가 WebGPU를 사용하여 브라우저에서 실행하는 데 사용되었습니다.
또한 의 교육 전략.
야누스의 훈련 단계 구분과 같이 Janus Pro는 총 3개의 훈련 단계가 있으며, 논문에서는 이를 1단계, 2단계, 3단계로 직접 구분하고 있습니다.
각 단계의 기본 훈련 아이디어와 훈련 목표는 그대로 유지하면서 Janus-Pro는 세 단계의 훈련 기간과 훈련 데이터를 개선했습니다. 다음은 세 단계의 구체적인 개선 사항입니다:
1단계 - 더 긴 교육 시간
Janus-Pro는 야누스에 비해 1단계의 훈련 시간, 특히 시각 부분의 어댑터와 이미지 헤드의 훈련 시간이 길어졌습니다. 이는 시각적 특징 학습에 더 많은 훈련 시간이 주어졌음을 의미하며, 모델이 이미지의 세부 특징(픽셀 대 의미 매핑 등)을 완전히 이해할 수 있기를 기대합니다.
이 확장된 훈련은 시각 부분의 훈련이 다른 모듈에 의해 방해받지 않도록 도와줍니다.
2단계 - ImageNet 데이터 제거 및 멀티모달 데이터 추가
2단계에서 Janus는 이전에 PixArt를 참조하여 두 부분으로 학습했습니다. 첫 번째 파트는 이미지 분류 작업을 위해 이미지넷 데이터 세트를 사용하여 훈련했고, 두 번째 파트는 일반 텍스트-이미지 데이터를 사용하여 훈련했습니다. 2단계 시간의 약 3분의 2는 첫 번째 파트에서 훈련하는 데 사용되었습니다.
Janus-Pro는 2단계에서 이미지넷 트레이닝을 제거합니다. 이 설계를 통해 모델은 2단계 학습 중에 텍스트-대-이미지 데이터에 집중할 수 있습니다. 실험 결과에 따르면 이는 텍스트-이미지 데이터의 활용도를 크게 향상시킬 수 있습니다.
훈련 방법 설계의 조정과 더불어, 2단계에서 사용되는 훈련 데이터 세트는 더 이상 단일 이미지 분류 작업에 국한되지 않고 이미지 설명 및 대화와 같은 다른 유형의 멀티모달 데이터도 포함하여 공동 훈련에 사용됩니다.
3단계 - 데이터 비율 최적화
3단계 훈련에서 Janus-Pro는 다양한 유형의 훈련 데이터의 비율을 조정합니다.
이전에는 3단계에서 야누스가 사용한 학습 데이터에서 다중 모드 이해 데이터, 일반 텍스트 데이터, 텍스트-이미지 데이터의 비율은 7:3:10이었습니다. Janus-Pro는 후자의 두 가지 유형의 데이터 비율을 줄이고 세 가지 유형의 데이터 비율을 5:1:4로 조정하여 다중 모달 이해 과제에 더 많은 주의를 기울입니다.
학습 데이터를 살펴보겠습니다.
야누스에 비해 이번 Janus-Pro는 고화질 합성 데이터.
멀티모달 이해 및 이미지 생성을 위한 학습 데이터의 양과 다양성을 확장합니다.
멀티모달 이해 데이터의 확장:
Janus-Pro는 학습 중 DeepSeek-VL2 데이터셋을 참조하여 이미지 설명 데이터셋뿐만 아니라 표, 차트, 문서 등 복잡한 장면의 데이터셋을 포함하여 약 9천만 개의 데이터 포인트를 추가로 추가합니다.
감독 미세 조정 단계(3단계)에서는 MEME 이해 및 대화(중국어 대화 포함) 환경 개선과 관련된 데이터 세트를 계속 추가합니다.
시각적 생성 데이터의 확장:
원본 실제 데이터는 품질이 좋지 않고 노이즈 수준이 높아서 텍스트-이미지 변환 작업에서 모델이 불안정한 출력과 미적 품질이 불충분한 이미지를 생성하는 원인이 되었습니다.
Janus-Pro는 훈련 단계에 약 7,200만 개의 새로운 고품질 합성 데이터를 추가하여 사전 훈련 단계에서 실제 데이터와 합성 데이터의 비율을 1:1로 맞췄습니다.
합성 데이터의 프롬프트는 모두 공개 리소스에서 가져온 것입니다. 실험 결과, 이 데이터를 추가하면 모델이 더 빠르게 수렴하고 생성된 이미지의 안정성과 시각적 아름다움이 뚜렷하게 개선되는 것으로 나타났습니다.
효율성 혁명의 지속?
전반적으로 이번 릴리스를 통해 딥시크는 시각적 모델에 효율성 혁명을 가져왔습니다.
단일 기능에 초점을 맞춘 시각 모델이나 특정 작업에 유리한 멀티모달 모델과 달리 Janus-Pro는 동일한 모델에서 이미지 생성 및 멀티모달 이해라는 두 가지 주요 작업의 효과를 균형 있게 조정합니다.
또한, 작은 매개 변수에도 불구하고 평가에서 OpenAI DALL-E 3 및 SD3-Medium을 이겼습니다.
지상으로 확장하면 기업은 이미지 생성 및 이해라는 두 가지 기능을 직접 구현하기 위한 모델만 배포하면 됩니다. 규모가 70억에 불과하기 때문에 배포의 난이도와 비용도 훨씬 낮습니다.
딥시큐어는 이전 버전인 R1 및 V3와 관련하여 다음과 같이 기존 게임의 규칙에 도전하고 있습니다. "컴팩트한 아키텍처 혁신, 경량 모델, 오픈 소스 모델, 초저가 교육 비용". 이것이 서구 기술 대기업과 심지어 월스트리트까지 패닉에 빠진 이유입니다.
며칠 동안 여론의 뭇매를 맞았던 샘 알트먼은 마침내 X의 딥시크에 대한 정보에 긍정적으로 반응하며 R1을 칭찬하는 한편, OpenAI가 몇 가지 발표를 할 것이라고 말했습니다.