DeepSeek hat seine Website aktualisiert.
In den frühen Morgenstunden der Silvesternacht gab DeepSeek plötzlich auf GitHub bekannt, dass der Janus-Projektraum die Quelle des Janus-Pro-Modells und des technischen Berichts geöffnet hatte.
Lassen Sie uns zunächst einige wichtige Punkte hervorheben:
- Die Modell Janus-Pro Diesmal wird ein multimodales Modell veröffentlicht, das kann gleichzeitig Aufgaben des multimodalen Verstehens und der Bilderzeugung übernehmen. Es hat insgesamt zwei Parameter-Versionen, Janus-Pro-1B und Janus-Pro-7B.
- Die wichtigste Innovation von Janus-Pro ist die Entkopplung multimodales Verstehen und Generieren, zwei unterschiedliche Aufgaben. So können diese beiden Aufgaben effizient in demselben Modell erledigt werden.
- Janus-Pro stimmt mit der Janus-Modellarchitektur überein, die DeepSeek im Oktober letzten Jahres veröffentlicht hat, aber zu diesem Zeitpunkt hatte Janus noch nicht viel Volumen. Dr. Charles, ein Algorithmus-Experte auf dem Gebiet des Sehens, sagte uns, dass das vorherige Janus-Modell "durchschnittlich" und "nicht so gut wie das Sprachmodell von DeepSeek" war.

Es soll das schwierige Problem der Branche lösen: ein Gleichgewicht zwischen multimodalem Verständnis und Bilderzeugung
Laut der offiziellen Einführung von DeepSeek, Janus-Pro kann nicht nur Bilder verstehen, den Text in den Bildern extrahieren und verstehen, sondern auch gleichzeitig Bilder erzeugen.
Im technischen Bericht wird erwähnt, dass die Ergebnisse des Janus-Pro-7B im Vergleich zu anderen Modellen desselben Typs und derselben Größenordnung bei den Testsätzen GenEval und DPG-Bench übertreffen die Werte anderer Modelle wie SD3-Medium und DALL-E 3.
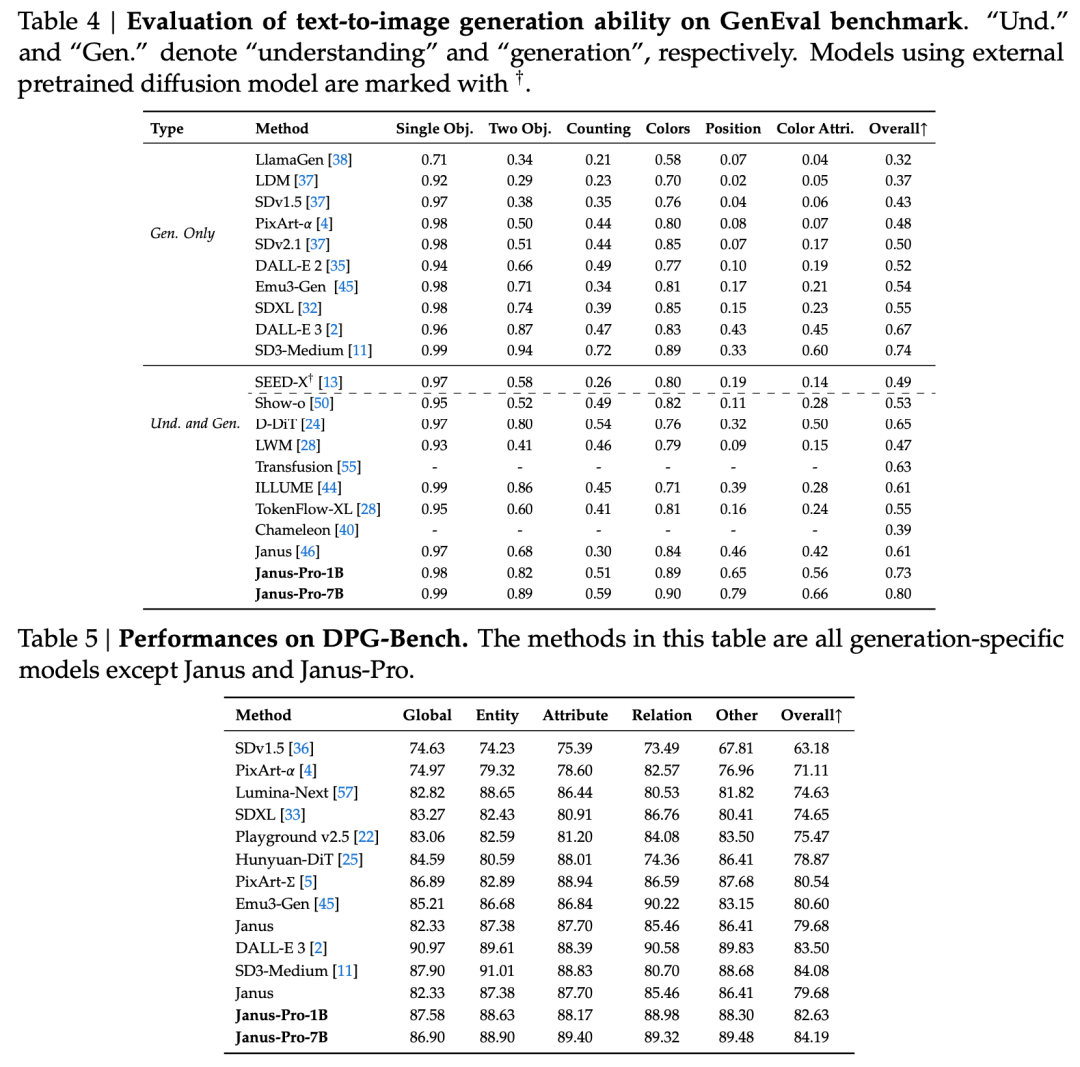
Der Beamte nennt auch Beispiele 👇:
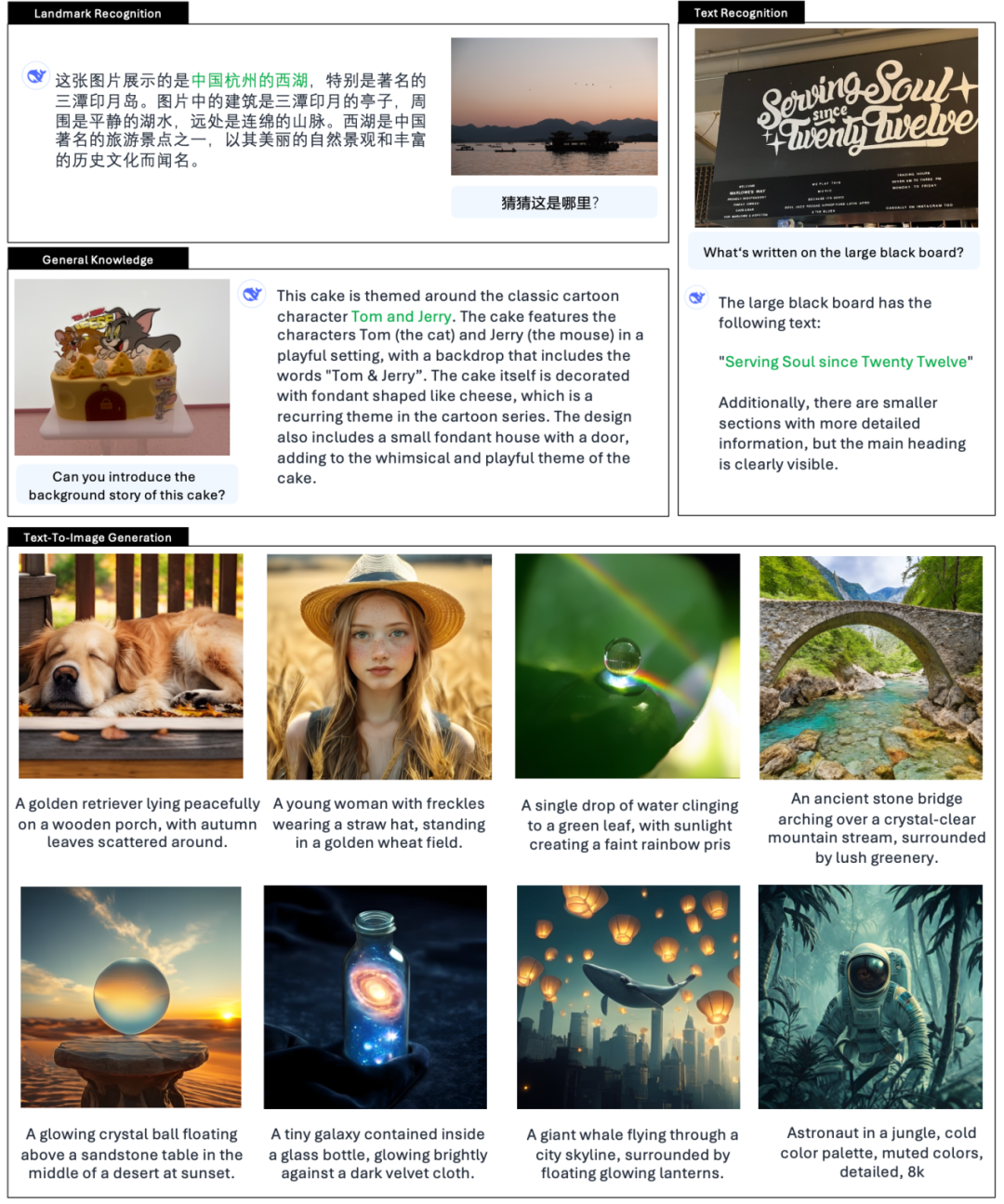
Es gibt auch viele Netizens auf X, die die neuen Funktionen ausprobieren.

Aber es kommt auch gelegentlich zu Abstürzen.
Durch die Konsultation der technischen Unterlagen über DeepSeekhaben wir festgestellt, dass Janus Pro eine Optimierung auf der Grundlage von Janus ist, die vor drei Monaten veröffentlicht wurde.
Die wichtigste Innovation dieser Modellreihe besteht darin, dass Aufgaben zum visuellen Verstehen von Aufgaben zur visuellen Erzeugung zu entkoppeln, so dass die Auswirkungen der beiden Aufgaben ausgeglichen werden können.
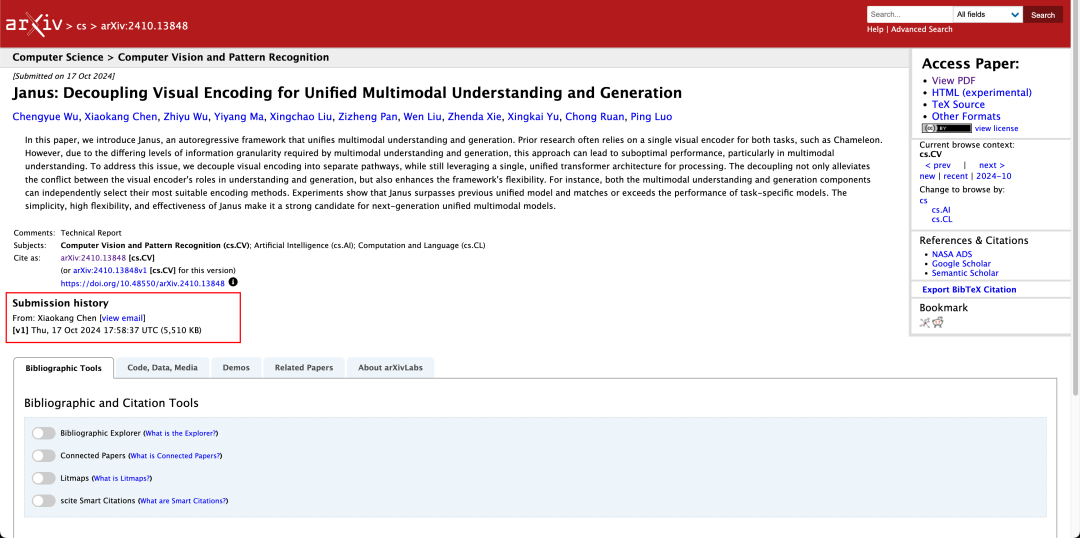
Es ist nicht ungewöhnlich, dass ein Modell multimodales Verstehen und Generieren gleichzeitig durchführen kann. D-DiT und TokenFlow-XL in diesem Testsatz haben beide diese Fähigkeit.
Charakteristisch für Janus ist jedoch, dass Durch die Entkopplung der Verarbeitung kann ein Modell, das multimodales Verstehen und Generieren ermöglicht, die Effektivität der beiden Aufgaben ausgleichen.
Das Gleichgewicht zwischen den beiden Aufgaben ist ein schwieriges Problem in der Branche. Bisher war man der Meinung, dass ein und derselbe Encoder verwendet werden sollte, um multimodales Verstehen und Generieren so weit wie möglich zu realisieren.
Die Vorteile dieses Ansatzes sind eine einfache Architektur, kein redundanter Einsatz und eine Angleichung an Textmodelle (die ebenfalls die gleichen Methoden zur Texterzeugung und zum Textverständnis verwenden). Ein weiteres Argument ist, dass diese Verschmelzung mehrerer Fähigkeiten zu einem gewissen Grad an Emergenz führen kann.
Nach der Verschmelzung von Generierung und Verstehen stehen die beiden Aufgaben jedoch im Widerspruch zueinander: Das Bildverständnis erfordert, dass das Modell in hohen Dimensionen abstrahiert und die Kernsemantik des Bildes extrahiert, die eher makroskopisch ist. Die Bilderzeugung hingegen konzentriert sich auf den Ausdruck und die Erzeugung lokaler Details auf der Pixelebene.
Die übliche Praxis der Industrie besteht darin, den Fähigkeiten zur Bilderzeugung Vorrang einzuräumen. Dies führt zu multimodalen Modellen, die können qualitativ hochwertigere Bilder erzeugen, aber die Ergebnisse des Bildverständnisses sind oft nur mittelmäßig.
Die entkoppelte Architektur von Janus und die optimierte Trainingsstrategie von Janus-Pro
Die entkoppelte Architektur von Janus ermöglicht es dem Modell, die Aufgaben des Verstehens und der Generierung selbständig zu bewältigen.
Den Ergebnissen des offiziellen technischen Berichts zufolge schneidet das Janus-Pro-7B bei mehreren Testreihen gut ab, ganz gleich, ob es um multimodales Verstehen oder Bilderzeugung geht.

Für multimodales Verständnis, Janus-Pro-7B erreichte den ersten Platz in vier der sieben Bewertungsdatensätze und den zweiten Platz in den verbleibenden drei, knapp hinter dem bestplatzierten Modell.
Für die Bilderzeugung, Janus-Pro-7B erreichte sowohl bei den GenEval- als auch bei den DPG-Bench-Evaluierungsdatensätzen den ersten Platz in der Gesamtbewertung.
Dieser Multitasking-Effekt ist vor allem darauf zurückzuführen, dass die Janus-Serie zwei visuelle Encoder für unterschiedliche Aufgaben verwendet:
- Verständnis für Encoder: zur Extraktion semantischer Merkmale in Bildern für Bildverstehensaufgaben (z. B. Fragen und Antworten zu Bildern, visuelle Klassifizierung usw.).
- Generativer Kodierer: konvertiert Bilder in eine diskrete Darstellung (z. B. mit einem VQ-Encoder) für Text-Bild-Generierungsaufgaben.
Mit dieser Architektur, kann das Modell die Leistung jedes Encoders unabhängig voneinander optimieren, so dass multimodale Verstehens- und Generierungsaufgaben jeweils ihre beste Leistung erzielen können.
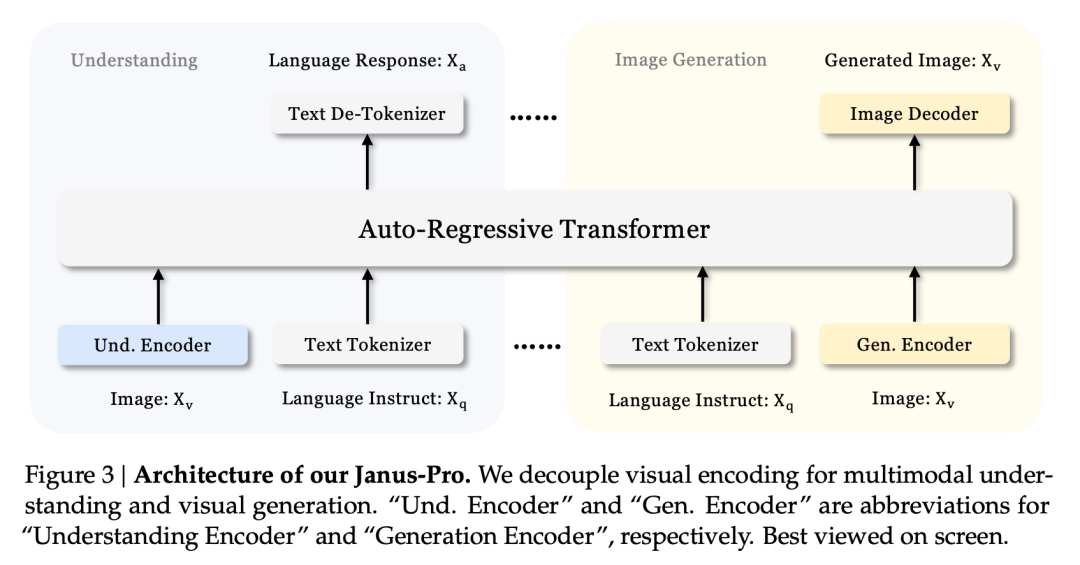
Diese entkoppelte Architektur ist Janus-Pro und Janus gemeinsam. Welche Iterationen hat Janus-Pro in den letzten Monaten durchlaufen?
Wie aus den Ergebnissen des Evaluierungssets hervorgeht, weist die aktuelle Version von Janus-Pro-1B eine Verbesserung von ca. 10% bis 20% in den Ergebnissen der verschiedenen Evaluierungssets im Vergleich zum vorherigen Janus auf. Janus-Pro-7B hat die höchste Verbesserung von etwa 45% im Vergleich zu Janus, nachdem die Anzahl der Parameter erweitert wurde.

Was die Einzelheiten der Ausbildung betrifft, so heißt es in dem technischen Bericht, dass die aktuelle Version von Janus-Pro im Vergleich zum vorherigen Janus-Modell die entkoppelte Kernarchitektur beibehält und zusätzlich folgende Neuerungen aufweist Parametergröße, Trainingsstrategie und Trainingsdaten.
Schauen wir uns zunächst die Parameter an.
Die erste Version von Janus hatte nur 1,3B Parameter, und die aktuelle Version von Pro enthält Modelle mit 1B und 7B Parametern.
Diese beiden Größen spiegeln die Skalierbarkeit der Janus-Architektur wider. Das Modell 1B, das am leichtesten ist, wurde bereits von externen Nutzern für die Ausführung im Browser mit WebGPU verwendet.
Außerdem gibt es die Ausbildungsstrategie.
In Übereinstimmung mit der Einteilung der Ausbildungsphasen in Janus hat das Janus Pro insgesamt drei Ausbildungsphasen, die in diesem Papier direkt in Phase I, Phase II und Phase III unterteilt werden.
Unter Beibehaltung der grundlegenden Schulungsideen und -ziele jeder Phase hat Janus-Pro Verbesserungen bei der Schulungsdauer und den Schulungsdaten in den drei Phasen vorgenommen. Im Folgenden werden die spezifischen Verbesserungen in den drei Phasen beschrieben:
Stufe I - Längere Ausbildungszeit
Im Vergleich zu Janus hat Janus-Pro die Trainingszeit in Phase I verlängert, insbesondere beim Training von Adaptern und Bildköpfen im visuellen Teil. Das bedeutet, dass für das Erlernen der visuellen Merkmale mehr Trainingszeit zur Verfügung steht, und es ist zu hoffen, dass das Modell die detaillierten Merkmale von Bildern (z. B. die Zuordnung von Pixeln zur Semantik) vollständig verstehen kann.
Diese erweiterte Ausbildung trägt dazu bei, dass die Ausbildung des visuellen Teils nicht durch andere Module gestört wird.
Stufe II - Entfernen von ImageNet-Daten und Hinzufügen von multimodalen Daten
In Phase II wurde Janus zuvor mit PixArt referenziert und in zwei Teilen trainiert. Der erste Teil wurde mit dem ImageNet-Datensatz für die Bildklassifikationsaufgabe trainiert, der zweite Teil mit regulären Text-Bild-Daten. Etwa zwei Drittel der Zeit in Phase II wurde für das Training des ersten Teils verwendet.
Bei Janus-Pro entfällt das ImageNet-Training in Phase II. Dadurch kann sich das Modell in Phase II des Trainings auf Text-Bild-Daten konzentrieren. Den experimentellen Ergebnissen zufolge kann dies die Nutzung von Text-Bild-Daten erheblich verbessern.
Neben der Anpassung des Trainingsmethoden-Designs ist der in Stufe II verwendete Trainingsdatensatz nicht mehr auf eine Einzelbild-Klassifikationsaufgabe beschränkt, sondern umfasst auch mehr andere Arten von multimodalen Daten, wie z.B. Bildbeschreibungen und Dialoge, für das gemeinsame Training.
Stufe III - Optimierung des Datenverhältnisses
In Phase III des Trainings passt Janus-Pro das Verhältnis der verschiedenen Arten von Trainingsdaten an.
Bisher betrug das Verhältnis von multimodalen Verstehensdaten, reinen Textdaten und Text-zu-Bild-Daten in den von Janus in Stufe III verwendeten Trainingsdaten 7:3:10. Janus-Pro reduziert das Verhältnis der beiden letztgenannten Datentypen und passt das Verhältnis der drei Datentypen auf 5:1:4 an, d.h. es wird mehr Wert auf die multimodale Verstehensaufgabe gelegt.
Schauen wir uns die Trainingsdaten an.
Im Vergleich zu Janus erhöht Janus-Pro dieses Mal die Menge an hochwertigen synthetische Daten.
Es erweitert die Menge und Vielfalt der Trainingsdaten für multimodales Verstehen und Bilderzeugung.
Erweiterung der multimodalen Verständnisdaten:
Janus-Pro bezieht sich beim Training auf den DeepSeek-VL2-Datensatz und fügt etwa 90 Millionen zusätzliche Datenpunkte hinzu, darunter nicht nur Bildbeschreibungsdatensätze, sondern auch Datensätze mit komplexen Szenen wie Tabellen, Diagramme und Dokumente.
In der Phase der überwachten Feinabstimmung (Phase III) werden weiterhin Datensätze hinzugefügt, die sich auf das Verständnis von MEME und die Verbesserung der Dialogerfahrung (einschließlich des chinesischen Dialogs) beziehen.
Erweiterung der Daten zur visuellen Erzeugung:
Die ursprünglichen realen Daten hatten eine schlechte Qualität und ein hohes Maß an Rauschen, was dazu führte, dass das Modell instabile Ergebnisse und Bilder von unzureichender ästhetischer Qualität bei Text-Bild-Aufgaben produzierte.
Janus-Pro fügte der Trainingsphase etwa 72 Millionen neue hochästhetische synthetische Daten hinzu, wodurch das Verhältnis von realen Daten zu synthetischen Daten in der Pre-Trainingsphase auf 1:1 gebracht wurde.
Die Eingabeaufforderungen für die synthetischen Daten stammen alle aus öffentlichen Quellen. Experimente haben gezeigt, dass die Hinzufügung dieser Daten die Konvergenz des Modells beschleunigt und die erzeugten Bilder eine deutliche Verbesserung der Stabilität und visuellen Schönheit aufweisen.
Die Fortsetzung einer Effizienzrevolution?
Insgesamt hat DeepSeek mit dieser Version die Effizienzrevolution bei visuellen Modellen eingeleitet.
Im Gegensatz zu visuellen Modellen, die sich auf eine einzige Funktion konzentrieren, oder multimodalen Modellen, die eine bestimmte Aufgabe bevorzugen, gleicht Janus-Pro die Auswirkungen der beiden Hauptaufgaben der Bilderzeugung und des multimodalen Verstehens in ein und demselben Modell aus.
Außerdem schlug es trotz seiner geringen Parameter OpenAI DALL-E 3 und SD3-Medium in der Bewertung.
Das Unternehmen muss nur noch ein Modell einsetzen, um die beiden Funktionen der Bilderzeugung und des Bildverständnisses direkt zu implementieren. In Verbindung mit einer Größe von nur 7B sind die Schwierigkeit und die Kosten der Bereitstellung viel geringer.
In Verbindung mit den früheren Veröffentlichungen von R1 und V3 stellt DeepSeek die bestehenden Spielregeln mit "kompakte architektonische Innovation, leichtgewichtige Modelle, Open-Source-Modelle und extrem niedrige Ausbildungskosten".. Dies ist der Grund für die Panik unter den westlichen Technologiegiganten und sogar an der Wall Street.
Gerade hat Sam Altman, der seit einigen Tagen von der öffentlichen Meinung mitgerissen wird, endlich positiv auf die Informationen über DeepSeek auf X reagiert - er lobte R1 und sagte, dass OpenAI einige Ankündigungen machen wird.