春节前夕,DeepSeek-R1机型正式发布。它采用纯粹的 RL 架构,汲取了 CoT 的伟大创新,性能超过了 ChatGPT 数学、代码和逻辑推理。
此外,DeepSeek 的开源模型权重、低训练成本和低廉的 API 价格也让它在互联网上大受欢迎,甚至导致英伟达和 ASML 的股价一度暴跌。
在爆红的同时,DeepSeek还发布了多模态大模型Janus(杰纳斯)的升级版Janus-Pro,它继承了上一代多模态理解和生成的统一架构,优化了训练策略,扩展了训练数据和模型规模,带来了更强的性能。

Janus-Pro
Janus-Pro 是一种统一的多模态语言模型(MLLM),可以同时处理多模态理解任务和生成任务,即既能理解图片内容,又能生成文本。
它将多模态理解和生成的视觉编码器分离开来(即图像理解的输入和图像生成的输入和输出使用不同的标记化器),并使用统一的自回归变换器进行处理。
作为一种先进的多模态理解和生成模型,它是之前 Janus 模型的升级版。
在罗马神话中,雅努斯(Janus)是一位双面守护神,象征着矛盾和过渡。他有两张面孔,这也表明雅努斯模型可以理解和生成图像,这非常贴切。那么,PRO 究竟升级了什么呢?
Janus 作为 1.3B 的小模型,与其说是正式版本,不如说是预览版本。它探索了统一的多模态理解和生成,但也存在很多问题,如图像生成效果不稳定、与用户说明偏差较大、细节不足等。
专业版优化了训练策略,增加了训练数据集,并在提供 1B 模型的同时提供了更大的模型(7B)供选择。
模型结构
Jaus-Pro 和 Janus 在模型结构方面完全相同。(仅需 13 亿美元!Janus 将多模态理解和生成统一起来)
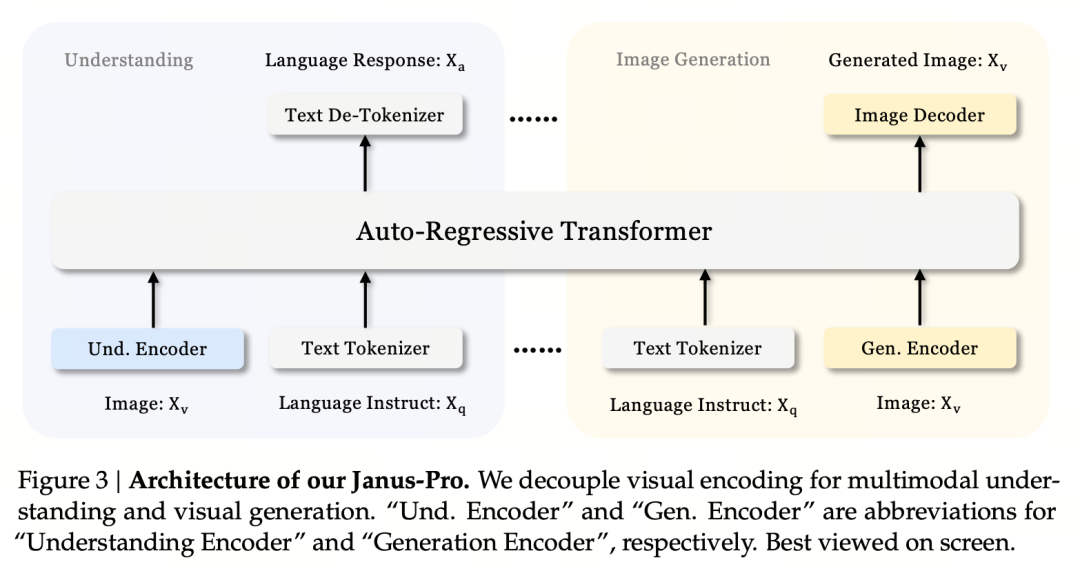
其核心设计原则是解耦视觉编码,以支持多模态理解和生成。Janus-Pro 对原始图像/文本输入分别进行编码,提取高维特征,并通过统一的自回归变换器进行处理。
多模态图像理解使用 SigLIP 对图像特征进行编码(上图中的蓝色编码器),而生成任务则使用 VQ 标记器对图像进行离散化(上图中的黄色编码器)。最后,所有特征序列都输入到 LLM 进行处理
培训战略
在训练策略方面,Janus-Pro 做了更多改进。旧版 Janus 采用的是三阶段训练策略,其中第一阶段训练输入适配器和图像生成头进行图像理解和图像生成,第二阶段进行统一的预训练,第三阶段在此基础上对理解编码器进行微调(Janus 的训练策略如下图所示)。(Janus 的训练策略如下图所示)。
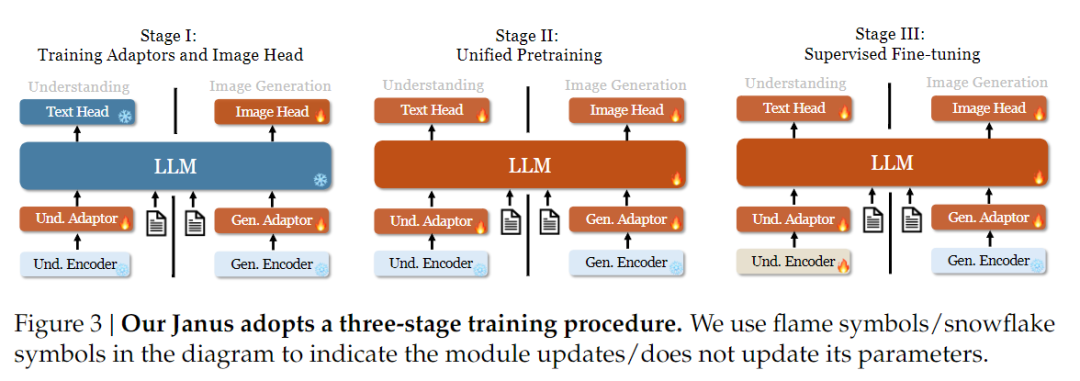
不过,这种策略在第二阶段使用 PixArt 方法将文本到图像的生成训练拆分开来,导致计算效率较低。
为此,我们延长了第一阶段的训练时间,并增加了使用 ImageNet 数据的训练,从而使模型能够在固定 LLM 参数的情况下有效地建立像素依赖关系模型。在第二阶段,我们舍弃了 ImageNet 数据,直接使用文本图像对数据进行训练,从而提高了训练效率。此外,我们还调整了第三阶段的数据比例(多模态:纯文本:视觉语义图数据从 7:3:10 调整为 5:1:4),在保持视觉生成能力的同时提高了多模态理解能力。
训练数据缩放
Janus-Pro 还能在多模态理解和视觉生成方面扩展 Janus 的训练数据。
多模态理解:第二阶段预训练数据基于 DeepSeek-VL2,包含约 9000 万个新样本,包括图像标题数据(如 YFCC)以及表格、图表和文档理解数据(如 Docmatix)。
第三阶段的监督微调阶段进一步引入了 MEME 理解、中文对话数据等,以提高模型的多任务处理性能和对话能力。
视觉生成:以前的版本使用的是低质量和高噪音的真实数据,这影响了文本生成图像的稳定性和美观性。
Janus-Pro 引入了约 7200 万个合成美学数据,使真实数据与合成数据的比例达到 1:1。实验表明,合成数据可加速模型收敛,并显著提高生成图像的稳定性和美学质量。
模型缩放
Janus Pro 将模型大小扩展到了 7B,而 Janus 的上一版本使用了 1.5B 的 DeepSeek-LLM 来验证解耦视觉编码的有效性。实验表明,更大的 LLM 能显著加快多模态理解和视觉生成的收敛速度,进一步验证了该方法的强大可扩展性。

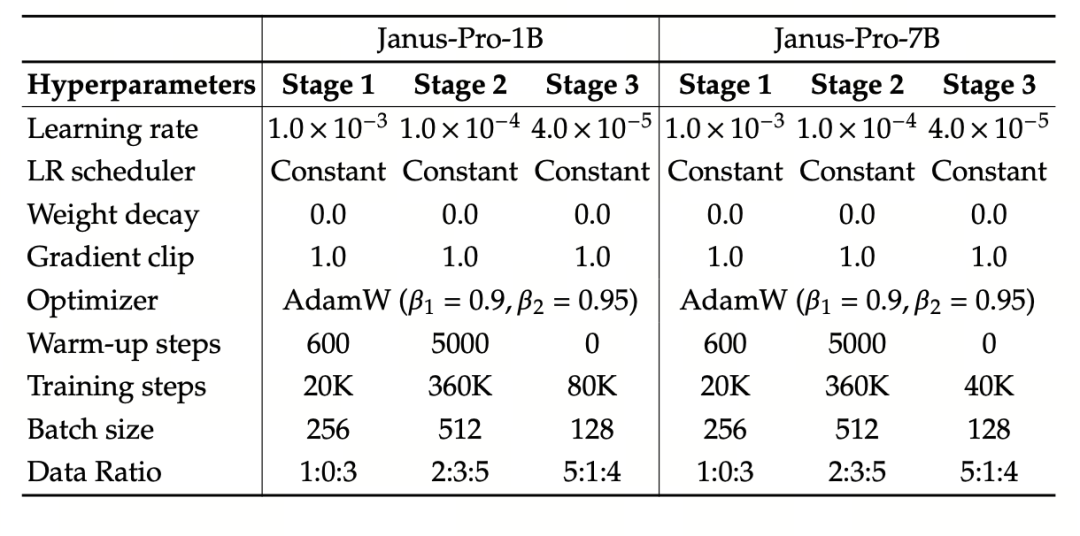
实验使用 DeepSeek-LLM(1.5B 和 7B,支持最大 4096 个序列)作为基本语言模型。在多模态理解任务中,使用 SigLIP-Large-Patch16-384 作为视觉编码器,编码器的字典大小为 16384,图像下采样倍数为 16,理解适配器和生成适配器均为双层 MLP。
第二阶段训练使用 270K 提前停止策略,所有图像统一调整为 384×384 分辨率,并使用序列打包提高训练效率。Janus-Pro 采用 HAI-LLM 进行训练和评估。1.5B/7B 版本分别在 16/32 个节点(每个节点 8×Nvidia A100 40GB)上训练了 9/14 天。
模型评估
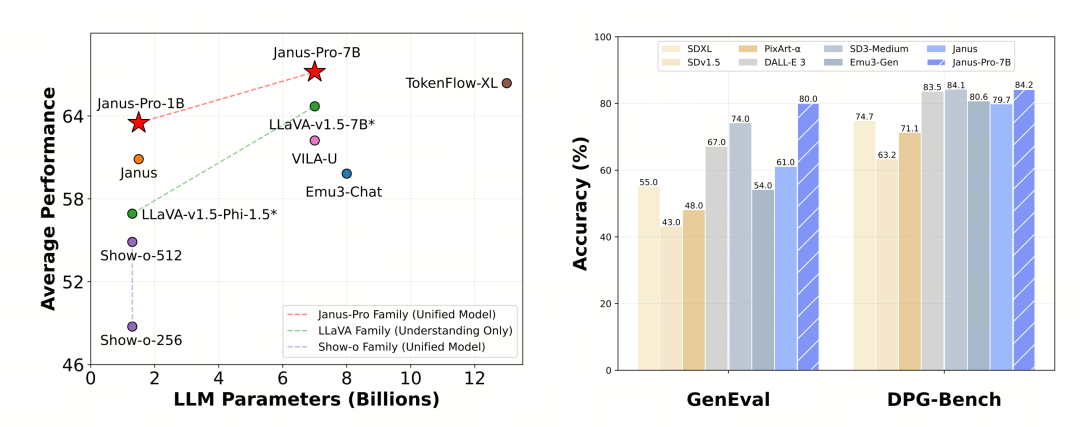
Janus-Pro 在多模态理解和生成方面分别进行了评估。总体而言,其理解能力可能稍弱,但在同等规模的开源模型中算是优秀的(估计主要受限于固定的输入分辨率和 OCR 功能)。
Janus-Pro-7B 在 MMBench 基准测试中获得了 79.2 分,接近一线开源机型的水平(相同大小的 InternVL2.5 和 Qwen2-VL 约为 82 分)。不过,与上一代 Janus 相比,它有了很好的改进。
在图像生成方面,Janus-Pro 与上一代产品相比有了更显著的改进,在开源机型中属于优秀水平。Janus-Pro 在 GenEval 基准测试中的得分(0.80)也超过了 DALL-E 3(0.67)和 Stable Diffusion 3 Medium(0.74)等机型。