DeepSeek ha actualizado su sitio web.
En las primeras horas de la Nochevieja, DeepSeek anunció repentinamente en GitHub que el espacio del proyecto Janus había abierto el código fuente del modelo Janus-Pro y el informe técnico.
En primer lugar, destaquemos algunos puntos clave:
- En Modelo Janus-Pro lanzado esta vez es un modelo multimodal que puede realizar simultáneamente tareas de comprensión multimodal y de generación de imágenes. Cuenta con un total de dos versiones de parámetros, Janus-Pro-1B y Janus-Pro-7B.
- La principal innovación de Janus-Pro es desacoplar comprensión y generación multimodal, dos tareas diferentes. Esto permite que estas dos tareas se completen de manera eficiente en el mismo modelo.
- Janus-Pro es coherente con la arquitectura del modelo Janus presentado por DeepSeek el pasado mes de octubre, pero en aquel momento Janus no tenía mucho volumen. El Dr. Charles, experto en algoritmos en el campo de la visión, nos dijo que el Janus anterior era "mediocre" y "no tan bueno como el modelo lingüístico de DeepSeek".

Pretende resolver el difícil problema de la industria: equilibrar la comprensión multimodal y la generación de imágenes
Según la presentación oficial de DeepSeek, Janus-Pro no sólo puede entender imágenes, extraer y comprender el texto de las imágenes, sino también generar imágenes al mismo tiempo.
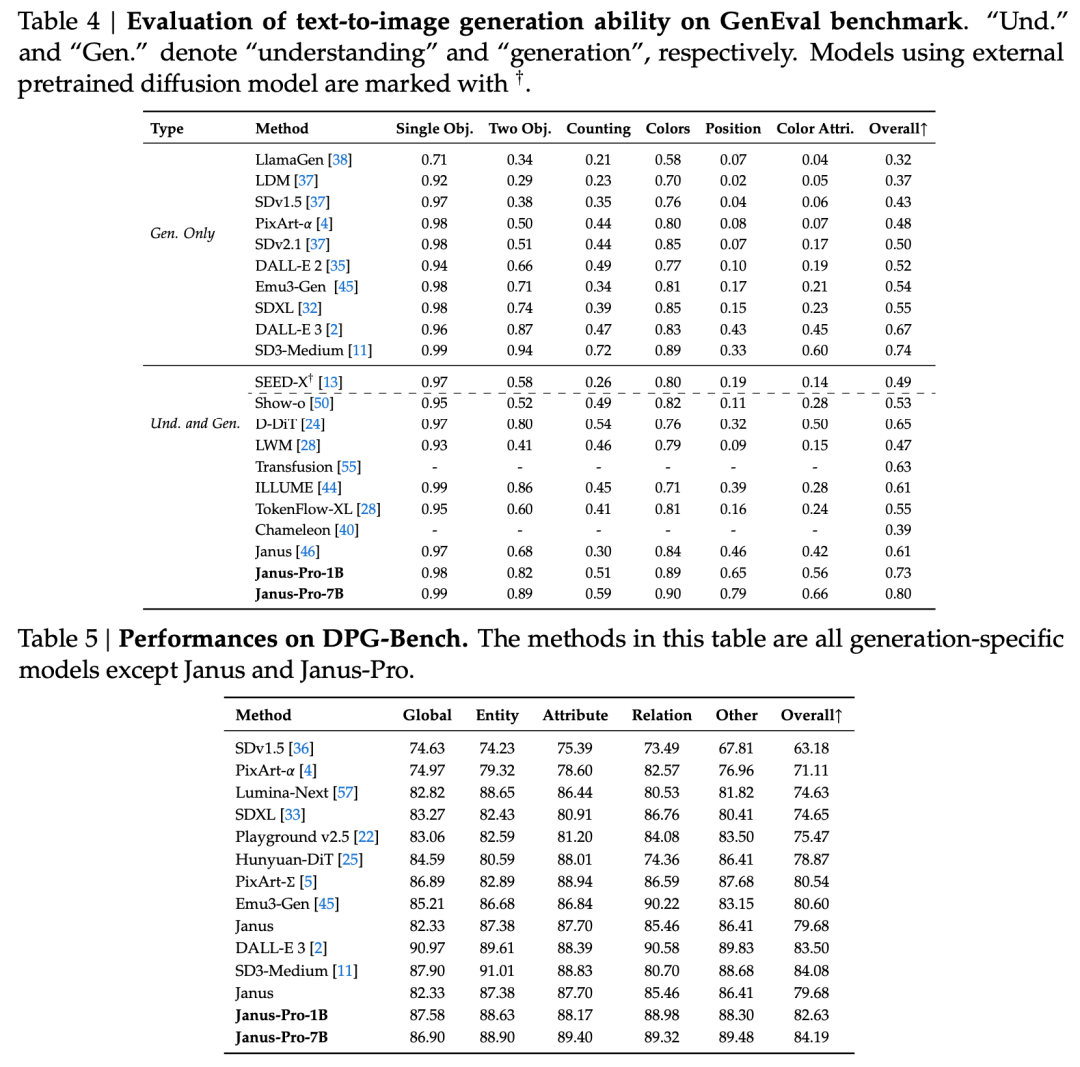
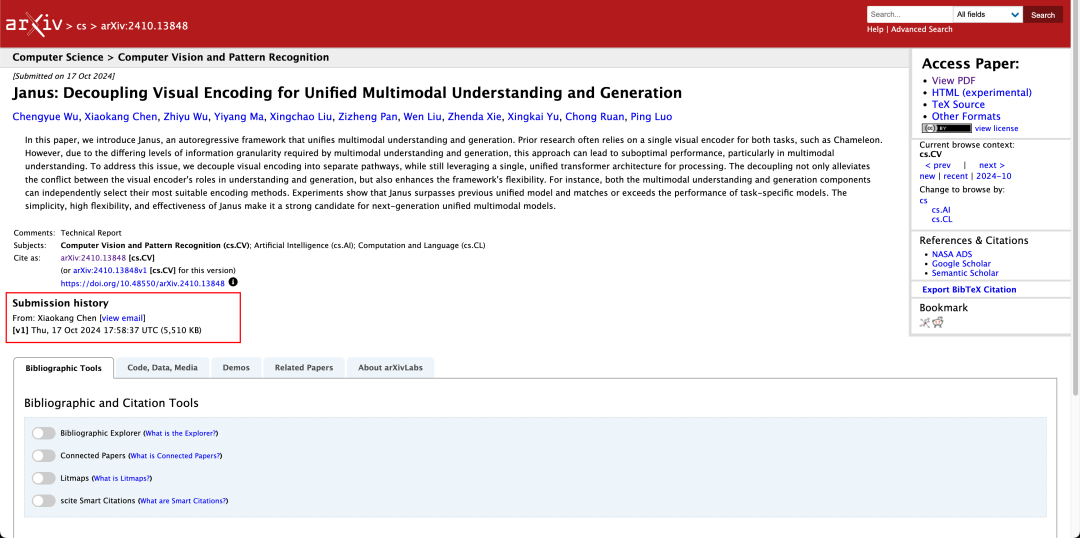
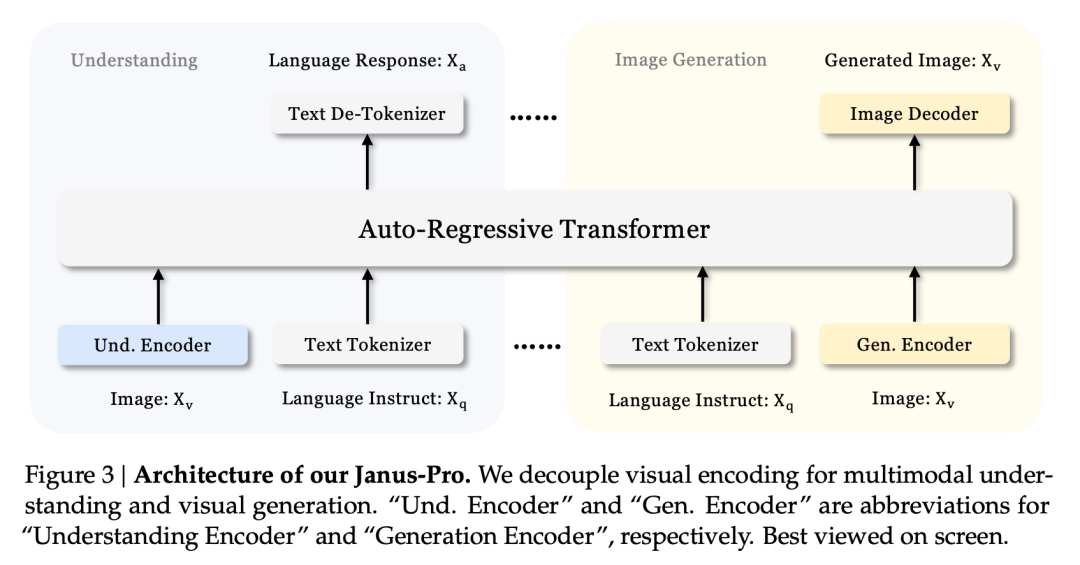
El informe técnico menciona que, en comparación con otros modelos del mismo tipo y orden de magnitud, las puntuaciones de Janus-Pro-7B en los conjuntos de pruebas GenEval y DPG-Bench superan las de otros modelos como SD3-Medium y DALL-E 3.
El funcionario también da ejemplos 👇:
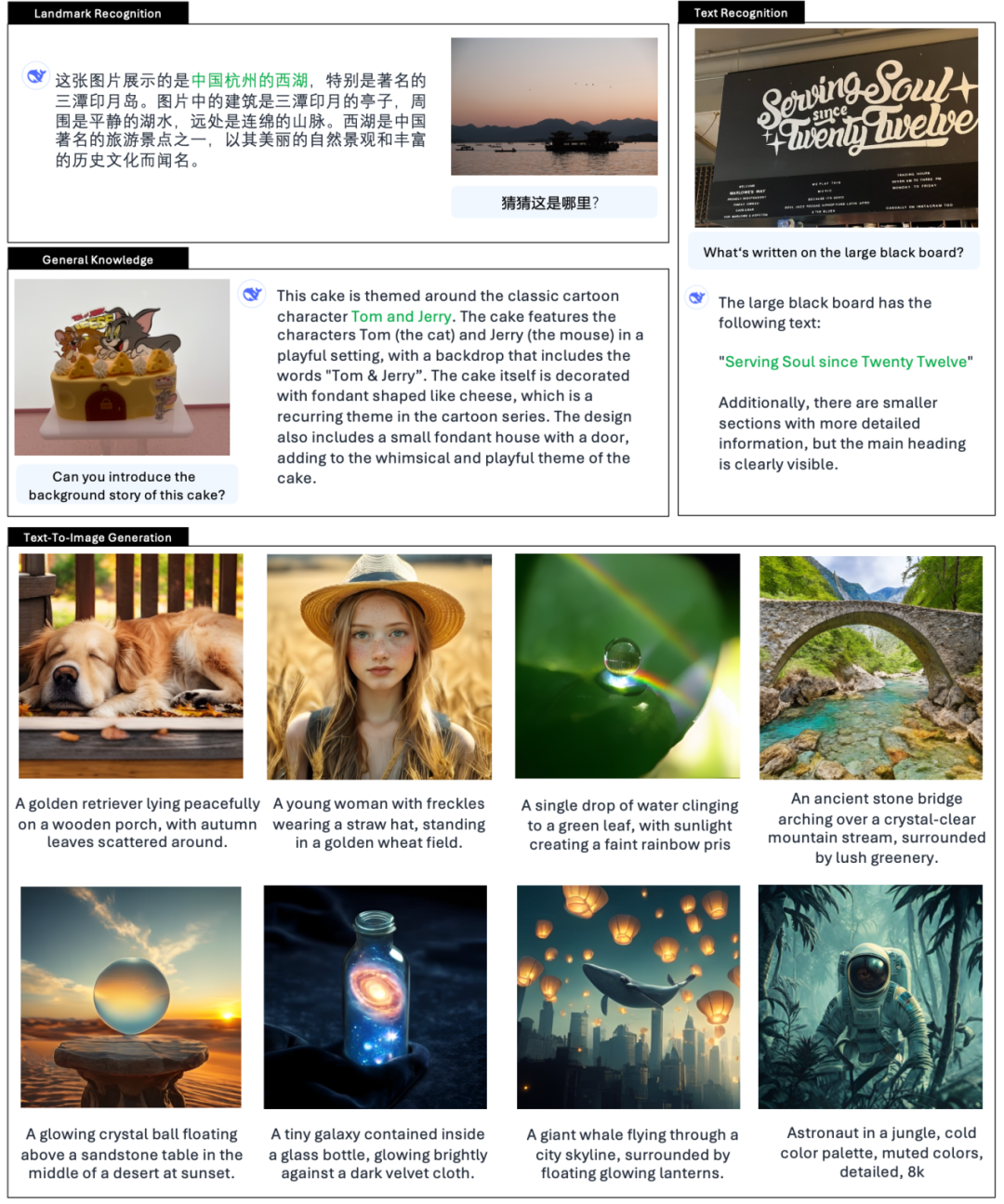
También hay muchos internautas en X probando las nuevas funciones.

Pero también hay caídas ocasionales.
Consultando los documentos técnicos sobre DeepSeek, descubrimos que Janus Pro es una optimización basada en Janus, que se lanzó hace tres meses.
La principal innovación de esta serie de modelos es desacoplar las tareas de comprensión visual de las tareas de generación visual, de modo que se puedan equilibrar los efectos de ambas tareas.
No es infrecuente que un modelo realice la comprensión y la generación multimodal al mismo tiempo. D-DiT y TokenFlow-XL tienen esta capacidad.
Sin embargo, lo característico de Janus es que Al desacoplar el procesamiento, un modelo capaz de realizar la comprensión y la generación multimodales equilibra la eficacia de las dos tareas.
Equilibrar la eficacia de ambas tareas es un problema difícil en la industria. Antes se pensaba en utilizar el mismo codificador para aplicar la comprensión y la generación multimodales en la medida de lo posible.
Las ventajas de este enfoque son una arquitectura sencilla, la ausencia de despliegues redundantes y una alineación con los modelos textuales (que también utilizan los mismos métodos para lograr la generación y comprensión de textos). Otro argumento es que esta fusión de múltiples capacidades puede conducir a un cierto grado de emergencia.
Sin embargo, de hecho, tras fusionar la generación y la comprensión, las dos tareas entrarán en conflicto: la comprensión de imágenes requiere que el modelo abstraiga en altas dimensiones y extraiga la semántica central de la imagen, que está sesgada hacia lo macroscópico. La generación de imágenes, por su parte, se centra en la expresión y generación de detalles locales a nivel de píxel.
La práctica habitual del sector es dar prioridad a las capacidades de generación de imágenes. Esto da lugar a modelos multimodales que pueden generar imágenes de mayor calidad, pero los resultados de la comprensión de imágenes suelen ser mediocres.
La arquitectura desacoplada de Janus y la estrategia de formación optimizada de Janus-Pro
La arquitectura desacoplada de Janus permite al modelo equilibrar las tareas de comprensión y generación por sí solo.
Según los resultados del informe técnico oficial, tanto en comprensión multimodal como en generación de imágenes, Janus-Pro-7B obtiene buenos resultados en múltiples conjuntos de pruebas.

Para una comprensión multimodal, Janus-Pro-7B logró el primer puesto en cuatro de los siete conjuntos de datos de evaluación, y el segundo en los tres restantes, ligeramente por detrás del modelo mejor clasificado.
Para generar imágenes, Janus-Pro-7B logró el primer puesto en la puntuación global de los conjuntos de datos de evaluación GenEval y DPG-Bench.
Este efecto multitarea se debe principalmente a que la serie Janus utiliza dos codificadores visuales para tareas diferentes:
- Comprender el codificador: utilizado para extraer características semánticas en imágenes para tareas de comprensión de imágenes (como preguntas y respuestas sobre imágenes, clasificación visual, etc.).
- Codificador generativo: convierte imágenes en una representación discreta (por ejemplo, utilizando un codificador VQ) para tareas de generación de texto a imagen.
Con esta arquitectura, el modelo puede optimizar de forma independiente el rendimiento de cada codificador, de modo que las tareas de comprensión y generación multimodal puedan alcanzar cada una su mejor rendimiento.
Esta arquitectura desacoplada es común a Janus-Pro y Janus. Entonces, ¿qué iteraciones ha tenido Janus-Pro en los últimos meses?
Como se desprende de los resultados del conjunto de evaluación, la versión actual de Janus-Pro-1B presenta una mejora de entre 10% y 20% en las puntuaciones de los distintos conjuntos de evaluación en comparación con el anterior Janus. Janus-Pro-7B presenta la mayor mejora, de unos 45%, en comparación con Janus tras ampliar el número de parámetros.

En cuanto a los detalles de la formación, el informe técnico afirma que la versión actual de Janus-Pro, en comparación con el modelo anterior de Janus, mantiene el diseño básico de la arquitectura desacoplada y, además, itera sobre tamaño de los parámetros, estrategia de entrenamiento y datos de entrenamiento.
En primer lugar, veamos los parámetros.
La primera versión de Janus sólo tenía 1,3B parámetros, y la versión actual de Pro incluye modelos con 1B y 7B parámetros.
Estos dos tamaños reflejan la escalabilidad de la arquitectura Janus. El modelo 1B, que es el más ligero, ya ha sido utilizado por usuarios externos para ejecutarlo en el navegador mediante WebGPU.
También hay el estrategia de formación.
De acuerdo con la división de las fases de formación de Janus, Janus Pro tiene un total de tres fases de formación, y el documento las divide directamente en Fase I, Fase II y Fase III.
Aunque se mantienen las ideas básicas de formación y los objetivos de formación de cada fase, Janus-Pro ha introducido mejoras en la duración de la formación y en los datos de formación de las tres fases. A continuación se exponen las mejoras específicas en las tres fases:
Etapa I - Mayor tiempo de entrenamiento
En comparación con Janus, Janus-Pro ha ampliado el tiempo de entrenamiento en la Fase I, especialmente en el entrenamiento de adaptadores y cabezales de imagen en la parte visual. Esto significa que se ha dado más tiempo de entrenamiento al aprendizaje de las características visuales, y se espera que el modelo pueda comprender plenamente las características detalladas de las imágenes (como el mapeo de píxel a semántico).
Esta formación ampliada contribuye a que la formación de la parte visual no se vea perturbada por otros módulos.
Fase II - Eliminación de los datos de ImageNet y adición de datos multimodales
En la fase II, Janus se referenció previamente a PixArt y se entrenó en dos partes. La primera parte se entrenó utilizando el conjunto de datos ImageNet para la tarea de clasificación de imágenes, y la segunda parte se entrenó utilizando datos normales de texto a imagen. Aproximadamente dos tercios del tiempo de la fase II se dedicaron al entrenamiento de la primera parte.
Janus-Pro elimina el entrenamiento de ImageNet en la Etapa II. Este diseño permite al modelo centrarse en los datos de texto a imagen durante el entrenamiento de la Etapa II. Según los resultados experimentales, esto puede mejorar significativamente la utilización de los datos de texto a imagen.
Además del ajuste del diseño del método de entrenamiento, el conjunto de datos de entrenamiento utilizado en la Etapa II ya no se limita a una única tarea de clasificación de imágenes, sino que también incluye más otros tipos de datos multimodales, como la descripción de imágenes y el diálogo, para el entrenamiento conjunto.
Etapa III - Optimización de la relación de datos
En la fase III de entrenamiento, Janus-Pro ajusta la proporción de los distintos tipos de datos de entrenamiento.
Anteriormente, la proporción de datos de comprensión multimodal, datos de texto sin formato y datos de texto a imagen en los datos de entrenamiento utilizados por Janus en la Fase III era de 7:3:10. Janus-Pro reduce la proporción de los dos últimos tipos de datos y ajusta la proporción de los tres tipos de datos a 5:1:4, es decir, prestando más atención a la tarea de comprensión multimodal.
Veamos los datos de entrenamiento.
En comparación con Janus, Janus-Pro esta vez aumenta significativamente la cantidad de datos sintéticos.
Amplía la cantidad y variedad de datos de formación para la comprensión multimodal y la generación de imágenes.
Ampliación de los datos de comprensión multimodal:
Janus-Pro hace referencia al conjunto de datos DeepSeek-VL2 durante el entrenamiento y añade unos 90 millones de puntos de datos adicionales, incluyendo no solo conjuntos de datos de descripción de imágenes, sino también conjuntos de datos de escenas complejas como tablas, gráficos y documentos.
Durante la fase de perfeccionamiento supervisado (Fase III), sigue añadiendo conjuntos de datos relacionados con la comprensión de MEME y la mejora de la experiencia de diálogo (incluido el diálogo chino).
Ampliación de los datos de generación visual:
Los datos originales del mundo real eran de mala calidad y presentaban altos niveles de ruido, lo que hacía que el modelo produjera resultados inestables e imágenes de calidad estética insuficiente en tareas de conversión de texto en imagen.
Janus-Pro añadió unos 72 millones de nuevos datos sintéticos de alta estética a la fase de entrenamiento, con lo que la proporción entre datos reales y sintéticos en la fase de preentrenamiento fue de 1:1.
Las indicaciones para los datos sintéticos se tomaron todas de recursos públicos. Los experimentos han demostrado que la adición de estos datos hace que el modelo converja más rápido, y las imágenes generadas presentan mejoras evidentes en cuanto a estabilidad y belleza visual.
¿La continuación de una revolución de la eficiencia?
En general, con esta versión, DeepSeek ha llevado la revolución de la eficiencia a los modelos visuales.
A diferencia de los modelos visuales que se centran en una única función o de los modelos multimodales que favorecen una tarea específica, Janus-Pro equilibra los efectos de las dos tareas principales de generación de imágenes y comprensión multimodal en el mismo modelo.
Además, a pesar de sus pequeños parámetros, superó aOpenAI DALL-E 3 y SD3-Medium en la evaluación.
Extendida hasta el suelo, la empresa sólo necesita desplegar un modelo para aplicar directamente las dos funciones de generación y comprensión de imágenes. Unido a un tamaño de solo 7B, la dificultad y el coste de despliegue son mucho menores.
En relación con los anteriores lanzamientos de R1 y V3, DeepSeek está desafiando las actuales reglas del juego con "innovación arquitectónica compacta, modelos ligeros, modelos de código abierto y costes de formación ultrabajos". Esta es la razón del pánico entre los gigantes tecnológicos occidentales e incluso Wall Street.
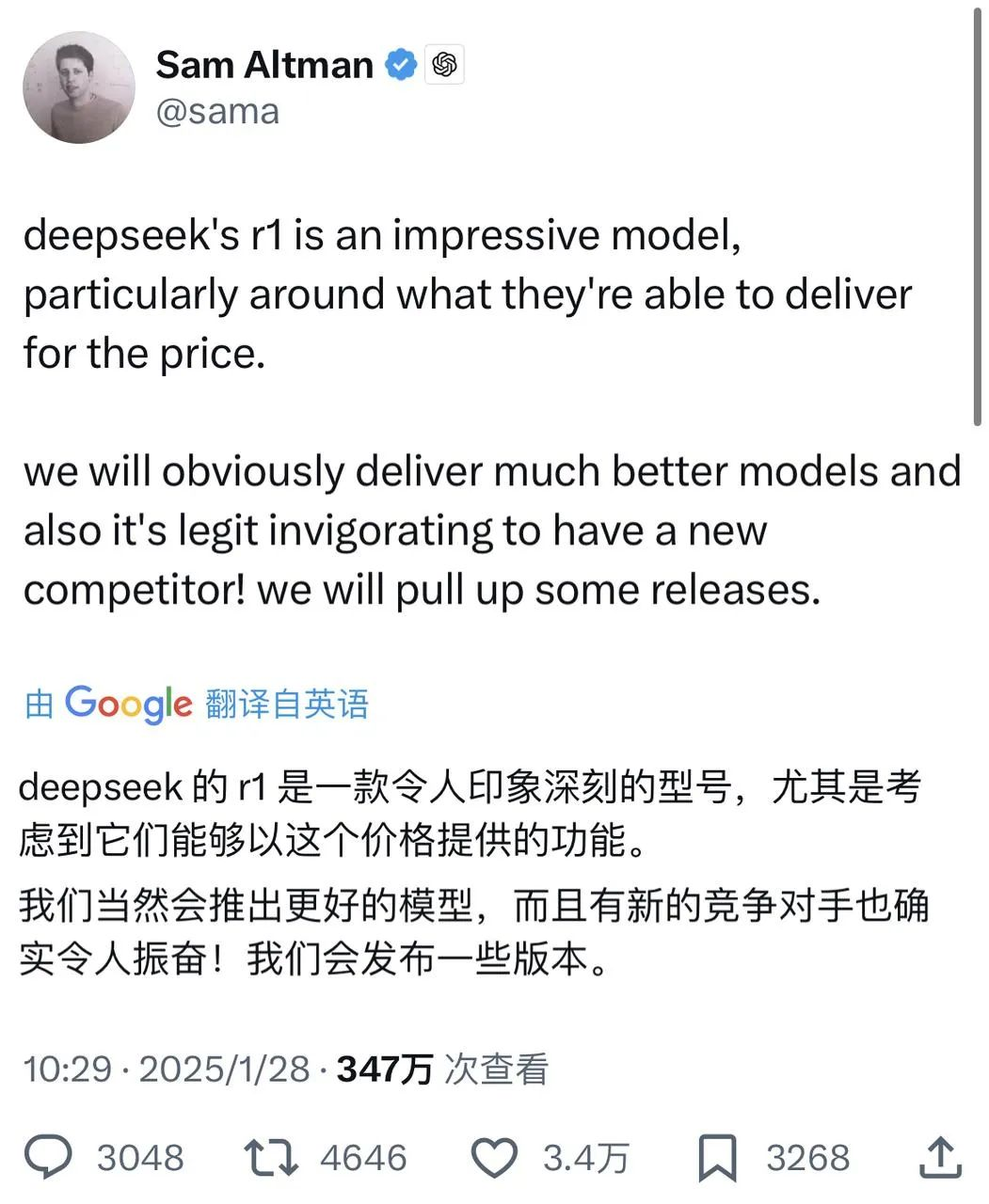
Hace un momento, Sam Altman, que ha sido arrastrado por la opinión pública durante varios días, finalmente respondió positivamente a la información sobre DeepSeek en X: mientras elogiaba a R1, dijo que OpenAI hará algunos anuncios.